Snowflake Summit 2026 最速レポート Day3
【セッション解説】 January Technologiesに学ぶ、Snowflakeでのエンタープライズ向けMLOpsのベストプラクティス

目次
はじめに
DATUM STUDIOの唐内です。
サンフランシスコで開催中の「Snowflake Summit 2026」のセッション「Best practices for enterprise-ready MLOps with Snowflake(ML302)」をレポートします。
登壇は、SnowflakeのApplied Field EngineerであるAllie Paris氏と、January Technologiesのデータサイエンティスト Thomas Spring 氏です。「数百万人の利用者に影響するMLモデルを毎日10種類運用する小規模チームが、外部のMLOpsツールを一切使わず、Snowflakeの機能だけで信頼性をどう担保したか」という、実装に踏み込んだ事例セッションでした。
課題:「ノートブック運用」からの脱却
January Technologiesではもともと分析基盤としてSnowflakeを使っており、MLもそのまま「Snowflakeのノートブックを開いて試す」というスタイルで始めたそうです。
データを動かさずに済み、既存の変換ロジックや権限をそのまま再利用でき、立ち上がりが速い。規制の厳しい消費者金融という業種で、すでに監査を通った信頼のおけるベンダー上で完結できる安心感もある。ここまでは、多くのデータサイエンティストが共感するところだと思います。
問題はその先でした。各人が思い思いにノートブックを書くため、モデルごとに作りがバラバラで再現性がなく、レビューも変更履歴も残らない。極端に言えば、ノートブックにアクセスできる人ならば、誰でも本番モデルを書き換えられてしまう。数百万人の利用者に影響するモデルを預かる以上、この状態は許容できません。
整理された要件は、標準化・ガバナンス・保守の3つです。つまり「立ち上がりの速さ」を保ったまま、ソフトウェアエンジニアリングの規律をMLに持ち込めるか、という問いです。

January Technologiesが出した答えは、新しいMLOps SaaSを導入することではなく、Snowflakeの既存機能を組み合わせてCI / CD付きのフレームワークを自作し、モノレポにまとめることでした。
設計の肝は次の3点に集約できます。
解決策(1):環境分離
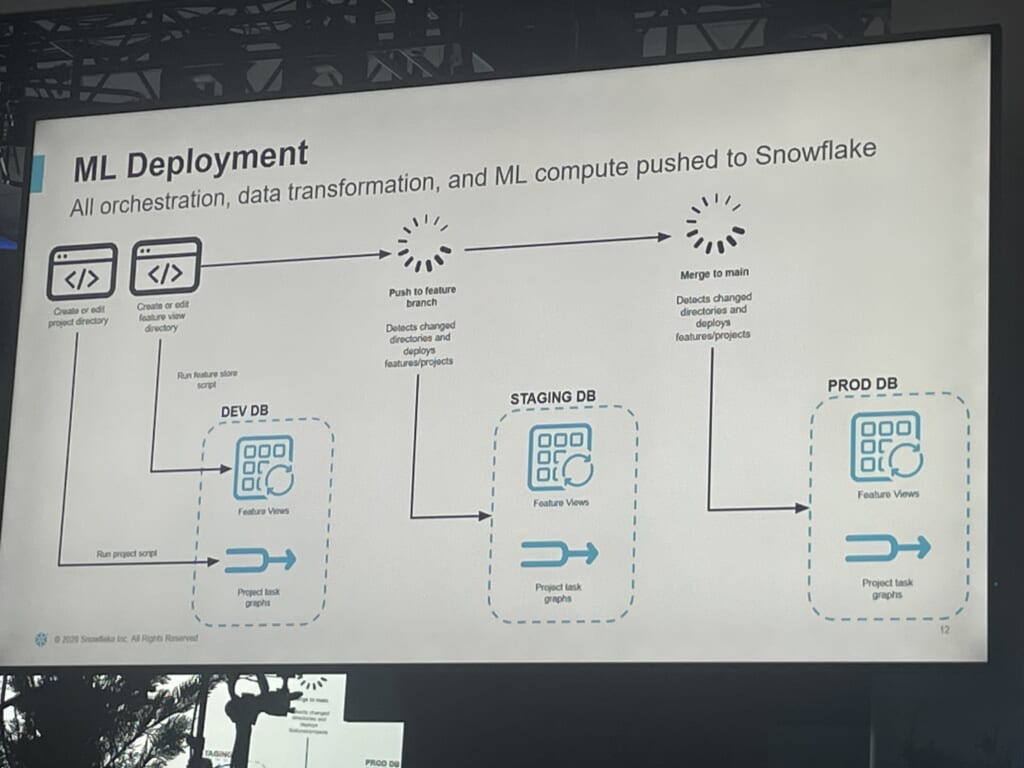
まず、各モデルを独立したプロジェクトとして扱い、Dev / Staging / Prodをデータベース単位で分離します。共有する特徴量はFeature Viewにまとめ、featureへのpushでStagingへ、mainへのマージでProdへデプロイされる、という素直なGitフローに乗せています。
ここで効いているのが、Staging / Prodへのアクセスをサービスユーザーに限定している点です。人間が本番DBを直接操作できないので、「誰でも書き換えられる」という最大の不安が、運用ルールではなく構造として塞がれます。ガバナンスにおいて「気をつける」だけで担保しないのが重要なポイントだと感じました。
解決策(2):GitHub Actionの工夫
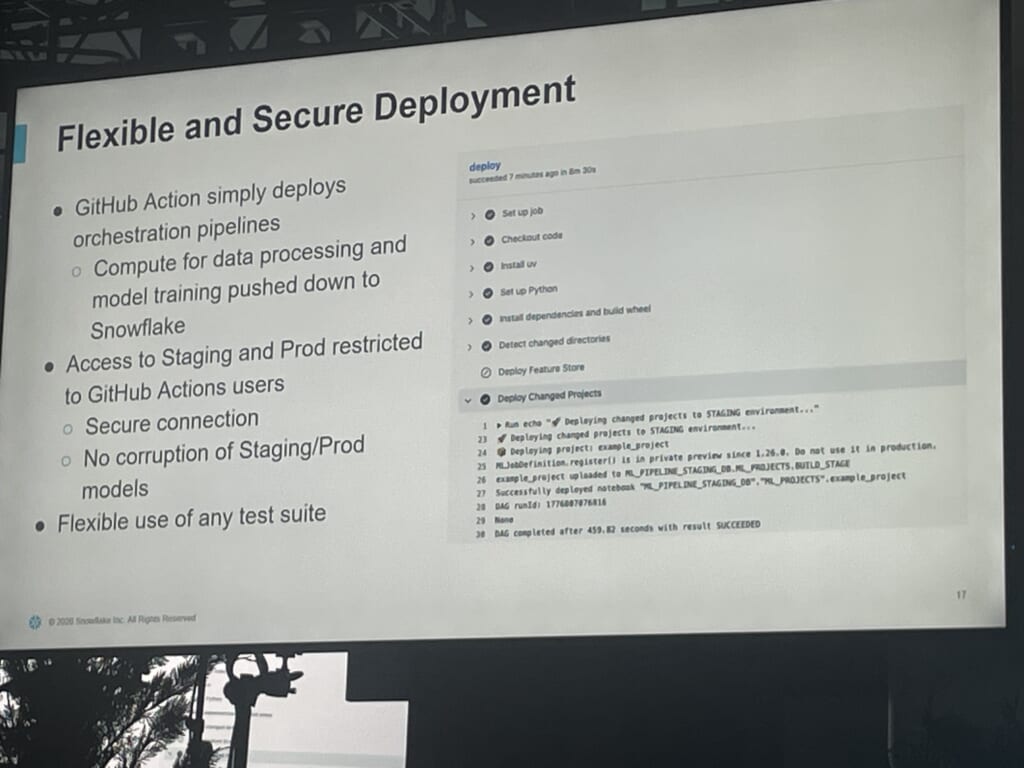
2つ目の肝が、GitHub Actionの工夫です。January Technologiesの設計ではGitHub Actionsはオーケストレーションのデプロイのみを担当します。実際のデータ処理やモデル学習のコンピュートは、すべてSnowflake側にプッシュダウンされます。
これにより、本番データを外部に持ち出さずに済み(セキュリティ要件をそのまま満たせる)、GitHub側のスクリプトは軽量に保てます。テストスイートはSnowflakeに縛られず、好きなものを使える柔軟性も確保されており、「ガバナンスを締めると柔軟性が犠牲になる」という、よくあるトレードオフをうまく回避しています。
解決策(3):YAMLによるタスク宣言
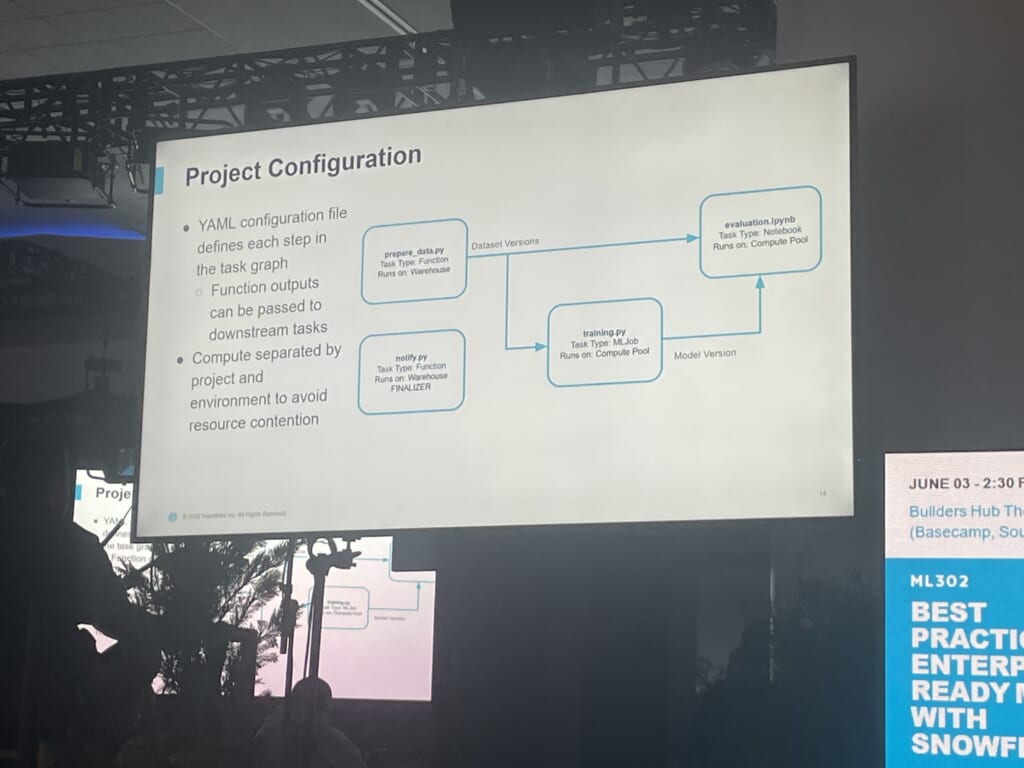
3つ目はタスク宣言です。新規モデルは、好きなIDEでリポジトリにフォルダを作り、YAMLでタスクグラフを宣言するだけ。前処理 → 学習 → 評価という依存関係と、各ステップが「Warehouseで動くのか、Compute Poolで動くのか」を記述し、タスク間で出力を受け渡せます。各タスクの中身はあくまで普通のPythonファイルなので、SnowflakeのML機能を自由に活用できます。
セッションでは、AIアシスタントに「このスクリプトに実験トラッキングを追加して」と指示するだけで、既存のtraining.pyを読み込んでtrain_func内に組み込むデモも披露され、AIツールとの親和性の高さもアピールされていました。
運用:3層モニタリング
デプロイして終わりではなく、運用の可観測性もSnowsightだけで完結しているのが印象的でした。
監視は、次の3つの粒度で用意されています。
1つ目は、タスク単位で、各ステップの成否・実行時間・戻り値をタスクグラフ上で追えます。
2つ目は、コンテナ単位で、MLジョブやノートブックのCPU・メモリを時系列で確認できます。
3つ目が、モデル単位で、Model Registryのモデルにモニターを付ければ、精度・適合率・再現率をセグメント別に追えます。
特に3つ目で、性能が閾値を下回った際に通知や再学習パイプラインを自動起動できるようにすることで、January Technologiesは「数日後に異常に気づく」のではなく、事後対応のインシデントをゼロにできたと話していました。
バイアス検知の文脈でセグメント別比較が使えるのも、消費者金融という業種を踏まえると示唆的です。
効果:数日でのデプロイと「インシデントゼロ」
まとめとして示されたインパクトは明快でした。モデルは数週間ではなく数日でデプロイでき、セットアップは設定ファイルと1本のPRで完結。それでいてリネージは追跡され、本番への直接アクセスはゼロ、環境間のパリティも保たれる。事後対応のインシデントはゼロで、監視は完全自動。「速さ」と「堅牢さ」を二者択一にしなかったところに、この設計の価値が凝縮されています。

まとめ
このセッションの肝は、新しいツールを増やすのではなく、すでに信頼している基盤の機能を組み合わせて規律を作ったことだと思います。環境をDBで割って本番を構造的に守り、計算はプッシュダウンしてデータを外に出さず、パイプラインは宣言的に書くという、どれもSnowflakeを使い込んでいる現場なら、すぐに着手できる要素です。
なお、このフレームワークはJanuary Technologies専用ではなく汎用設計で、モノレポとして展開して自社のDev / Staging / Prod構成に合わせてカスタマイズできるとのことでした。「ノートブック運用から本番運用へ」のギャップに悩む多くのチームにとって、現実的な出発点になりそうです。
DATUM STUDIOでも、Snowflakeを活用したMLOps基盤の設計・構築をご支援しています。ご興味のある方は、お気軽にお問い合わせください。
https://datumstudio.jp/contact/contact01/
このページをシェアする: