Snowflake Summit 2026 最速レポート Day3
【セッション解説】NBAに学ぶ、Snowflakeで実現するファンデータ基盤(Fan Data Platform)

目次
はじめに
DATUM STUDIOの唐内です。
「Snowflake Summit 2026」で聴講したセッション「Driving Fan Engagement with the NBA’s Fan Data Platform on Snowflake(DE201)」についてご紹介します。
世界中に数億人規模のファンを抱えるNBA(米プロバスケットボールリーグ)が、数百のデータソースを少人数のチームでどう処理しているのか。
スライドそのものより、登壇者が語った「なぜ、その設計にしたのか」という、現場の判断にこそ学びが多いセッションでした。私自身、中学から社会人まで10年以上バスケをしており、普段見ているNBAの裏側の話が聞けたことが個人的にも嬉しかったです。
NBAのファンデータ基盤(FDP)とは
NBAのファンデータ基盤(Fan Data Platform:FDP)は、ファン接点を「収集・名寄せ・活用」する中核ハブです。試合時の来場、チケットの売買・リセール、アリーナ内行動、グッズ購入、Web行動、ストリーミングまで、接点は多岐にわたります。
やっかいなのは、NBAがグローバルスポーツである点です。データ種別ごとに国内で1〜5社、地域・国を含めれば数百のパートナーが存在し、スキーマも粒度、連携方式、信頼性もバラバラ。これを少人数のチームで取りまとめ、下流の利用者が迷わず使える標準システムにして届けることが、FDPのミッションです。
課題:スケールと増分処理が絶対
このセッションで最も腑に落ちたのが、設計判断の出発点が「NBAシーズンの負荷の山谷」にあるという話でした。
NBAのシーズンは通年ではなく、試合は夜に集中します。登壇者によると、オフシーズンの夏に新しいデータセットを取り込むと「順調だ、コストもこのくらいだ」と把握できます。
ところが開幕すると、初日から十数試合が同じ夜に走り、データ量が一気に跳ね上がる。オフシーズンの基準で組んでいると、ここで破綻して「夜中に電話が鳴る」というわけです。
だからこそ、
- ・すべてをスケールできる前提で組む
- ・処理は基本すべて増分。 どうしても無理で強い理由がない限り、フルリフレッシュはしない
という割り切りが、徹底されています。
「この規模でフルリフレッシュをやると、すぐ倒れる」という一言には、規模を問わず共感する方も多いのではないでしょうか。
解決策:設定駆動という割り切り

数百のソースを少人数で処理する鍵が、設定駆動(Configuration-Driven)の取り込みフレームワークです。
具体的には、標準化されたおよそ50のAPI取り込みと、15ほどのカスタム処理を用意し、新しいソースが増えても基本は「設定(リスト)の調整」で対応します。コードを都度書き直すのではなく、再利用可能なパイプラインパターンに載せることで、数百規模へ素早くスケールさせています。
「一回限りのカスタム対応は極力避け、繰り返し使える・標準化できる形にする」という思想は、取り込み・変換を標準化していく我々の現場の発想とも重なります。少人数で広い面を支えるには、この割り切りが効いてくると改めて感じました。
設計思想:PIIを入口で切り離す「修正版メダリオン」

FDPはBronze → Silver → Goldのメダリオンアーキテクチャですが、「修正版(Modified)」である点が肝でした。
データの入口でPII(個人情報)を分離し、サロゲートキーに置き換えてからBronzeへ流す。メダリオンを流れるデータには個人情報が一切含まれず、PIIは鍵付きのPrivate Schemaに隔離して管理します。
登壇者が強調していたのは、この設計の副次的な効きどころです。PIIが少数のテーブルに集約されているため、GDPRに基づく削除リクエストへの対応が圧倒的に楽になる。「対象テーブルが数えるほどしかない」という状態を設計段階で作っておく発想は、個人情報を含むクライアントのデータ基盤設計でも活用できる知見だと思いました。
基盤の心臓部:約60種類のIDを束ねるアイデンティティ解決
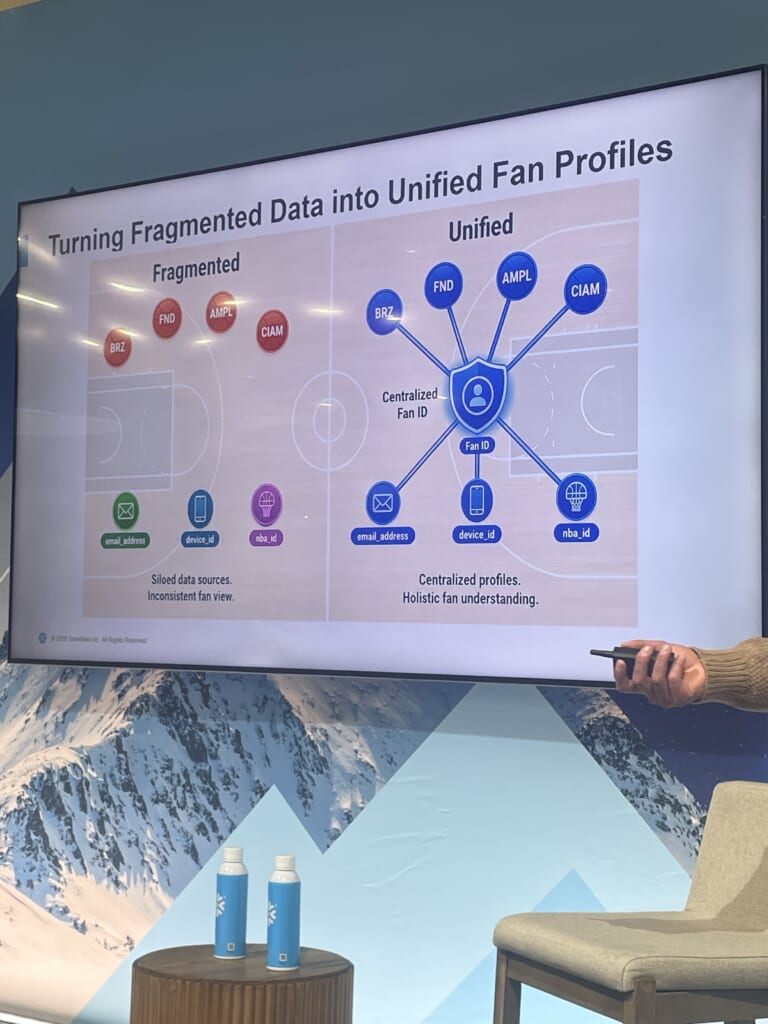
登壇者が「entire platformのbackbone(基盤全体の屋台骨)」と表現したのが、断片化したIDを一意のファンに紐づけるアイデンティティ解決です。
ここが見た目以上に難しく、email、device_id、nba_id…とID種別は約60あり、しかもすべてのIDを送ってくるソースも、すべてのソースに現れるIDもない。さらに、登壇者が釘を刺していたのが「同じデバイスを2回見たからといって、2人を同一人物として結合してはいけない」という点です。IDには確度の階層があり、デバイスIDしかない場合と、より確かな情報がある場合とで、扱いを変える重み付けモデルが必要になります。
その解決方法は、全ID値のグラフを構築し、重み付けルールでクラスタを見つけ、クラスタを1人のファンとみなすというもの。これをSQLとSnowparkで構築し、毎晩数千万件の新規レコードを処理しているとのこと。名寄せロジックを外部ツールに頼らず、Snowflake内で完結させ、この規模で夜間バッチを実行している点が技術的なハイライトでした。
事例:広告内製化とデータ共有
FDPの価値は「活用(アクティベーション)」にあります。セッションでは2つの事例が深掘りされました。
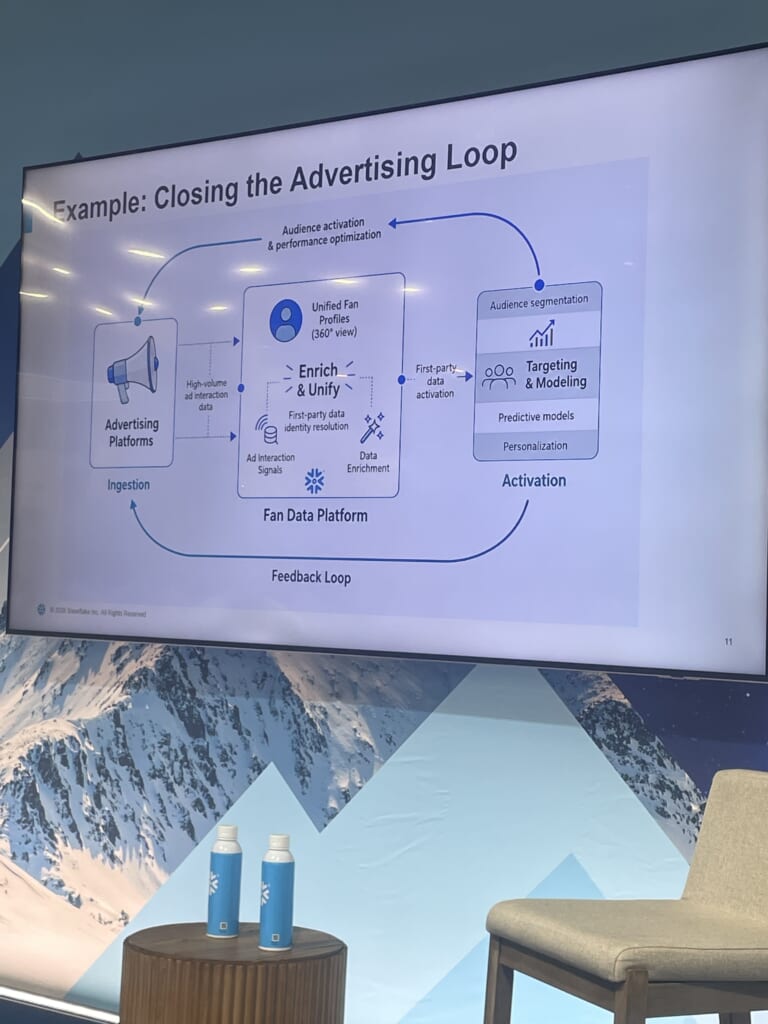
1つ目は広告の内製化です。2年前まで外部委託していた広告業務をほぼ内製化し、広告インタラクションデータを取り込んでプロファイルにエンリッチ、セグメントを広告側へ送り返すループを構築しました。
ここで興味深かったのが、運用の変化です。当初は、セグメントの作成・送信までエンジニアが関与していましたが、それでは新セグメントのたびにエンジニアが動く必要があり、明らかにスケールしません。そこで提供データを合意のうえで整え、セグメント作成はステークホルダー自身が行えるセルフサービス型へ移行しました。内部統制(boxes)も満たしつつ、エンジニアをボトルネックから外したという話は、運用設計の観点で非常に参考になりました。
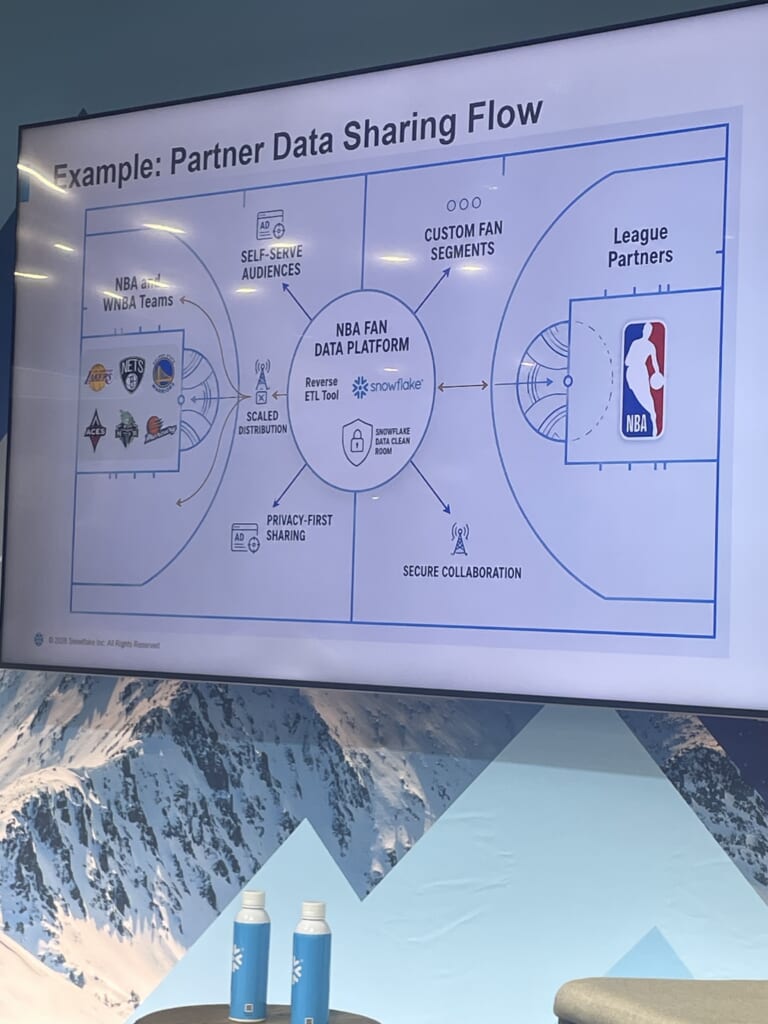
2つ目はデータ共有です。中央のFDPから、リバースETL / Snowflakeデータシェアリング / Data Clean Roomを使い分け、NBA・WNBA(女子NBAリーグ)の各チームやリーグパートナーへ共有します。
特に、Clean Roomは「データのベン図」のように、双方がデータを持ち寄り、共通キーで結合した集合に対してのみ分析を実行できる仕組みで、メディアパートナーとの協業で使われているそうです。ここでも入口はエンジニア主導でも、徐々にビジネスユーザー主体のセルフサービスへ寄せていく、という一貫した方針が見えました。
事例:AI活用による基盤作り
AI活用においては「Clean Data Foundation(きれいなデータ基盤)」を土台に据える、というのが一貫した主張でした。なかでも実務的だと感じたのが、ファンプロファイルの拡充の例です。
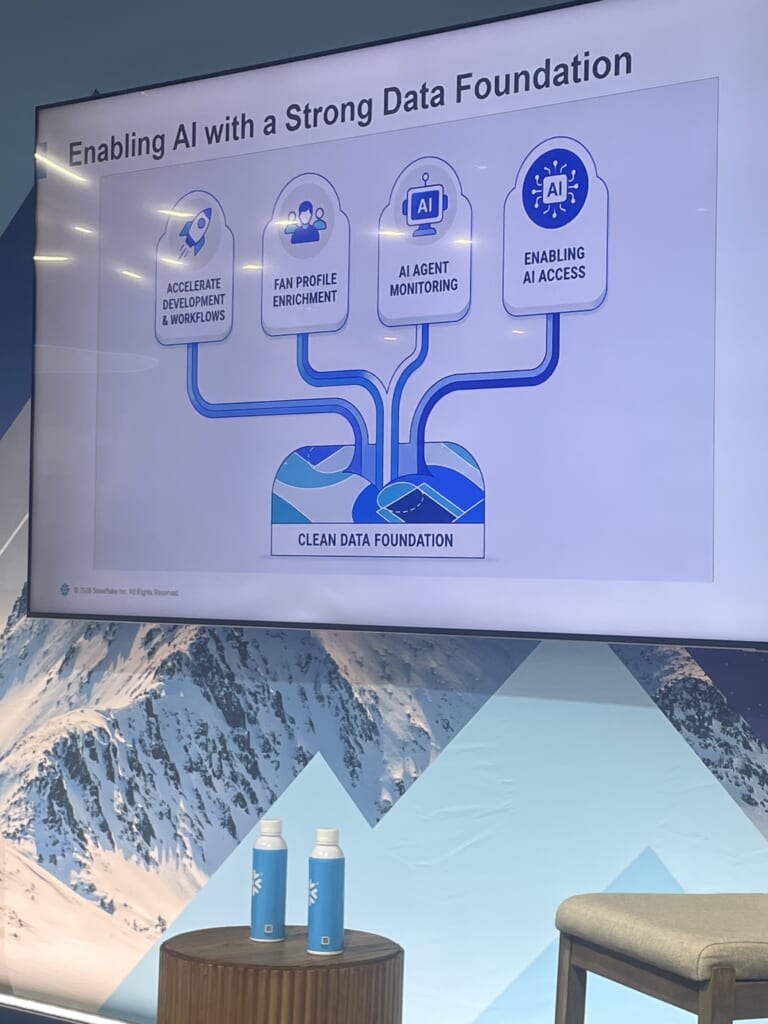
ベンダーから届く長い文字列の中に、選手名・チーム名といった抽出すべき値が埋もれている。これを従来は大量のCASE文で処理していたが、選手は毎年入れ替わるため運用負荷が高まりやすい課題がありました。そこをCortex関数に置き換えたところ、抽出率が向上し、管理もぐっと楽になったとのこと。「もともとNLPには懐疑的だった」と前置きしたうえでの実体験だっただけに、説得力がありました。自然言語まじりのデータを扱う現場なら、すぐに試せる勘所だと思います。
成果:4度の移行で得たものと課題
ここに至るまでの道のりも率直に語られました。印象的だったのは、各移行が「前の課題を解決しながら、同時に新しい課題を生む」という繰り返しだった点です。
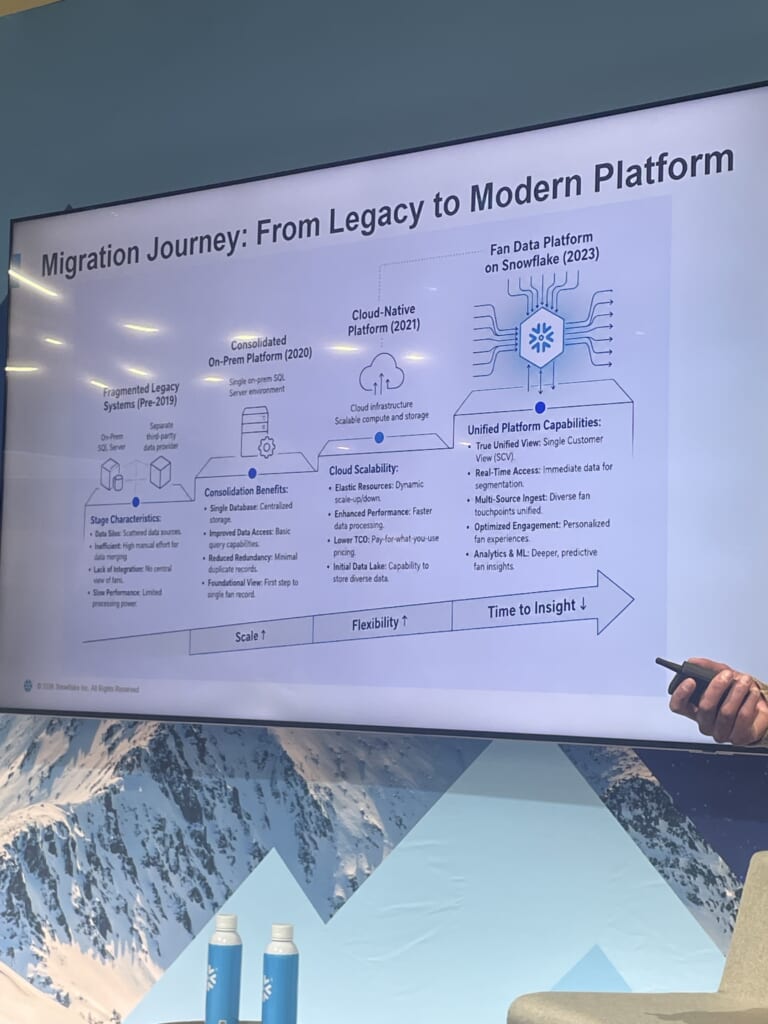
| 〜2019年・断片化レガシー | オンプレSQL Server+サードパーティ。チケッティング中心で、週1回のロールアップは元レコードに紐づけ直せなかった |
| 2020年・オンプレ統合 | 単一SQL Serverに集約(単一ファンレコードへの第一歩)。だが、初日からコンピュート不足に直面 |
| 2021年・クラウドネイティブ(Databricks) | コンピュートはスケール。ファンレベルへ再設計。一方で透明性とオーケストレーションに新たな課題 |
| 2023年・Snowflake | 真の統合ビュー(SCV)、リアルタイムアクセス、マルチソース取り込み、予測分析・MLを実現 |
「Scale ↑・Flexibility ↑・Time to Insight ↓ 」という軸で各段階を整理する見せ方は、移行の意思決定を振り返るフレームとして活用できそうでした。
きれいな一足飛びではなく、課題に押し出される形で段階的に進んできたという正直な語り口に、好感が持てました。
まとめ:少人数で巨大基盤を支える思想
セッションを通じて一貫していたのは、次の思想でした。
- ・複雑さは、ファンレベルで吸収する
- ・カスタムを避け、設定駆動・標準化で広い面を少人数で支える
- ・データのためにデータを動かさない。常にアクティベーションを見据える
- ・AIは、強固なデータ基盤の上にしか立たない
NBAという巨大で分散したエコシステムを少人数で運用できている背景には、こうした割り切りの徹底があるのだと実感しました。
規模やドメインが違っても、「負荷の山谷から逆算して設計する」「名寄せを基盤の中心に据える」「運用をセルフサービス化してエンジニアを外す」といった判断は、多くのデータ基盤づくりに通じるものだと感じたセッションでした。
このページをシェアする: