Databricks Data + AI Summit 2026 最速レポート Day2
メインキーノート — “Make it real” 主要発表のハイライト

目次
- 1 TL;DR(忙しい人向け要点)
- 2 キーノート概要
- 3 Zerobus Ingest GA — “バス” を消したデータ取り込み
- 4 Genie One GA + OntoRank — “コンテキストのインフラ化”
- 5 Genie エージェント群 — Genie Code と Genie ZeroOps
- 6 Reyden + Lakehouse//RT — リアルタイム分析の壁を超えるエンジン
- 7 Lakehouse + Lakebase → LTAP — OLTPとOLAPを“ストレージ層”で統合
- 8 Unity Catalog × Unity AI Gateway — エージェント時代のガバナンス
- 9 OpenAI 連携拡張 + Greg Brockman 対談
- 10 その他の発表
- 11 提供状況のまとめ(2026年6月17日時点)
- 12 おわりに
こんにちは。ちゅらデータの宮城です。
現地で参加しているDatabricks Data + AI Summit 2026のDay 2メインキーノート(2026年6月16日 8:00 PDT〜)を、発表ハイライト中心の速報レポートとしてお届けします。
なお、同じDay 2キーノートについては、同僚の田中が書いた最速レポート「Databricks Data + AI Summit 2026 最速レポート Day2 Tuesday Keynote 参加記」もよろしければあわせてご覧ください。
本稿は、私自身の目線でもOUTPUTしておきたいと思い、書いたものです。
※英語のヒアリングをもとにしているため、細部の表現に誤りがあるかもしれませんので、その点ご容赦いただけますと幸いです。


TL;DR(忙しい人向け要点)
3時間のキーノートで、Ali Ghodsi氏(CEO)・Reynold Xin氏・Nikita Shamgunov氏・Bilal Aslam氏らから新しい発表が相次ぎました。
今回の主軸は「コンテキストをAIにどう渡すか」と「OLTP・OLAP・リアルタイムをワンプラットフォームで扱うか」の2軸です。
主要発表は、次の7点です。
- ・Genie One がGA
— AIコワーカーが社内データに自然言語で接続。基盤の Genie Ontology と OntoRankアルゴで初回正答率 84.5% - ・Reyden + Lakehouse//RT
— リアルタイム分析用の新エンジン。<10ms・12,000+ QPS、別サービング基盤比16倍速 - ・Lakehouse + Lakebase → LTAP
— OLTP と OLAP をストレージ層で統合する新アーキテクチャ。CDC / ETL / レプリカ不要 - ・Genie ZeroOps
— 自律データオペエージェント。shallow cloneで安全に修正検証してPR提案まで実施 - ・Unity Catalog × Unity AI Gateway 強化
— エージェント乱立時代のガバナンス再強化 - ・Zerobus Ingest がGA
— Kafka 100% wire-compatibleのフルマネージドサービス - ・OpenAI 連携拡張
— CodexをAI Gateway経由で利用可、Genie × Codexネイティブ連携
Ali氏のステージ発表によれば、登録10万人超・174カ国・現地参加31,309名で、Databricks社自身が “the World’s Largest Data and AI Conference” と称するほどの規模となっていました。
キーノート概要
主要登壇者(キーノートで大型発表を行ったDatabricks側スピーカー)
- ・Ali Ghodsi(CEO・共同創業者)
— 全体総括 / Genie One - ・Reynold Xin(共同創業者・Chief Architect)
— Reyden / Lakehouse//RT / LTAP - ・Nikita Shamgunov(VP, Engineering)
— Lakebase - ・Bilal Aslam(Sr. Director, PM)
— Lakeflow / Genie ZeroOps
加えて、デモはElise Georis氏(Databricks)が実演、ゲストとしてはMagesh Bagavathi 氏(PepsiCo)、Federico Cohen-Freue 氏(Mastercard)、Greg Brockman氏(OpenAI)が登壇されました(※)。
Databricks側からは、共同創業者のArsalan Tavakoli-Shiraji氏も対談に参加しました。
※登壇者の肩書は、Databricks 公式 Summit 2026 スピーカー一覧 より
Zerobus Ingest GA — “バス” を消したデータ取り込み
昨年プレビューだったZerobus IngestがGAになりました。Kafkaと100% wire-compatibleなフルマネージドサービスで、「データバス」という独立コンポーネントを別途運用する設計そのものを解体してしまおうという発想です。
あわせてLake Connectのコネクタも100種類以上に拡大しており、Salesforce / Workday / Meta / Google Analytics といったソースからのストリーミング・バッチ取り込みが同じプラットフォーム内でカバーできる、と説明されていました。
“ZeroBus. As the name implies, you don’t need a bus anymore for the data infrastructure.”
訳:ZeroBusは、その名のとおり、データ基盤に “バス” がもう要らないことを意味する。
Kafka運用は業界的に重いと言われているので、その負担をマネージド側に寄せられるなら、運用観点でのインパクトは大きいと感じます。
一方で、“バスを消す” 設計は、同じストリームをDatabricks以外にもfan-outしたいユースケースとは相性が悪そうなので、既存Kafkaとの併用設計を残せるかどうかは導入時の論点になりそうです。コスト面でも、Kafka自前運用(人件費含む)と Zerobusのマネージド従量課金がどこでクロスオーバーするのかはワークロードによって大きく変わりそうなので、スループット試算と単価は早めに比較しておきたいところです。
公式情報: Unifying Data and Governance in the Agentic Era
Genie One GA + OntoRank — “コンテキストのインフラ化”
本日GAとなったGenie Oneは、組織内のあらゆるデータとアプリに自然言語で接続できる「AIコワーカー」です。
今回特に強調されていたのが、基盤のGenie Ontologyと、その重み付けアルゴリズムOntoRankでした。CEO自ら「ダサい名前ですが」と苦笑しながら紹介していたのが印象的でしたが、中身はPageRank的なロジックで、組織内の情報源に対して権威性を重み付けし、「競合する定義の衝突」を自動で解決する仕組みと紹介されていました(具体的な重み付けの観点については、関連セッションを聴講した同僚の亀井の記事に詳しくまとめられています)。
数字も強気で、Databricksの内部テストでは初回正答率が84.5%(競合の最強コーディングエージェントは52.4%)だったそうです。
差分が30ポイント超というのは、AIエージェントの精度議論を一段引き上げる水準です。ただし、テストセットの作成主体はDatabricks社自身であり、第三者による独立検証は、まだ公開されていません。
額面で受け取るのではなく、自社の代表的な質問パターンで再現できるかをまず確かめるのがよいと思っています。
Teams / Slack / Android / iOS / MCP アプリ対応、加えてユーザー当たり月 $10 相当の DBU(Databricks Unit)が無償提供されると発表されました。毎日複数回、Genieに問い合わせをするような使い方だとすぐ枯渇しそうですが、たまにお試しで使う程度であれば足りそうな印象です。試しに触ってみるには、ちょうどよいインセンティブと言えそうです。

事例としてPepsiCoの “Spend Wise” 調達プラットフォームへの組み込みが紹介され、最初の数週間で30,000クエリ / エンゲージメントが発生、30,000+レポートを50ほどのGenieコンソールに集約する構想も語られました。
個人的に気になっているのは、「Genieが間違えたときの責任分界をどう設計するか」というあたりです。
いきなり全社展開するよりは、まずは社内ヘルプやナレッジ検索のような限定ユースケースから入って、組織のアクセス権限とGenie側の権限を整理しながら広げていく、というのが現実的な進め方かなと感じています。
一方で、OntoRankの “競合する定義の自動衝突解決” は、企業内で乱立しがちなKPI定義の問題に対して効きそうで、期待している部分です。
コスト面については、本格的に業務へ組み込んだ場合の従量課金体系・大量問い合わせ時の上限・ピーク時単価の見え方あたりは、しっかり確認しておきたいところです。
「PoCでは無料だったが、本番で予算オーバーになった」というのはAI系プロジェクトでよく聞く話なので、想定QPSとトークン消費パターンは早めにモデル化したいですね。
【記事のご紹介】
Genie Ontologyと関連発表のCustomerLake(エージェント型 CDP)の詳細は弊社・亀井のレポートをあわせてご覧ください。
Databricks Data + AI Summit 2026 最速レポート Day2 Keynoteで注目の新機能「Genie Ontology」「CustomerLake」を紹介
公式情報:
- ・Introducing Genie One, Genie Agents, and Genie Ontology(公式ブログ)
- ・Databricks Launches Genie One(プレスリリース)
Genie エージェント群 — Genie Code と Genie ZeroOps
Genie Oneは単体ではなく、10エージェント体制の一部として紹介されました。
主要3つは、Genie One・Genie Code(データエンジニアリング / ML / コーディング特化)・Genie ZeroOps(自律データオペエージェント)です。

Bilal Aslam氏のセッションでは、データ運用の負荷(保守に時間の半分以上、月数十時間規模のダウンタイム、といった数字)が示されていました。
私も昔は、運用保守を担当していたので、ここの苦労は肌感としてわかるところがあり、ZeroOpsは気になっています。
Unity Catalogのlineageと既存権限を活用しながら、異常検知用MLモデルを自律的に組み立て、サブエージェント群で根本原因を分析、shallow clone(本番データのブランチ)で安全に修正を検証し、最終的にPRとして人間に提案する、という一連の流れが、具体的に示されました。
“It walks the lineage to find the root cause, creates a fix, then uses a shallow clone — a branch of production data — to verify the fix without exposing production data to risk.”
「保守時間を50% 削減」という謳い文句よりも、shallow clone + PR提案という具体的フローの方に重みを感じます。
本番データに触れずに自動検証できる仕掛けは、これまで「テスト環境構築コストが見合わない」と諦めていた自動修復を、現実的な選択肢に押し上げる可能性があります。一方で、PR提案を機械的に流すと「AIレビュー疲れ」が新しい運用課題になりそうで、PRの品質(=どれだけ自信のある提案だけを上げてくるか)のチューニングが導入の鍵になると考えています。
Reyden + Lakehouse//RT — リアルタイム分析の壁を超えるエンジン
Reynold Xin氏が発表した新エンジン Reyden(レイデン:命名は “Reynold’s Dream Engine” の略。社内チームの呼称が定着したもので、Matei Zaharia氏もX で同じ綴りを使っています)、そしてそれを搭載した、新DWH製品が Lakehouse //RT(スラッシュ2つが公式の表記)です。2026年6月17日より、ベータ版が提供開始されます。
Reynold氏が問題提起として示したスライドが、業界全体の「常識」を要約しています。

これまでは「データウェアハウスにあるデータを、低レイテンシで提供するには別レイヤ(ClickHouse / Pinot 等)へコピーするしかない」というのが業界の常識でした。
その代償として “データの鮮度低下”・“ユースケースの限定”・“ガバナンスの分断” を抱えてきた、という整理です。
これを覆すのがReydenです。
- ・スループット12,000+ QPS(governed Delta / Iceberg テーブル上)
- ・レイテンシ小規模データで <10ms、大規模で <100ms
- ・競合の汎用DWHは160QPS付近で壁、インタラクティブDWHも300QPS 付近で壁
- ・別の独立リアルタイム配信スタックと比較して、最大16倍高速化
- ・完全非同期実行モデルで、スループットを上げてもレイテンシが劣化しない設計
設計の核は、数兆件のクエリトレースを機械学習で分析し、ランタイムで最適なアルゴリズムを動的に選択する仕組みです。
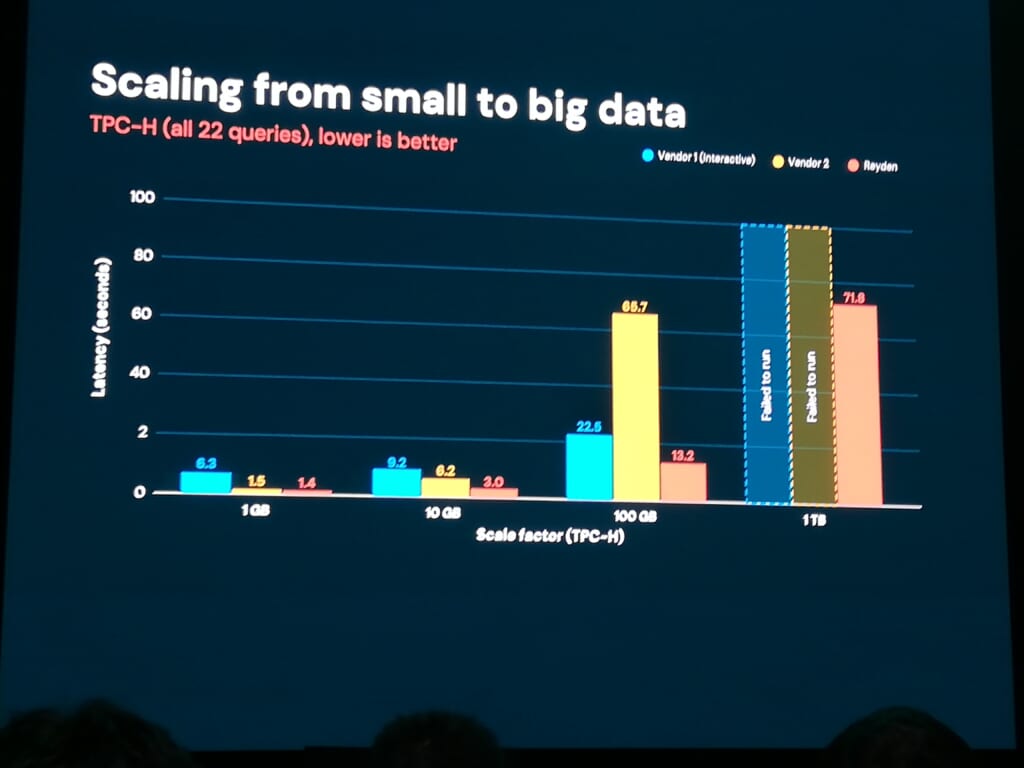
一方で、競合Vendor1(インタラクティブDWH)とVendor2は、1TBで “Failed to run”。100GBスケールでもReydenは13.2秒に対し、Vendor2は65.7 秒
エネルギー業界のデータプラットフォームベンダーEnverusが設計パートナーとして11ワークロードで検証したところ、既存スタック比で平均60倍、長時間クエリでは最大100倍の高速化を確認した、と報告されました。
Director of Data InfrastructureのPaul Lamb氏の声明スライドも壇上に映し出されました(2.7PB のデータ、$500B+の年間トランザクション規模)。

今回のキーノートで最もインパクトを感じた発表です。
「オープンフォーマット上で本当に低レイテンシが出るのか」は、数年来の問いで、これまでLakehouse派は「秒オーダー、リアルタイム系は別エンジン」という妥協を受け入れてきました。それをDelta / Icebergのままで、データのコピーなしに <10ms に押し込めているのなら、別サービング基盤を持つ必然性が消えます。
ただし、Betaであること、公開ベンチがEnverus1社 + TPCベンチの結果に依存している点、そして「16倍」の比較対象がどの製品との比較なのかが明示されていない点は、冷静に受け止めるべきです。
独立した第三者ベンチが出るまでは断定的に評価せず、自社の代表ワークロード(クエリ複雑性・カーディナリティ・QPSプロファイル)で再現を試すのが筋だと考えています。コスト面については、Beta段階で価格未公表ですが、これだけの高性能エンジンがLakehouseの標準コンピュート単価で来るとは考えにくく、上位ティア課金になるのではないかと予想しています。
すでにサービング系を別基盤に持っている場合は、その運用コスト + 開発人件費の削減効果と並べて比較してみたい、というのが正直なところです。
公式情報:
– Introducing Lakehouse//RT: Real-Time Performance on a Unified Lakehouse(公式ブログ)
– Databricks Launches Lakehouse//RT(プレスリリース) – Matei Zaharia 氏のXポスト(命名由来)
Lakehouse + Lakebase → LTAP — OLTPとOLAPを“ストレージ層”で統合
今回のキーノートで個人的に「本丸」だと感じたのが、LTAP(Lake Transactional / Analytical Processing。ハイフンなしが公式表記)です。
DatabricksのHTAPに対する答えで、Lakehouse(分析側)と Lakebase(トランザクション側)を統合したアーキテクチャがLTAPです。
Delta Lake / Icebergにトランザクショナルに直接書き込みつつ、PostgreSQL互換も維持するのが特徴で、CDC / ETL / レプリカ・データベースが原理的に不要になります。
基盤となるLakebaseも大きく進化していました。Postgresを再設計し、ストレージとコンピュートを分離。Safekeepers(Paxos合意プロトコル)で低レイテンシ書き込み、Page Servers で低レイテンシ読み込みを担当。インスタンス起動 <500ms、ブランチ生成も同じく500ms 程度、Scale-to-zero、600,000 ops/sec @ <10ms latency(競合のPostgres-as-a-Serviceは 130,000〜350,000 opsで壁)、さらに クロスクラウドDR(AWS ↔ Azure 即時フェイルオーバー) まで提供。プラットフォーム全体では既に、1,200万データベース起動 / 1日を処理しているとのことでした。

“CDC is often called Continuous Data Corruption.”
訳:CDCは、しばしば “継続的なデータ破損” と揶揄される
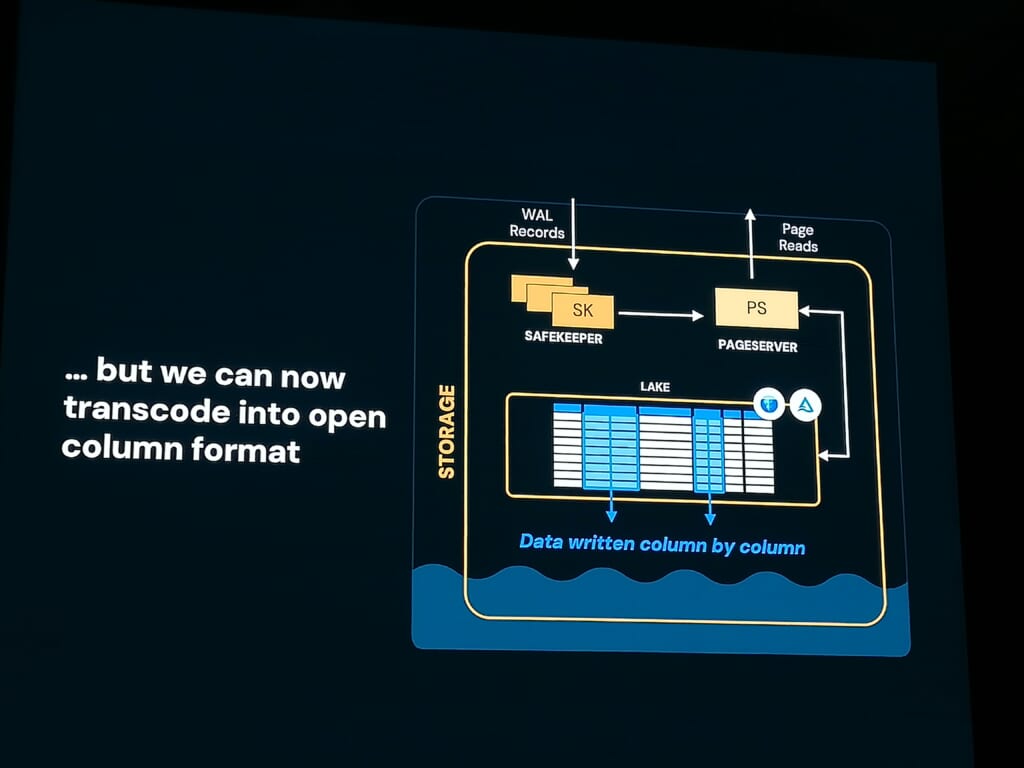
LTAPの要は、ストレージ側のアイドルCPUを使って、Postgres の行指向データをリアルタイムに Parquet 列指向へ変換する点です。
これにより、別パイプラインなしでOLTPデータがLakehouseに “自動的に反映される仕組み” を実現しています。コア変換ライブラリはOSS化されるとのアナウンスもありました。
事例としてMastercardのFederico Cohen-Freue氏が登壇され、80サービスを1プラットフォームに統合、年1,500億 + トランザクション処理、Virtual CFOの提供、そして「コンセプトからスケール対応MVPまで7週間」というスピード感について説明されました。
「ガードレールと分離を最初からアーキテクチャに組み込んだから速かった」というコメントは、後発で導入する側にとって意味深い指摘だと思います。
前節で触れたReydenが「別エンジン不要」だったのに対し、LTAPは「別データベース不要」。両者が揃って初めて、Databricksが主張する “ワンプラットフォーム” が技術的に裏付けられる構造になります。HTAPは長年「holy grail」と言われ、実装は独自フォーマット中心でエコシステムが薄かったジャンルでした。それをオープンフォーマット(Delta / Iceberg)で試みている点が、今回のLTAPの筋の良さです。
ただし、実装する側の視点で読むと注意点も明確です。第一に、PostgreSQL互換の範囲がどこまでかは要確認です。
アプリケーション側がフルのPostgres拡張(PostGIS / TimescaleDB / 各種 FDW など)に依存している場合、そのまま乗らない可能性があります。
第二に、クロスクラウドDRはLakebase側に明示されていましたが、対応する Lakehouse(分析側)のDR 一貫性については、キーノートでは明確に語られていません。
“OLTPはAWS、分析はAzure” のような構成での挙動は、別途確認が必要です。
第三に、既存OLTPの置き換えは依然として重い意思決定で、実務的にはまずエージェントが書き込み先にする「新規ワークロード」からLTAP / Lakebaseを使い始め、徐々に既存ワークロードを乗せていくのが現実解だと考えています。
コスト面では、Lakebaseの単価が既存のPostgres-as-a-Service各種と比べてどうか、Scale-to-zeroの課金粒度、クロスクラウドDRのトラフィック料金あたりがTCO比較で効いてきそうな箇所なので、導入検討時には一度確認しておきたいところです。
公式情報:
– Databricks Launches LTAP(プレスリリース)
– Databricks pitches LTAP as a new foundation for agentic applications(InfoWorld)
– Databricks declares the end of pipelines with a unified platform…(SiliconANGLE)
Unity Catalog × Unity AI Gateway — エージェント時代のガバナンス
組織内では既に、LlamaIndex / LangChain / SaaSベンダー提供エージェントなどが乱立しているような状況になっています。
今回のキーノートでは、この前提でUnity AI Gatewayを全モデル・全エージェントの集約点に据え、コスト管理・監査・ガードレールを一元化する、というメッセージが明示されました。
基盤となるUnity Catalogは引き続きlineageと権限を司り、両者で「データ + AI統合ガバナンス」の建て付けになります。
また、Open Sharingが拡張され、Delta Sharing対象がIcebergも含むようになったことに加え、AI 資産(エージェント・スキル・モデル) まで共有対象になりました。
“自社のAI 資産を、組織境界をまたいで使う” 設計が技術領域において現実的な視野に入ってきましたが、“Iceberg of AI” のような標準フォーマットが存在するわけではないので、ベンダー間ポータビリティは現時点では限定的、という前提は押さえておく必要があります。
「Gateway一元化」の理想と、「現場のチームごとに独自エージェントを構築したい」という力学の摩擦は、ほぼ確実に出ます。
Databricks社自身がそれをどのように運用しているかを知りたい方は、同僚の井田のレポートをご覧ください。コスト面でも、Unity AI Gateway経由のリクエストに対する管理料金やトークン透過課金の体系、ガードレール処理のオーバーヘッドあたりは、エージェントを大量に運用する規模になると効いてきそうなので、事前にキャパシティ試算はしておきたいなと感じました。
【記事のご紹介】
同僚の井田がDatabricks社内チームによる 「How Databricks Ships AI Safely」 と 「Agentic Admins:Managing Databricks @ Databricks」 をレポートしています。
“Lethal Trifecta”(プロンプトインジェクションが成立する3条件)や「Human attention is the critical resource(人間の認知こそが希少資源)」というメッセージは、Unity AI Gateway を使う側の運用ノウハウとして読める内容です。
Databricks Data + AI Summit 2026 最速レポート Day2 AIを安全に、そして賢く使いこなす—セキュリティチームと管理チームの現場から—
公式情報:
– Unifying Data and Governance in the Agentic Era(公式ブログ)
OpenAI 連携拡張 + Greg Brockman 対談
OpenAIのGreg Brockman氏と、Databricks共同創業者であるPatrick Wendell氏の対談で、昨年発表の$100M パートナーシップが継続・拡張されることが報告されました。
AI Gateway経由でCodexを利用できる連携、そしてGenie × Codexのネイティブ連携が紹介され、GPT 5.3〜5.5 のリリースケイデンスや「AGIはスペクトラム(単一の到達点ではない)」といった発言もありました。
技術的な詳細よりも、両社の連携姿勢を示すことに重きが置かれた対談でした。
ただ、前回Closed-loop LLMの記事で論じた「フロンティアモデル依存リスク(価格上振れ・モデル差し替え)」の文脈で読むと、CodexをAI Gateway経由で抽象化できるなら、依存リスクを下げられる側面はあります(ただし、Codex固有機能を深く使えば、結局OpenAIロックインは残るので、抽象化が効くのはコモディティ部分だけ、という条件付きで読みたいところです)。
“連携した”だけで本番運用が安心になるわけではないものの、抽象化レイヤーが一枚揃ったことは前進だと受け止めています。
その他の発表
- ・Open Sharing
- — Delta Sharing をオープンソースで拡張、Iceberg+AI資産も共有対象に
- ・Lake Flow / Lake Connect
- — 100+ コネクタ、Spark 宣言的パイプラインで統一
- ・Lakeflow Designer GA
— ノーコード版、Genie駆動 - ・CustomerLake
— エージェント型 CDP(プロファイル / キャンペーン2エージェント)。
提供状況のまとめ(2026年6月17日時点)
実装計画を組む側にとって、各発表がいつから本番利用可能かは前提条件となります。
本日のキーノートで言及された範囲を一覧化します。
| 発表 | 提供状況 | 備考 |
| Genie One | GA(本日) | 月150DBU(約$10相当)を無償付与、2026年7月6日 から無償枠超過分は従量課金 |
| Zerobus Ingest | GA(本日) | Kafka100%wire-compatible |
| Lakeflow Designer | GA | ノーコード、Genie駆動 |
| Open Sharing | GA(順次拡張) | Iceberg / AI 資産対応 |
| Genie ZeroOps | Private Preview(Data + AI Summit直後) | 公式ブログ「Introducing Genie ZeroOps」で詳細確認可能 |
| Lakehouse//RT(Reyden) | Beta | アカウント担当経由で早期アクセス申請可 |
| LTAP(Lakehouse + Lakebase 統合アーキテクチャ) | 近日(具体的な日付は未公表) | コア変換ライブラリはOSS化予定 |
| Unity AI Gateway強化 | 段階的提供 | 既存Unity Catalog上に拡張 |
明日以降の本番展開設計に直結するため、Beta / 未公開ステータスのものは、関連セッション(本 Data + AI Summit 内で並行開催)や公式ドキュメントで個別に確認されることをおすすめします。
おわりに
今回のキーノートを一言で表すなら、Databricksが「分析専用のLakehouse」から「OLTP + OLAP + リアルタイム + AI エージェントを統合する基盤」へと舵を切った宣言、という印象でした。
Reyden + LTAPで技術的な裏付け、Genie OneのGAでアプリケーション層の旗印、そしてそれらをUnity Catalogで横断的に統制する、という建て付けで一貫しています。
逆に言えば、これらを活かす前提条件はUnity Catalogの運用成熟度なので、まずはUC周りの棚卸しから始めるのが最適な順序かな、と個人的には感じました。
残り2日間は、Lakebase / Mosaic AI / Unity Catalog周辺の個別セッションに優先的に参加して、キャッチアップする予定です。
2026年はAIが「実験」から「本番運用」へと一気に踏み込んでくる1年になりそうで、Databricksの発表群はそれを支えるインフラ側の準備が整ってきた、というメッセージとして受け取りました。
このページをシェアする: