Snowflake Summit 2026 最速レポート Day3
【セッション解説】Beyond Chat – AIエージェントをガバナンスされたワークフローとして活用するために

目次
はじめに
こんにちは、DATUM STUDIOの鈴木です。
引き続き、Snowflake Summit 2026に参加しています。
Boomi社のAmy McNee氏が登壇したセッション「Beyond Chat: Activating Cortex Agents for Enterprise Productivity」(AI245)を聴講してきました。
Boomi(ブーミ) は、企業向けのiPaaSを提供するアメリカのソフトウェア企業です。セッションの内容はBoomi製品の紹介が軸でしたが、その根底にある考え方は、特定ツールに依存せず、Cortex AgentsはじめAIエージェントを本番運用したい人すべてに通ずる内容だと思いました。
本記事では、プロダクトの話は出典として最小限に留め、「エージェントをデモから実際の業務ワークフローに引き上げる設計原則」をCortex Agentsをテーマに整理したいと思います。
「水平」から「垂直」へ – ROIを向上させる使い方
エージェントの用途を説明するために、次の2点に分けた整理が理解しやすかったです。
- 1.水平(horizontal):
個人の生産性向上。チャットボット、コーディング支援、議事録要約など。便利だがROIが見えにくい。 - 2.垂直(vertical):
特定の業務プロセスに埋め込む。財務報告、請求書照合、解約予兆検知など。決算サイクル時間や対応時間といった指標で効果を測れる。
Cortex Agentsを活用するための最初の一歩は「何でも聞けるチャット」より、「測れる指標を持つ業務に絞る」方が価値を示しやすく、社内の予算取りや説得もしやすくなる、と述べていました。

設計の肝 – すべてをAIに任せない
個人的に一番刺さったのがここです。
ワークフロー設計において、Agentic(AIエージェント)に任せた場合と、Traditional(従来のシステム)にした場合を並べた比較は以下のとおりです。
| Agentic | Traditional | |
| 正確性 | ばらつく | 100%正確 |
| 応答速度 | 秒 | マイクロ秒 |
| スケール時のコスト | 1,000トークンあたり高額 | 1クエリ1セント未満 |
| 入力の柔軟性 | 曖昧な形式もOK | NG |
結論として、「スケール可能でコンプライアンスにも対応できる企業システムは、この表の左側(Agentic)だけでは実現できない」という話でした。
登壇者のエピソードも印象的でした。地域ごとの製品提供可否を返す社内ツールをSQLで作ったところ、「なぜAIを使わないのか」と聞かれたそうです。
それに対して彼女は「マイクロ秒単位で、ほぼコストをかけずに結果を返せるクエリを、わざわざ30秒かかってトークン課金も発生するLLMに置き換える理由があるでしょうか?」と答えたそうです。
Agentic Codingに関する学びとしては、Cortex AISQLやAgentsはトークン課金に加えてウェアハウス課金も発生します。また、Snowflake CoWork(旧:Snowflake Intelligence)のようにAgentsを介する構成では、追加のオーバーヘッドが発生する可能性もあるため、コスト試算時には注意が必要です。
つまり、最も大きなコスト最適化は「LLMを使わない」という判断そのものにあります。明確なルールで解決できるものは、無理にAIを使わず、シンプルな仕組みで解決するべきだということです。
AIを使う場所は絞る – ワークフローを分解して考える
では、AIはどこで使うべきなのでしょうか。財務報告ワークフローの分解例がとても分かりやすかったため、以下に整理します。
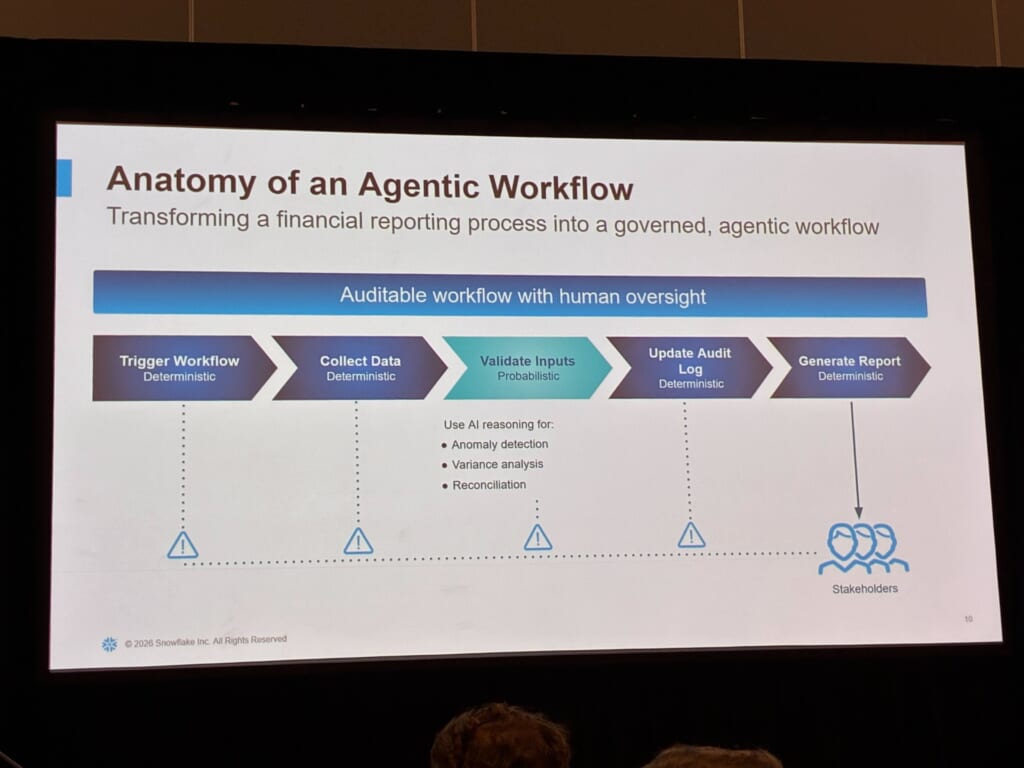
1.ワークフロー起動(ルールで処理) → 2.データ収集(ルールで処理) → 3.入力の検証(AIによる判断) → 4.監査ログ更新(ルールで処理) → 5.レポート生成(ルールで処理)
上記5ステップのうち、AIによる推論を使うのは「3.入力の検証」だけです。ここで異常検知、差異分析、突合を行い、それ以外の処理はルールに沿って確実に動くように設計します。全体としては、監査できる状態を保ちつつ、人間が監督できる仕組みにします。
設計上のポイントは「AIが判断する範囲を、できるだけ小さくする」という考え方です。Cortex Agentsであれば、Plan → Tool → Reflect → Respondのループの中でも、できるだけUDF、Stored Procedure、Cortex AnalystによるSQL生成など、決定的な処理が可能なツールに寄せる。その上で、LLMが自由に判断できる範囲はガードレールで制限します。
ここで重要なのは、ガードレール(触れてよいシステム / 自動解決してよい範囲 / 人にエスカレーションする条件)を口頭のルールで済ませず、設計成果物として明文化しておく必要があると述べていました。
個別運用ではなくガバナンス – エージェント全体を1つの面で見る
最後のテーマはガバナンスでした。エージェントが個別に増えていくと、不整合が起きやすくなり、管理も難しくなります。また、人の目が届かないまま自律的に動いてしまうリスクもあります。一方で、ガバナンスされたワークフローであれば、動きを予測しやすく、監査もしやすく、スケールにも対応しやすくなります。
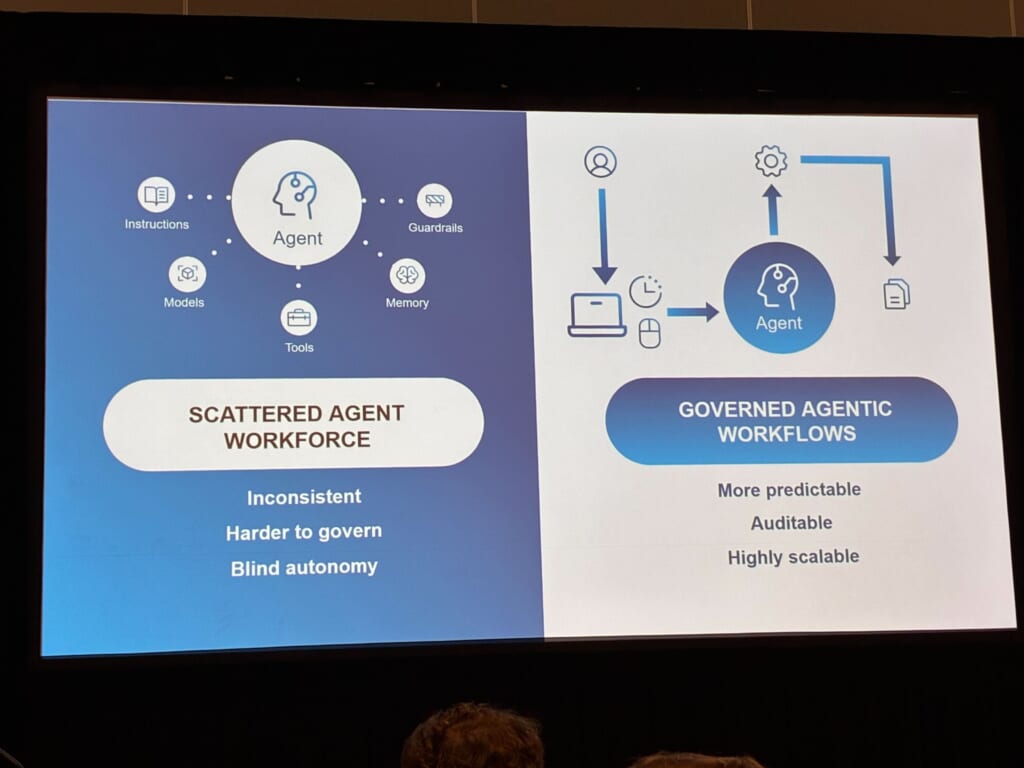
実際の環境では、Cortexだけでなく、Bedrock、Copilot、自作エージェントなど、複数のプロバイダーのエージェントが混在することもあります。そのため、ガバナンスは単一ベンダーの中だけでは完結しません。
セッションでは、1.Centralize(一元登録) / 2.Observe(呼び出し・トークン・実行時間・異常・ログ追跡を観測) / 3.Control(一時停止・再開・停止)という枠組みが示されていました。
この3点は、自社で運用する場合にも参考にしたいチェックリストだと思いました。
Cortex Agentsの文脈では、外部クライアントからの接続を統制するSnowflake-managed MCP serverや、クエリ・課金まわりの観測機能と組み合わせて、横断的なコントロールプレーンをどう設計するかが次の論点になりそうです。
AIエージェントを実務へ有効に取り込むために
「Beyond Chat(チャットの先へ)」が示していたのは、個人向け対話型AIサービスの便利さの先にある、効果を測定でき、監査でき、スケールするワークフローでした。
実務に活用できる要点は、次の5つです。
- 1.垂直の業務と測定可能な指標から始める:
水平の便利ツールは、ROIが見えにくくなりがちです。 - 2.すべてをAIにしない:
ルールで処理できる部分は、SQLやツールで処理することがコスト最適化につながります。 - 3.AIは、判断が必要な箇所に絞って使う:
その周囲は、決まった処理、監査ログ、人間の監督で固めます。 - 4.ガードレールを明文化する:
アクセス範囲、自動解決してよい範囲、エスカレーション条件を設計として残します。 - 5.エージェントの数が増える前提で設計する:
複数プロバイダーを横断して、「登録・観測・制御」ができる状態を作っておくことが重要です。
個人的には、エージェントの本番運用は「インフラ層(MCPなど)」「ガバナンス層(横断管理)」「業務適用層(本セッションで言う垂直ユースケース)」の3層で捉えると整理しやすいと感じました。今回のセッションはその中でも、特にガバナンス層に焦点を当てた内容だったと思います。
結局のところ、最も響いたのは「エージェントを作るのは簡単、難しいのはその先」というシンプルな一点でした。どこを決定的に固め、どこにAIを差し込み、誰がそれを見張るのか。華やかさはないですが、本番で効くのはこの設計の“地味さ”なのだと改めて感じます。こうした論点を、具体的なプロダクトの文脈で示してくれたセッションでした。
気づけばSnowflake Summit 2026も残すところあと1日となりました。最終日も注目しているセッションに参加し、引き続き多くの学びを持ち帰りたいと思います。
このページをシェアする: