【特別連載】 さぁ、自然言語処理を始めよう!(最終回: 機械学習によるテキストマイニング)

はじめに
みなさまこんにちは。 前回の連載 【特別連載】 さぁ、自然言語処理を始めよう!(第2回: 単純集計によるテキストマイニング) では TF-IDF を用いて Twitter Streaming API 経由で取得した日本語 Tweet データから、ある日の特徴語を抽出する方法を紹介しました。 今回は機械学習を用いたテキストマイニングを行いたいと思います。機械学習とは「経験により自動的に改善していく」コンピュータープログラムの構築方法に関わる分野です。 具体的には Python の機械学習用ライブラリである scikit-learn を用いて、集めた Tweet データを「ポジティブ」、「ネガティブ」なものに自動で分類する方法を紹介します。
処理の流れ
今回行う処理は次のような流れになります。- 学習用データの作成
- データの前処理
- 手法の選択
- モデルの学習
- 未知要素の分類
学習用データの作成
今回は自動でポジティブ、ネガティブなものを分類 (PN 分類) する分類器 (classifier) を作成するために、事前にこれはポジティブなもの、これはネガティブなものという学習用データを用意し、どちらに近いか?という判定を行います。これは「教師あり学習」 (supervised learning) と呼ばれます。 学習用データの作成方法ですが、基本的には以下の手順で行います。- 対象データの抽出
- データのラベル付け
目次
対象データの抽出
対象データの抽出ですが、この作業が作成したい分類器の性質に一番強い影響を与えることが多いです。汎用性と分類精度はトレードオフの関係にあります。狭い範囲のみを対象にする方が対象範囲に関しては高精度なりますが、学習させなかった範囲に対しては非常に精度が悪くなります。 今回は高汎用性でそれなりの精度を目指すようなデータの抽出方法を選びます。汎用性の高くなるデータの抽出方法としてランダムサンプリングという方法があります。これは特に制約を設けず、全データからランダムに一定の件数を抽出する方法です。 今回は以下のような MySQL のクエリで抽出します。mysql -h 'YOUR_HOST' -u YOUR_USER \ -pYOUR_PASSWORD \ YOUR_DB_NAME \ -e 'SELECT * FROM text ORDER BY RAND() LIMIT 50000' \ > '~/tweets.tsv'
-pの後はスペースを入れないので注意してください。これでタブ文字 (‘’) 区切りで対象のテーブルからランダムに5万件のデータを抽出することができます。データのラベル付け
テキストエディタや Excel などを利用して、先ほどランダムサンプリングしたツイートからポジティブな Tweet 、ネガティブな Tweet を選別し抽出していきます。地味な作業ですが、おそらく今回の高精度を達成するためには、出来る限り多くのデータを用意することが大切です。またそれぞれ同数を用意することが、今回はポジティブ・ネガティブそれぞれ2500件、合計5000件ほどを抽出しました。そしてポジティブなものには整数値の1、ネガティブなものには-1を割り当てます。この数値の記述方法ですが、DB に格納してから追加してもよいですし、事前にファイルに記述してしまってから格納してしまっても問題ありません。今回は事前に全部記述した想定で進めます。 この結果を DB に再び格納しましょう。まず以下のコマンドで DB に接続します。$ mysql -h 'YOUR_HOST' -u YOUR_USER -pYOUR_PASSWORD YOUR_DB_NAME以下のクエリを実行して、DB にログイン後格納用テーブルを作成します。ラベル情報のカラムは末尾に追加したと想定しています。
mysql> CREATE TABLE `pn_tweet` ( `id` bigint NOT NULL, `user_id` bigint NOT NULL, `text` text, `created_at` datetime NOT NULL, `label` int, KEY `id` (`id`), KEY `idx_user_id` (`user_id`), KEY `idx_created_at` (`created_at`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;その後、以下のコマンドでポジティブ・ネガティブラベルデータを追加した TSV ファイルを取り込みます。
mysql> LOAD DATA LOCAL INFILE [ファイルパス] INTO TABLE pn_tweet;
データの前処理
処理内容
今回行うデータの前処理ですが、前回の連載 【特別連載】 さぁ、自然言語処理を始めよう!(第2回: 単純集計によるテキストマイニング) でも紹介した [MeCab][] を利用して形態素に分割した後、CountVectorizer を用いて文書ベクトル化します。 基本的に流れは前回と同じですが、使用する品詞は名詞に加え、動詞、形容詞も利用します。動詞については終止形に直したものを用います。 また、データの取り扱いが楽になる pandas というデータ処理用ライブラリもデータ加工に利用します。以下のコマンドでインストールしましょう。$ sudo pip install pandas
データの前処理部分サンプルコード
前処理を行うための関数部分を切り出したものを紹介します。なお、後の処理で必要になるライブラリもここですべて読み込んでいます。### 使用するライブラリ
import MySQLdb
import pandas.io.sql as psql
import pandas as pd
import numpy as np
import MeCab
from sklearn import svm
from sklearn.grid_search import GridSearchCV
from sklearn.feature_extraction.text import CountVectorizer
print "[INFO] ドキュメント取得"
tweets = psql.read_sql(
"SELECT text, label FROM pn_tweet",
MySQLdb.connect(
host = "YOUR DB HOST",
user = "YOUR DB USER",
passwd = "YOUR DB PASSWORD",
db = "textdata",
charset = 'utf8'
)
)
def wakati(text):
tagger = MeCab.Tagger()
text = text.encode("utf-8")
node = tagger.parseToNode(text)
word_list = []
while node:
pos = node.feature.split(",")[0]
if pos in ["名詞", "動詞", "形容詞"]:
lemma = node.feature.split(",")[6].decode("utf-8")
if lemma == u"*":
lemma = node.surface.decode("utf-8")
word_list.append(lemma)
node = node.next
return u" ".join(word_list[1:-1])
print "[INFO] 分かち書き"
tweets['wakati'] = tweets['text'].apply(wakati)
### BoW (Term Frequency) 素性ベクトルへ変換
# feature_vectors: scipy.sparse の csr_matrix 形式
# vocabulary: 列要素(単語) 名
print "[INFO] 素性ベクトル作成"
count_vectorizer = CountVectorizer()
feature_vectors = count_vectorizer.fit_transform(tweets['wakati'])
vocabulary = count_vectorizer.get_feature_names()ここまでで、素性ベクトルへの変換ができました。次は機械学習の手法の選択です。手法の選択
機械学習の手法
昨今では深層学習(Deep Learning)が話題になっていますが、対象とするデータ量が比較的小さい場合は選択するメリットがあまりありません。今回のような場合はサポートベクターマシン (support vector machine: SVM) やランダムフォレスト (random forest) などがまず試すべき候補となります。今回はとりあえずサポートベクターマシンで実験してみましょう。サポートベクターマシンの概要
SVM は次の図のように事前に与えた黒マル、白バツ2つのグループ間のマージンが最大になるような、分離超平面: P を決定します。その後、未知のデータが与えられた際にどちらのグループに帰属するかをを判断します。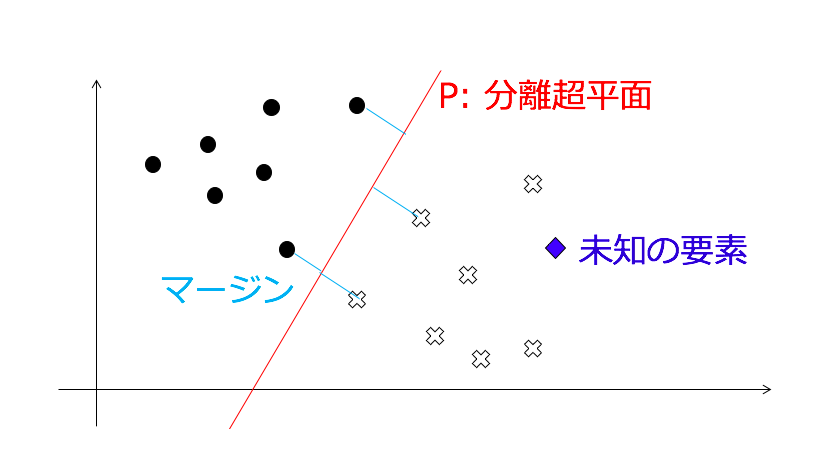
SVM は教師あり学習で、上記の例だと黒マル、白バツが学習データです。もともと SVM は上記の例のように線形でしか境界線を決定できませんでした。しかし、カーネル法と呼ばれる手法を用いて高次元空間に写像すれば、非線形なものも直線で切ることが可能になります。今回は非線形データでも対応できるRBFカーネルを用います。
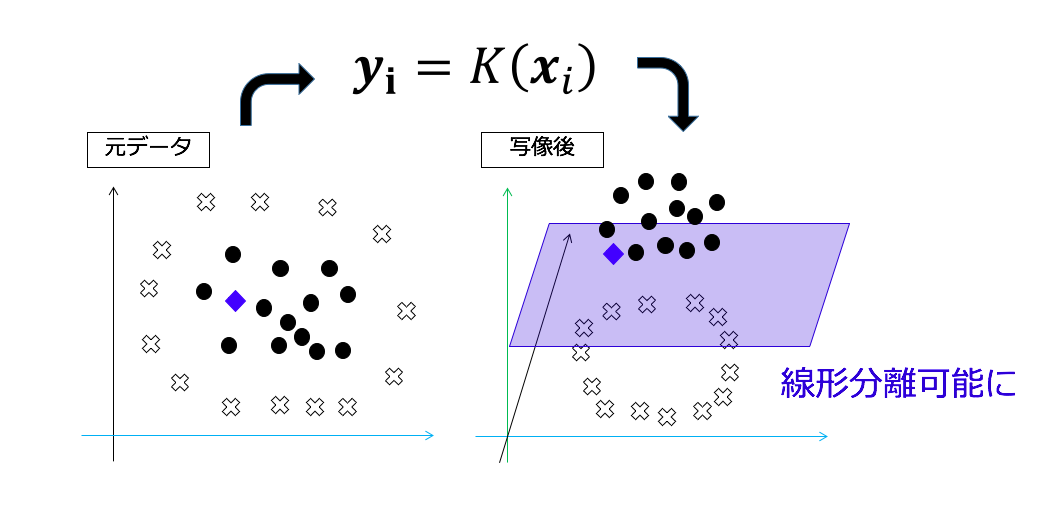
モデルの学習
では実際に学習データにより学習を行ってみましょう。ここではパラメータチューニングとその評価方法について説明します。パラメータチューニング
コストパラメータ
問題を解く際にはどの程度誤りを許容するかが問題となります。これはコストパラメータ: C で設定でき、C が大きい場合は誤りを許容しないように、C が小さい場合は誤りを許容するようになります。 厳密にやりすぎると、未知のものに対する予測性能 (汎化能力) が低下する、つまり過学習を起こしてしまうので、未知の要素に対して高精度になるようにコストパラメータにしてやる必要があります。次の図のような場合だと、人間が見た場合右の方が自然な境界に見えると思います。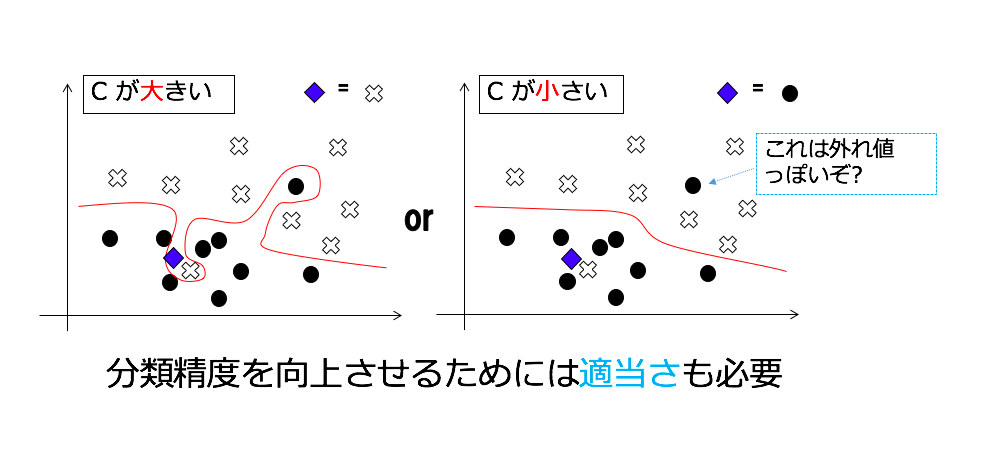
グリッドサーチ
RBF カーネルの場合、コストパラメータに加え、1変数のカーネルパラメータ: γ もチューニングする必要があります。このときにグリッドサーチと呼ばれる手法を用います。次の図のように、それぞれのパラメータを増減させ、全ての組み合わせを試します。まずは荒い探索を行い、その後細かい探索を行うと良いでしょう。 RBF カーネルの場合、以下の様な範囲を探索すると良いでしょう。 C: 2 の -5 〜 15 乗 γ: 2 の -15 〜 3 乗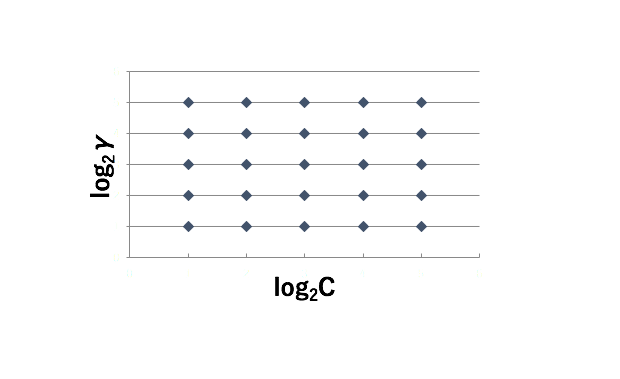
クロスバリデーション
クロスバリデーション (交差検定とも呼ぶ) は過学習を避けるための学習データとテストデータの分割方法です。 学習データ k 個に分割し、 1 つを除いたものを学習させ、残しておいた 1 個を分類させます。これを k 回繰り返すと、未知のデータを k セット分類した場合の結果を得ることができます。 こうすることで、未知のデータに対する性能を保証することができます。機械学習の場合、既知のデータが正しく分類できることよりも、未知のデータが正しく分類できるかが性能指標として重要なのです。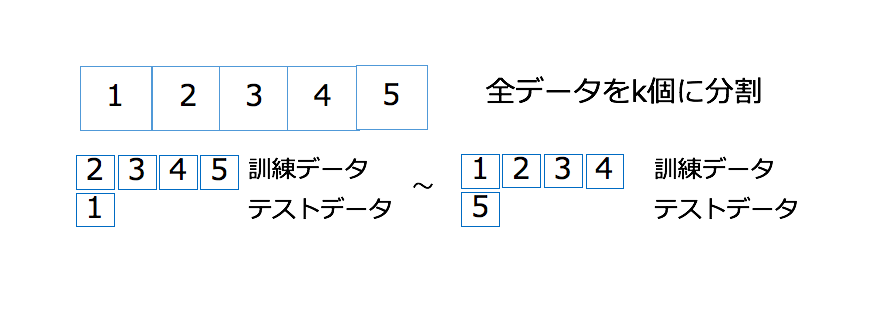
学習部分のサンプルコード
グリッドサーチ、クロスバリデーションを用いて、学習を行いモデルを構築するためのサンプルコードは以下のようになります。すでに行った前処理済みのデータをそのまま用います。### SVM による学習
print "[INFO] SVM (グリッドサーチ)"
svm_tuned_parameters = [
{
'kernel': ['rbf'],
'gamma': [2**n for n in range(-15, 3)],
'C': [2**n for n in range(-5, 15)]
}
]
gscv = GridSearchCV(
svm.SVC(),
svm_tuned_parameters,
cv=5, # クロスバリデーションの分割数
n_jobs=1, # 並列スレッド数
verbose=3 # 途中結果の出力レベル 0 だと出力しない
)
gscv.fit(feature_vectors, list(tweets['label']))
svm_model = gscv.best_estimator_ # 最も精度の良かったモデル
print svm_model
# SVC(C=64, cache_size=200, class_weight=None, coef0=0.0,
# decision_function_shape=None, degree=3, gamma=0.0001220703125,
# kernel='rbf', max_iter=-1, probability=False, random_state=None,
# shrinking=True, tol=0.001, verbose=False)未知データの分類
では学習結果を用いて、「ポジティブ」、「ネガティブ」という情報が未知のツイートを分類してみましょう。以下のコードを実行すると4つのサンプルツイートに対して、ポジティブならば 1 、ネガティブならば -1 を出力します。 学習時に取得した vocabulary を CountVectorizer にセットしてやらないと、同一構造の文書ベクトルにならないので、エラーとなってしまいます。注意しましょう。
### SVM による分類
print "[INFO] SVM (分類)"
sample_text = pd.Series([
u"無免許運転をネット中継 逮捕 - Y!ニュース news.yahoo.co.jp/pickup/...",
u"田舎特有のいじめが原因かな……複数殺人および未遂って尋常じゃない恨みだろ | Reading:兵庫県洲本市で男女5人刺される 3人死亡 NHKニュース",
u"BABYMETAL、CDショップ大賞おめでとうございます。これからも沢山の方がBABYMETALに触れる事でしょうね。音楽ってこんなにも楽しいって教えられましたもん。 ",
u"タカ丸さんかわいいな~"
])
split_sample_text = sample_text.apply(wakati)
count_vectorizer = CountVectorizer(
vocabulary=vocabulary # 学習時の vocabulary を指定する
)
feature_vectors = count_vectorizer.fit_transform(split_sample_text)
print svm_model.predict(feature_vectors)
# [-1, -1, 1, 1]これでツイートのポジティブ・ネガティブを自動で判別できるようになりました。後は気になる任意の対象のツイート群に対して適用してやれば、ポジティブなツイート、ネガティブなツイートの比率が分かります。おわりに
今回は機械学習によりポジティブ・ネガティブなツイートを識別することによりテキストマイニングを行うための方法を解説しました。今回使用したサンプルコードは 次のURL にまとめてあります。 皆さんもこの3回で紹介した手法を応用して、気になるテキストデータを分析してみましょう!参考文献
- AWS 公式
- Python 日本公式
- MeCab: Yet Another Part-of-Speech and Morphological Analyzer
- mecab-python
- numpy
- scipy
- scikit-learn
- scikit-learn: CountVectorizer
- サンプルコード
- MACHINE LEARNING, Tom M. Mitchell, McGraw-Hill Education; 1 edition (March 1, 1997)
このページをシェアする:
DATUM STUDIOは、クライアントの事業成長と経営課題解決を最適な形でサポートする、データ・ビジネスパートナーです。
データ分析の分野でお客様に最適なソリューションをご提供します。まずはご相談ください。
Contact

Explore Jobs

関連記事