Databricks Data + AI Summit 2026 最速レポート Day2
Tuesday Keynote 参加記

目次
みなさん、こんにちは。DATUM STUDIOの田中です。
Databricks Data + AI Summit 2026のレポートとして、本日のKeynote(以下、基調講演)の内容および私が参加したセッションの内容をお届けします。
火曜日の朝は、小雨がパラついて少し肌寒いサンフランシスコでしたが、会場は超満員で熱気にあふれていました!

3時間にわたる基調講演は、ゲストのトークから製品のアップデートまで盛りだくさんな内容でした。本日のレポートはその内容を中心にお伝えします。
TL;DR
内容が盛りだくさんなので、本日発表があったものをまとめたスライドの写真を最初にお届けします。
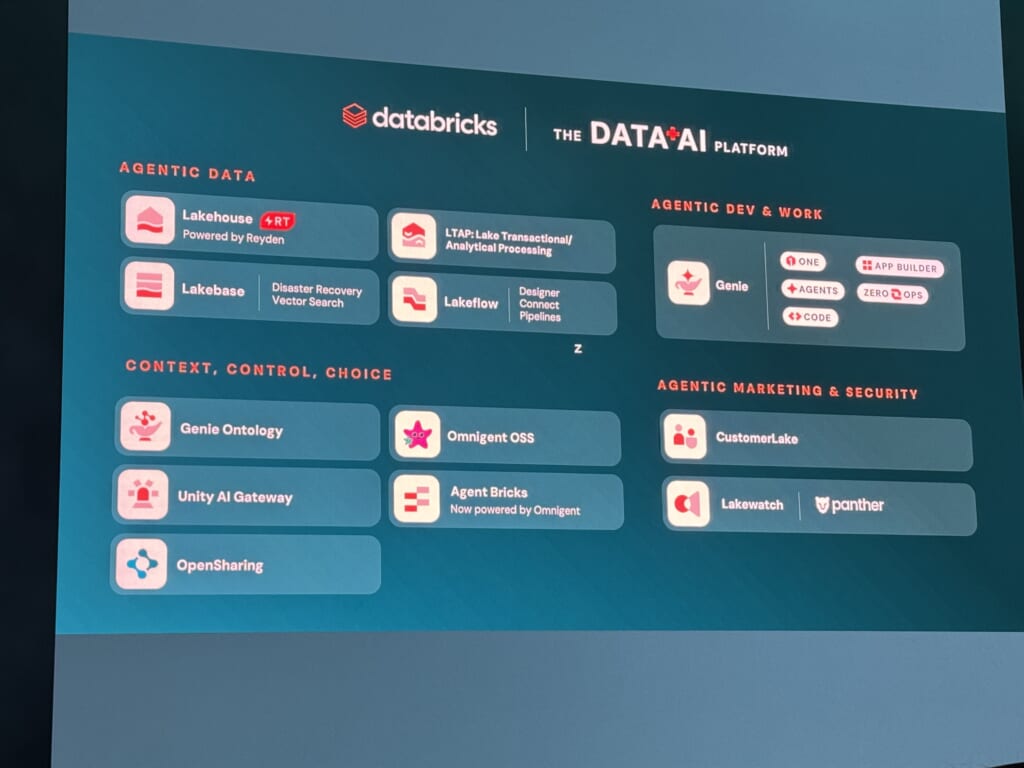
以下のようにまとめられます。
- ・データ処理機能自体の進化
- ・コンテキスト・コントロール・チョイスを確保するための機能追加
- ・Genieの機能追加
- ・マーケティング・サイバーセキュリティといった特定ドメインに特化したエージェントの追加
総じて「チョイス」「コントロール」「コスト」「コンテキスト」をキーワードに、Databricksの製品ポートフォリオの全方位にわたって機能追加が行われた基調講演でした。
では、ここからは各発表の内容を、ざっくり基調講演の時系列に沿ってご紹介します。
この方向性では、Databricksで使える製品の選択肢を増やすことを軸にした製品の整理・機能追加の発表が多くありました。
この観点では改めて、
- ・Zerobus Ingest によるメッセージ配信
- ・Spark Real-Time-Mode による、Spark Streaming よりも低遅延な処理
- ・Lakeflow Designer によるノーコード ETL パイプラインの作成
- ・Iceberg v3 への対応による、Delta との統合の進化
- ・Lakebridge による Lakehouse の移行サポート
といった製品の紹介が行われました。
また、新製品として、LTAP(従来のLakehouseとLakebaseの機能を、統一したストレージレイヤーから扱える製品)が登場しました。こちらについては後述します。

OpenSharing
ここでは、データを誰が見られるのか、という意味での権限管理に加えて、Delta Sharingを拡張・オープンソース化したOpenSharingが紹介されました。
データをコピーすることなく(1か所に配置したままで)クライアントから適切な権限による参照が可能になります。従来のDelta Sharingだけでは対応できなかった、オンプレミスに配置されたデータや、Agent Skills、ML Modelといった種類の共有にも対応できるようになります。
Unity AI Gateway
次に、AI Agentのガバナンスに対応する、Unity AI Gatewayが紹介されました。これにより、統一されたエントリーポイントを通して、フロンティアモデルを含めたモデル自体に加えてMCP、Tool、Agent、Skillsといったリソースに加えて、使用するモデルのUnity Catalog配下での予算コントロールまで可能になります。

Genie Ontology
そして、社内にサイロ化された情報をより早く、より安く、より高品質にDatabricksで管理するツールとして、Genie Ontologyが紹介されました。
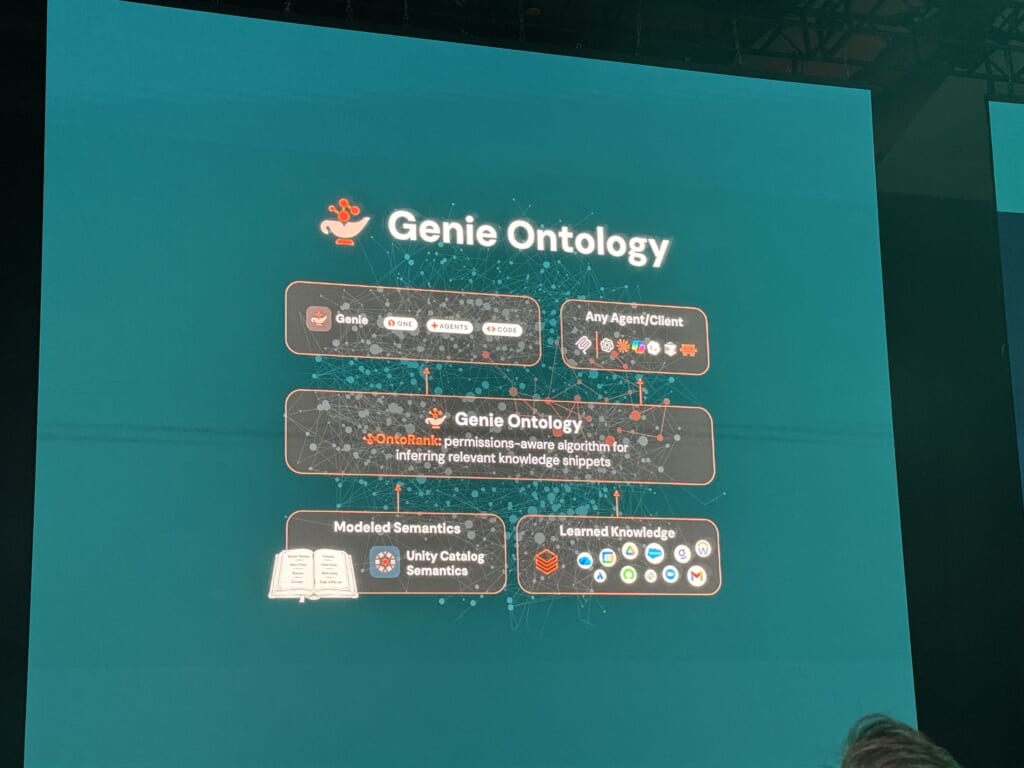
弊社・亀井が詳しく紹介していますので、こちらのレポートもぜひご覧ください。
Genie One・Genie Code
Genie Ontologyを活用することで、既存ツールもさらなる価値を提供できるようになります。社内データへの統一されたアクセスインターフェースとなるGenie Oneや、コード生成ツールとしてのGenie Codeも、文脈に基づいたデータを利用することが見込まれます。
また、SlackやTeamsといった、社内で使われているツールとの統合機能もリリースされました。これにより、使い慣れたツールを切り替えることなく、Genieを利用した社内データの探索が可能になります。
Genie ZeroOps
パイプラインの運用をサポートする新機能として、Genie ZeroOpsが紹介されました。データパイプラインの運用におけるエラー(処理の失敗およびデータ品質の問題)を検知・トリアージして修復まで提案してくれる機能として登場していました。
また、エージェントがうっかり本番データを触って壊してしまわないよう、Shallow Cloneによるデータのコピーと数値検証を行ったうえでの修正も行います。
以下の画像も、ご覧ください。


Lakewatch
Lakewatchは、コストを抑えてオープンなLakehouseを実現するためのセキュリティ管理基盤です。
エージェントなど、データを操作する主体が爆発的に増える中でデータのガバナンスを確保し、時にはアラートを発報するなど、エンタープライズでエージェントを利用するために必要な製品として紹介されています。
CustomerLake
詳細は弊社・亀井のレポートをあわせてご参照ください。
Lakeflow
これまでデータパイプラインを構成するツールは、必要に応じて必要なツールが採用されていました。それは適材適所ではあるものの、技術スタックが複雑になりがちでした。
それに対してLakeflowを採用することで、データパイプライン周りはSparkベースの技術に統一できます。ほかのDatabricks製品と組み合わせて使うことで、さらにシンプルなスタックを実現できるようになります。
Lakehouse RT
従来のLakehouseでは、リアルタイムスピードに近い処理が求められる要件についてはまだ対応できていませんでした。
ここで新しく登場した、クエリエンジンReydenとそれによる処理の高速化のデモがありました。
デモでは、従来1秒かかっていたクエリの処理速度が0.007秒で完了し、大量のエージェントが1インスタンスに対して6,000クエリを投げても1秒以下で終了するなど、大幅な効果が期待できる内容になっていました。

LTAP
LTAPは、DatabricksにおけるOLTPとOLAPの統合ソリューションになります。
これまではOLTP(Lakebase)やOLAP(Lakehouse)それぞれで管理していたデータレイヤーを統一して扱えます。
こうしてデータの置き場所が統一されることで、たとえばAgentが集約されたGoldレイヤーのデータのみ触れるように、ハーネスをセットするなどの運用がしやすくなります。
具体的には、講演内で紹介されていたアーキテクチャとしては、Agent Bricksが最上位のスーパーバイザー(オーケストレーター)を担い、その配下でPrepare / Execute / Act / Knowledgeといった各エージェントが自律的に稼働します。特筆すべきは、個々のエージェントが独立したガバナンス管理とリリースサイクルを保持している点です。例えば「特定のエージェントは既存バージョンのまま据え置きつつ、Prepareエージェントのみ精度向上のため頻繁にアップデートを繰り返す」といった、柔軟かつ機動的な運用が実現できます。
感想
私は普段データエンジニアとして勤務しているので、
- ・Genie ZeroOps
- ・LTAP
の2つが、特に気になりました。
Genie ZeroOpsは、データパイプラインはソフトウェアのみならず、データ自体にも影響を受けて障害が発生することがあり、問題個所の特定や解決に工数がかかってしまいがちです。
そこに対してアプローチしてくれる製品であるGenie ZeroOpsは、大いに期待できるプロダクトなのではないかと思い、会期中さらにウォッチしたい製品になりました。
またLTAPは、Databricksの「様々な技術スタックの統一」という方向性を象徴するものとして、基調講演の中では特に印象に残りました。OLTPやOLAP、さらにはそれらをつなぐ・活かすデータエンジニアリング、データサイエンスといった諸領域を一手に引き受けようとする、Databricksの今後が楽しみになる基調講演でした。
明日以降のブログも、ご期待ください!
このページをシェアする: