【特別連載】 さぁ、自然言語処理を始めよう!(第1回: Fluentd による Tweet データ収集)

はじめに
みなさまこんにちは。 データ分析に力を入れている会社でも、大量に蓄積されているテキストデータから有用な情報を抽出する「テキストマイニング」はなかなかハードルの高い分野ではないでしょうか? この連載では実際に Twitter でつぶやかれている話題の分析を行うことで、テキストマイニング行う際に必要になる技術・手法を解説したいと思います。 具体的には以下の内容を予定しています。- 1回目: fluentd による Tweet データ収集
- 2回目: 単純集計によるテキストマイニング
- 3回目: 機械学習によるTweet分類
システム構成
システム全体像は、次の図のような構成になります。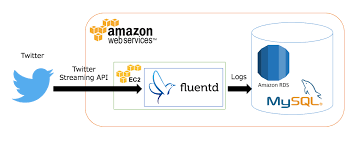
今回はサーバにクラウドサービスの Amazon Web Service (AWS) を利用します。下記の設定なら AWS 無料利用枠に収まるので、 AWS アカウントを作成した日から 12 か月間はほぼ無償で使用することが出来ます。細かい作成方法について今回は割愛しますが、作成ウィザードに従って作業すれば、特に困らないはずです。
- Fluentd 用サーバ (AWS EC2) AMI: Amazon Linux AMI 2015.09.1 (HVM), SSD Volume Type Instance type: t2.micro Storage: 10 GB 汎用(SSD)ボリューム
- DB サーバ (AWS RDS) DB engine: MySQL Instance type: db.t2.micro multi-AZ: no Storage: 20 GB 汎用(SSD)ボリューム
Twitter OAuth 認証キーの取得
Twitter からデータを収集する際には Twitter OAuth 認証キー が必要になります。 まずはデータ収集に使用するための Twitter のアカウントを新規作成した後、メール認証と携帯電話番号の 登録 を済ませ、ログイン状態を維持したまま Twitter Developers ページ にアクセスしましょう。 Twitter Developers ページの画面下部にあるメニューの中からTOOLS 項目中の Manage Your Apps をクリック、リンク先のページのCreate New App をクリックしましょう。登録フォームが出てくるので、Application Details に下記内容を入力してください。- Name: 今回作成するアプリケーション名前 (任意の値)。
- Description: 今回作成するアプリケーションの説明を書く (任意の値)。
- Website: 自分のサイトのURLを入力。仮でも可。
- Callback URL: 空欄のままで可
Yes, I agree にチェックを入れ、Create your Twitter application をクリック。なお、電話番号登録が終わっていないと、次に進めないので注意しましょう。 アプリケーションが作成できたら、画面上部のタブのKeys and Access Tokens をクリックし、画面遷移後、画面下部の Create my access tokenをクリックします。これで Twitter Streaming API の利用に必要な以下の4つの情報を確認できます。- consumer_key
- consumer_secret
- Access Token
- Access Token Secret
MySQL サーバの設定
次はデータの格納先である、MySQLサーバの設定を行います。まずはAWS 上に作成した MySQL サーバに MySQL クライアントで接続し、以下のクエリを実行します。今回作成する DB 名は textdata, テーブル名は tweet としました。今回は最低限の要素のみを取得しますが、取得できる項目はここで作成したカラム以外にもいろいろあるので (参考文献の 「Twitter API 概要 – Tweet オブジェクト」 を参照) 、適宜書き換えてください。CREATE DATABASE textdata; USE textdata; CREATE TABLE IF NOT EXISTS tweet ( id BIGINT NOT NULL, user_id BIGINT NOT NULL, text TEXT, created_at DATETIME, KEY id (id), KEY idx_user_id (user_id), KEY idx_created_at (created_at) ) DEFAULT CHARSET=utf8;
Fluentd サーバの設定
次は Fluentd サーバの設定を行いましょう。以下の作業を AWS に作成した仮想マシンで行います。ファイルディスクリプタ数の上限変更
まずは1プロセスが同時に開くことが出来るファイルディスクリプタの数の上限を増やします。任意のエディタで/etc/security/limits.conf に以下の内容を追記します 。$ sudo emacs /etc/security/limits.conf
# これらを追記 root soft nofile 65536 root hard nofile 65536 * soft nofile 65536 * hard nofile 65536その後仮想マシンをリブートします。
$ sudo reboot下記コマンドを実行し、
65536 が出力されれば OK です。$ ulimit -n 65536
Fluentd のインストール
TresureData のリポジトリを利用してインストールします。下記コマンドを実行することでインストールできます。$ curl -L http://toolbelt.treasuredata.com/sh/install-redhat-td-agent2.sh | sh
Fluentd プラグインのインストール
Twitter からストリーミングデータを受け取るための input プラグインをインストールします。$ sudo yum -y install openssl-devel libcurl libcurl-devel gcc-c++ $ sudo td-agent-gem install install eventmachine $ sudo td-agent-gem install fluent-plugin-twitter続いて、 MySQL サーバへの output に使用するプラグインもインストールします。
$ sudo yum install -y mysql-devel $ sudo td-agent-gem install fluent-plugin-mysql
fluentd の設定ファイル変更
次は fluentd の設定ファイルtd-agent.conf を任意のエディタで開き、設定を追記します。<source> 〜 </source> が入力側の設定、<match> 〜 </match> が出力側の設定です。 source 部分について、consumer_key, consumer_secret, oauth_token , oauth_token_secret はTwitter OAuth 認証キーの取得で取得した4つの値を記述してください。また、output_format は今回ユーザIDに簡単にアクセスできるように flat を選択しましたが、nest を指定すると、元のJSON構造をそのまま保ったまま取得できます。 またmatch 部分について、host, username, password の部分は AWS RDS で作成時に定まったエンドポイント、設定したDBユーザー名、DBのパスワードを入力してください。取得する項目をを追加した場合は、key_names と sql の部分に同じ形式で追加してやれば大丈夫です。$ sudo emacs /etc/td-agent/td-agent.conf
<source> type twitter consumer_key YOUR_CONSUMER_KEY consumer_secret YOUR_CONSUMER_SECRET oauth_token YOUR_OAUTH_TOKEN oauth_token_secret YOUR_OAUTH_TOKEN_SECRET tag input.twitter timeline sampling lang ja output_format flat </source> <match input.twitter> type mysql host XXXX.us-west-2.rds.amazonaws.com database textdata key_names id, user_id, text, created_at sql INSERT INTO tweet (id, user_id, text, created_at) VALUES (?, ?, ?, STR_TO_DATE(?, "%a %b %d %H:%i:%s +0000 %Y")) username YOUR_DB_USER_NAME password YOUR_DB_PASSWORD flush_interval 10s </match>
fluentd 起動 & 動作確認
では実際に fluentd を起動してみましょう。以下のコマンドを実行します。$ sudo service td-agent startきちんと起動したかどうかログファイルを確認しておきます。エラーが無ければOKです。
$ sudo emacs /var/log/td-agent/td-agent.log最後に MySQL サーバに接続し、結果を確認してみましょう。 以下の SQL を実行します。
mysql> SELECT * FROM tweet LIMIT 10\G
*************************** 1. row ***************************
id: 663269639460290560
user_id: 173772908
text: カードも無事に集めれた◞( 、*´▿`)、 https://t.co/SpWWGln6z2
created_at: 2015-11-08 08:19:39
*************************** 2. row ***************************
id: 663269643650404353
user_id: 945808578
text: 商品が売れている証拠だ
created_at: 2015-11-08 08:19:40
*************************** 3. row ***************************
id: 663269643662983168
user_id: 2159208668
text: @ai_na0624 あいぬーん
created_at: 2015-11-08 08:19:40
*************************** 4. row ***************************
(以下省略...)実際にデータを見てもらえばわかると思いますが、created_at に格納されているのは世界標準時 (UTC) なので、実際に取り扱う際はこの値に9時間足した値が日本標準時 (JST) となります。おわりに
今回は fluentd の実用例を紹介しました。入力・出力のプラグインをインストールし設定ファイルを記述するだけで、簡単にログデータ収集を行うためのシステムを構築することが出来ました。 これで自動的に Tweet データを収集する環境が整ったので、次回はこのデータを用いてテキストマイニングを行ないます。このページをシェアする:
DATUM STUDIOは、クライアントの事業成長と経営課題解決を最適な形でサポートする、データ・ビジネスパートナーです。
データ分析の分野でお客様に最適なソリューションをご提供します。まずはご相談ください。
Contact

Explore Jobs

関連記事