【特別連載】 さぁ、自然言語処理を始めよう!(第2回: 単純集計によるテキストマイニング)

目次
はじめに
みなさまこんにちは。 前回の連載 【特別連載】 さぁ、自然言語処理を始めよう!(第1回: Fluentd による Tweet データ収集) では Twitter Streaming API 経由で、日本人がつぶやいた Tweet の 1% ランダムサンプリングデータを fluentd を用いて取得し、その結果を DB (MySQL) に格納しました。 今回はこの集めた Tweet データを、形態素解析ライブラリの MeCab 、Python というプログラミング言語、数値計算用ライブラリである numpy、scipy、scikit-learnを用いて「ある時間における特徴的な言葉」を機械的に抽出してみたいと思います。
処理の流れ
今回行う処理は次のような流れになります。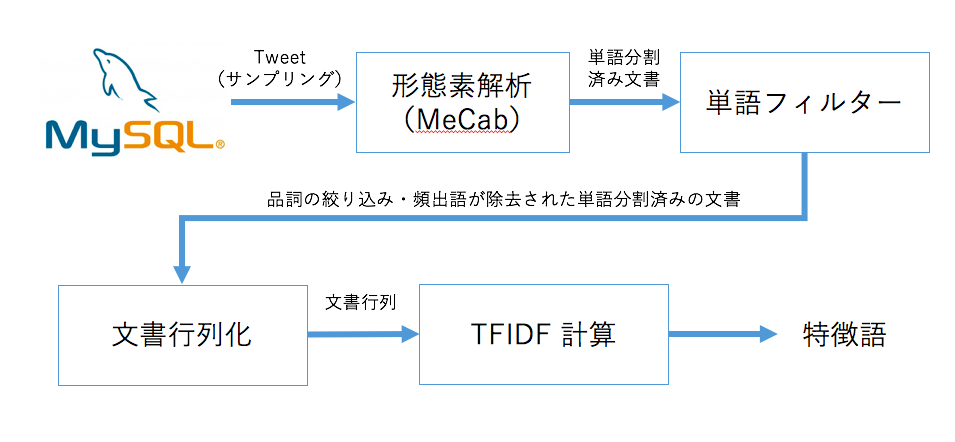
実行環境は前回構築した Amazon Web Service (AWS) の fluentd 用サーバを引き続き利用します。 ・前回利用した Fluentd 用サーバ (AWS EC2) AMI: Amazon Linux AMI 2015.09.1 (HVM), SSD Volume Type Instance type: t2.micro Storage: 10 GB 汎用(SSD)ボリューム また Python のバージョンですが、上記サーバに標準でインストールされている 2 系のものをそのまま利用します。
形態素解析
Bag-of-words モデル
まず、集めたテキストデータを機械的に扱える形式に変換する必要があります。今回は bag-of-words という形式に変換しましょう。Bag-of-Words とは、文章に単語が含まれているかどうかのみを考え、単語の並び方などは考慮しないモデルのことです。一番シンプルなモデルは単語があれば 1、なければ 0 となります。また、単語の出現回数をそのまま使う (Term Frequency) という方法もあります。これは文書中にある単語が含まれている回数をそのまま値として用います。すもももももももものうち (1)
↓
[すもも, も, もも, も, もも, の, うち] (2)
↓
{すもも: 1, も:2, もも: 2, の: 1, うち:1} (3)そして各ドキュメントに含まれる単語を列に、文書を行とすると単語の出現回数を要素とした行列形式に変換できます。 例として、 (a) 「すもももももももものうち」、(b) 「料理も景色もすばらしい」、(c) 「私の趣味は写真撮影です」という3つの文書を考えます。列のラベルは単語の出現の早い順に すもも, も, もも, の, うち, 料理, 景色, 素晴らしい, 私, 趣味, は, 写真撮影, です とすると、文書行列は下記のようになります。[[1,2,2,1,1,0,0,0,0,0,0,0,0], # (a) [0,2,0,0,0,1,1,1,0,0,0,0,0], # (b) [0,0,0,1,0,0,0,0,1,1,1,1,1]] # (c)今回は数値に Term Frequency を用います。この変換を行うためには、元のテキストデータを単語単位に分割する必要があります。これを行うためには形態素解析という技術を用います。
形態素解析とは?
形態素解析 (Morphological Analysis) とは、自然言語で意味を持つ最小単位である形態素に分類し、その品詞を特定する自然言語処理における基礎技術のことです。 これを行うために MeCab というツールが存在します。京都大学情報学研究科−日本電信電話株式会社コミュニケーション科学基礎研究所 共同研究ユニットプロジェクトを通じて開発されたオープンソース 形態素解析エンジンです。MeCab のインストール
では実際に MeCab のインストールを行いましょう。今回はGroongaという全文検索エンジン用のリポジトリを利用して、yum 経由でインストールします。$ sudo rpm -ivh http://packages.groonga.org/centos/groonga-release-1.1.0-1.noarch.rpm $ sudo yum install -y mecab mecab-ipadic mecab-devel動作確認を行います。サーバーのターミナルで
mecab というコマンドを入力した後、「すもももももももものうち」というテキストを入力してみましょう。$ mecab すもももももももものうち すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ も 助詞,係助詞,*,*,*,*,も,モ,モ もも 名詞,一般,*,*,*,*,もも,モモ,モモ も 助詞,係助詞,*,*,*,*,も,モ,モ もも 名詞,一般,*,*,*,*,もも,モモ,モモ の 助詞,連体化,*,*,*,*,の,ノ,ノ うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ EOS
Ctrl + C で終了できます。出力として単語への分割、品詞推定、単語の読みなどを得ることが出来ました。MeCab の Python 用モジュールインストール
では次に、この MeCab への入出力を Python から扱うための Python 用モジュールをインストールしましょう。今回は pip を利用して、PyPI 経由でインストールします。サーバーで以下のコマンドを実行しましょう。$ sudo pip install mecab-python3次のコマンドを実行して、動作確認してみましょう。
$ python
>>> import MeCab
>>> t = MeCab.Tagger("-Ochasen")
>>> print t.parse("すもももももももものうち")
すもも スモモ すもも 名詞-一般
も モ も 助詞-係助詞
もも モモ もも 名詞-一般
も モ も 助詞-係助詞
もも モモ もも 名詞-一般
の ノ の 助詞-連体化
うち ウチ うち 名詞-非自立-副詞可能
EOSこれで Python から MeCab を扱えるようになりました。 情報の順位付け
順位付けの基準
さて、文書を単語単位に分割することが出来るようになったので、次は有用な情報のみに絞っていくことを考えましょう。今回の目的である「ある時間における特徴的な言葉」を抽出することを考えた場合、特定の人名や建造物を表す「名詞」は重要度が高く、逆に「て・に・を・は」などの「助詞」や「だから・けれども」といった「接続詞」などは重要度は低そうです。 また、「私」や「あなた」といったどの文書にも頻出する語は重要度が低く、「東京駅」や「株価」などの特定の文書にしか現れない単語の重要度は高いという前提を置いてしまってもあまり違和感はないでしょう。 前者は単語のフィルタリング、後者は TF-IDF という手法を用いることで情報の順位付けを行うことが出来ます。単語のフィルタリング
特徴語を抽出する場合「名詞」は必須の場合が多いでしょう。また、物事の動作や状態を表す「動詞」や物事の程度や性質、状態を表す「形容詞」なども残しておくと役に立つ場合があります。特に感情解析などを行う際は「形容詞」に着目する場合が多いはずです。 今回は一番シンプルな「名詞」のみを用いることにします。文書行列化
疎行列の取り扱い
さて、文書を単語に分割できるようになったので、これで単語のリストに変換できるようになりました。当初の予定通り各ドキュメントに含まれる単語の値を列に、文書を行とした以下のような Term Frequency を要素とした行列に変換することを考えましょう。。[[1,2,2,1,0,0,0,0,0,0,0,0,0,0, ... ], [0,2,0,1,1,2,2,0,0,0,0,0,0,0, ... ], [0,1,0,0,0,0,0,1,1,2,1,0,0,0, ... ], ... ]単語をそのまま列にとると、いずれかの文書に 1 度でも出現した単語が列になるので、各行はほとんど 0 の値が並ぶ行列になります。これを疎行列 (sparse matrix) と呼びます。疎行列をそのまま扱うのは、メモリ効率的が非常に悪いので、適切な形に圧縮する必要があります。 科学計算用ライブラリの scipy に疎行列を取り扱うためのライブラリがあるので、それを用いても良いのですが、scikit-learn にCountVectorizerというものがあり、単語と列番号の対応付けなどの作業もまとめて行うことが出来ます。この次に行う TF-IDF の計算を行う場合、さらに簡易化したライブラリが存在するので、今回は詳細説明を割愛します。
TF-IDF
これで文書を行列に変換できるようになったので、次は特徴語を抽出する方法を説明します。 TF-IDF は TF と IDF というの2つの値を掛けあわせた指標のことです。- TF (Term Frequency) TF は文書内における単語の出現頻度を表します。これは「ある文書中である単語が何回出現したか」で定義されます。1つの文書に多く出現する単語ほど重要度が高くなります。
- IDF (Inverse Document Frequency) IDF は多数の文書に出現する単語ほど重要度が低くなるようなスコアです。「ある単語が含まれている文書数を全ての文書数で割ったものの逆数」で定義されます。
- TF-IDF TF-IDF は 上記の TF と IDF を掛けあわせた指標です。(1) 〜 (3) を式にまとめると以下のようになります。
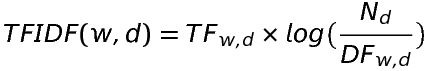
TF: ある文書 d に出現した単語 w の回数 DF: 単語 w が含まれている文書の数 N: 全ての文書数 つまり、TF-IDF が大きな値になるということは、「文書内である特定の単語が多く出現し、かつその単語は他の文書ではほとんど出現しない」ということを表します。 例えば、「私」という単語は、各文書内における出現回数は多いですが、多くの文書に出現するので重要度は下がります。 逆に「特許」という単語は、「特許」を話題の中心にしている特定の文書には文書内には多く現れ、一般的な文書には現れない単語なので重要度は上がります。 よって TF-IDF が大きいほど各文書の特徴を表す単語ということが出来るでしょう。 TF-IDF の計算は scikit-learn の TfidfVectorizer を用いれば、前述の CountVectorizer による疎行列化と TF-IDF の計算を同時に行うことが出来るので、今回はこれを用いて TF-IDF の計算を行います。
必要な Python 用ライブラリのインストール
では今回利用する scikit-learn とその他必要なライブラリをインストールしましょう。サーバにログインし、以下のコマンドを実行します。$ sudo yum install -y atlas-devel lapack-devel blas-devel $ sudo yum install -y python27-numpy $ sudo yum install -y python27-scipy $ sudo pip install scikit-learn $ sudo pip install MySQL-pythonnumpy, scipy ですが、メモリが少ない環境で pip を利用してインストールした場合、メモリ不足で正常にインストールを終了できない場合があるので、今回は yum 経由でインストールしました。では実際に特徴語を抽出するコードを書いてみましょう。
サンプルコード
サンプルコードは以下のようになります。MySQL からTweet データを 2000 件取得した後形態素解析して名詞のみを抽出し1つのスペース区切り文字列にするという処理を、合計10日分繰り返します。つまり、各日からドキュメントを 1 個、全日合計 10 個のドキュメントを生成します。そしてこの 10 個のドキュメントを元に、 TfidfVectorizer を用いて TF-IDF の計算を行いました。#!/usr/bin/env python
# -*- coding:utf-8 -*-
import MySQLdb
import MeCab
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
### MySQL 上の Tweet データ取得用関数
def fetch_target_day_n_random_tweets(target_day, n = 2000):
with MySQLdb.connect(
host="your DB host",
user="your DB user",
passwd="your DB password",
db="textdata",
charset="utf8") as cursor:
SQL = u"""
SELECT
text
FROM
tweet
WHERE
DATE(created_at + INTERVAL 9 HOUR) = '%s'
LIMIT %s;
""" %(target_day, unicode(n))
cursor.execute(SQL)
result = cursor.fetchall()
l = [x[0] for x in result]
return l
### MeCab による単語への分割関数 (名詞のみ残す)
def split_text_only_noun(text):
tagger = MeCab.Tagger()
text_str = text.encode('utf-8') # str 型じゃないと動作がおかしくなるので変換
node = tagger.parseToNode(text_str)
words = []
while node:
pos = node.feature.split(",")[0]
if pos == "名詞":
# unicode 型に戻す
word = node.surface.decode("utf-8")
words.append(word)
node = node.next
return " ".join(words)
### TF-IDF の結果からi 番目のドキュメントの特徴的な上位 n 語を取り出す
def extract_feature_words(terms, tfidfs, i, n):
tfidf_array = tfidfs[i]
top_n_idx = tfidf_array.argsort()[-n:][::-1]
words = [terms[idx] for idx in top_n_idx]
return words
### メイン処理
docs_count = 2000 # 取得 Tweet 数
target_days = [
"2015-11-11",
"2015-11-12",
"2015-11-13",
"2015-11-14",
"2015-11-15",
"2015-11-16",
"2015-11-17",
"2015-11-18",
"2015-11-19",
"2015-11-20",
]
target_day_nouns = []
for target_day in target_days:
print target_day
# MySQL からのデータ取得
txts = fetch_target_day_n_random_tweets(target_day, docs_count)
# 名詞のみ抽出
each_nouns = [split_text_only_noun(txt) for txt in txts]
all_nouns = " ".join(each_nouns)
target_day_nouns.append(all_nouns)
# TF-IDF 計算
# (合計6日以上出現した単語は除外)
tfidf_vectorizer = TfidfVectorizer(
use_idf=True,
lowercase=False,
max_df=6
)
tfidf_matrix = tfidf_vectorizer.fit_transform(target_day_nouns)
# index 順の単語のリスト
terms = tfidf_vectorizer.get_feature_names()
# TF-IDF 行列 (numpy の ndarray 形式)
tfidfs = tfidf_matrix.toarray()
# 結果の出力
for i in range(0, len(target_days)):
print "\n------------------------------------------"
print target_days[i]
for x in extract_feature_words(terms, tfidfs, i, 10):
print x,TfidfVectorizer は様々なチューニングを行えますが、今回は、max_df オプションの部分で「過半数の日に出てくる単語は重要度が低い」という仮定 ( 6 / 10 を超えるとカット) を設定しています。 実行結果確認
実行結果は以下のようになりました。------------------------------------------ 2015-11-11 ポッキー 祐也 中野 宮地 手越 プリッツ 清志 けい ペロ Ta ------------------------------------------ 2015-11-12 ポッキー スペシャアプリ テレレ ユニフォーム gekisaka Jx orange プリッツ Free ぉろみ ------------------------------------------ 2015-11-13 久久 アア JUNGKOOK 金曜日 JUNE 拓哉 戸塚 優里 法則 木村 ------------------------------------------ 2015-11-14 MOMIKEN チャーリー imas 工場 暗記 子役 JEN JUNE チョコレート ウパ ------------------------------------------ 2015-11-15 monogatari オオ テロ ソファー ビッチ Tour PrayForParis 甘栗 wwwwwww 戦争 ------------------------------------------ 2015-11-16 タオ ゙ア カリ アア Sexy ホルモン Zone ndBACK 月曜日 暗記 ------------------------------------------ 2015-11-17 黒尾 真琴 古賀 御幸 一也 パニーニ レム オイ エナドリ 園児 ------------------------------------------ 2015-11-18 DJP 岡田 INFO SHINING BLOODY SHADOWS THEATER シャイニング シアターシャイニング レン ------------------------------------------ 2015-11-19 SH Tokiya ポラリス MTVSTARSKatyPerry 実感 ダンデビ ミュージカル 及川 人人 美風 ------------------------------------------ 2015-11-20 ブー ヴン 1120 BAP デッドボール ぅんわぁははは 山崎 投手 金曜日 グランプリ結果を見てみると、11/11、11/12 に「ポッキー・プリッツの日」関連の単語が出現していることが確認できます。そして 11/15 には「PrayForParis」というパリ同時多発テロ関連の単語が出現しています。また、「月曜日」や「金曜日」といった単語も実際の月曜日や金曜日に現れており、逆に他の曜日が現れていないことを考えると、 Twitter では特に「月曜日」や「金曜日」が他の曜日に比べて重要な意味を持つ可能性が見えました。11/14 に「チャーリーとチョコレート工場」に含まれている単語が現れていますが、これは 11/13 の金曜ロードショーで放送され、話題が拡散した結果かもしれません。その他の単語も調べてみると確かにその日に話題になっていたような単語が含まれていることがわかります。 今回使用したマシンでは高負荷に耐えられないので少なめの Tweet 数で実験しましたが、使用する Tweet を増やせばより正確な結果に近づくでしょう。また今回は1日単位で区切りましたが、1時間単位、1週間単位などで実験しても面白い結果が出るかもしれません。 また結果に「チャーリーとチョコレート工場」のように固有名詞の形態素解析に失敗した単語も出現していますが、これらは MeCab のユーザ辞書の追加により改善可能です。 mecab-ipadic-neologd という MeCab の辞書が公開されており、これをユーザー辞書として追加することで解析精度向上が期待できるでしょう。またあまり特徴語として意味のない記号等の除去についてはストップワードの追加などで対応することが可能です。この辞書やストップワードのメンテナンスは泥臭い作業になりますが、高精度を追求するなら必須の作業です。 そして計算に必要なパラメータの設定を変更すると単語の出現傾向も変わるので、実務で使う際は目的に合わせて何度もパラメータを変更しながら再計算し、時間をかけてチューニングを行うことも大切です。
おわりに
今回は単純集計によるテキストマイニングの手法を紹介しました。比較的単純な処理でもこのような分析を行うことが出来ます。 また今回の操作でテキストデータを数値の行列に変換することが可能になったので、より高度な統計的手法を適用するも可能になりました。 次回は機械学習を用いたテキストマイニングを行います。このページをシェアする: