Snowflake Summit 2026 最速レポート Day2
エンタープライズAIをスケールさせるには何が必要か — 三井のフェデレーテッドAIメッシュ戦略から学ぶ

目次
はじめに
DATUM STUDIO データエンジニアリング本部長の菱沼です。
今年もSnowflake Summit 2026に参加しています。ついに5回目の参加となりました。日本勢の中だと今日紹介する登壇者の渋谷さんと同じく、最古参の一人のようです。
今年のSummitのコンセプトは The Agentic Enterprise(エージェント型エンタープライズ) ですね。
数多くのセッションのなかで特に印象に残ったのが、「Enabling Enterprise AI at Scale: Mitsui’s Federated AI Mesh」で、三井グループの矢口さんと、NTTデータの渋谷さんが発表されていました。
グローバルスケールでSnowflakeを活用したAI実装を語るケースは、Summit中のセッションでも依然として少数派です。
このセッションでは、三井グループが実際に直面した課題と、それを乗り越えるために採用した「フェデレーテッドAIメッシュ」という戦略が紹介されました。技術論だけでなく、組織論・ガバナンス論まで含んだ実践的な内容は、同様の課題を持つ多くの企業にとって参考になると感じました。
エンタープライズAI拡大の本質的な課題
現在、多くの企業が直面している移行局面を一言で表しました。
「孤立したAIの実験から、エンタープライズ規模のAI活用へ」
AIをビジネスに組み込む上で最大の壁は、技術的な難しさではありません。AIとビジネスデータをいかに密接に結びつけながら、組織全体にスケールさせるか—この問いに対するアーキテクチャ的・組織的な答えを見つけることが本当の課題です。
三井グループが向き合ってきた固有の難しさを、次のように紹介しました。
| 多様な産業ポートフォリオ | エネルギー、資源、金融、物流など、業種が異なるグループ会社が混在 |
| グローバル展開 | 日本・米国・各地域で、ビジネス優先事項や規制が異なる |
| 複数のデータソース | レガシーシステム、外部市場データ、非構造化ドキュメントなど、データの形式と所在が分散している |
これらを抱えながら「AIを全社に届ける」には、柔軟な組織構造とスケーラブルなデータガバナンスモデルの両方が必要になります。
フェデレーテッドAI戦略:3つのステップ
紹介されたのは以下の3段階で進化するアプローチです。

Step 1 ── 価値が重力を生み出す(Point)
まず、個々の部門やグループ会社が自分たちのビジネス課題を解くAI・分析ユースケースを具体的に作ります。ポイントは「中央集権的に作らないこと」です。
現場がユースケースの成果を実感すると、「うちのデータもプラットフォームに持ち込もう」という流れが自然に発生します。
Step 2 ── 成功事例を共有する(Line)
個別の成功事例が生まれたら、次はそれを孤立させずに接続して共有します。統制を効かせながら組織をまたいだコラボレーションが生まれ、インサイトの共有が始まります。この段階で「データを持ち込むハードル」が下がり、参加が加速します。
Step 3 ── 価値がスケールして境界を超える(Network)
データ・アプリ・AIがプラットフォーム上でクロスし始めると、価値の性質が変わります。「特定部門のローカルな成果」から「グループ全体で再利用できるモジュール」へと昇華します。このフェーズになると、各ユースケースがグループ全体の資産として機能し始めます。
アーキテクチャの核心:「接続はするが、集約はしない」
セッションで最も印象的だったのがこの一言です。
“Connection without Centralization”(接続はするが、集約はしない)
アーキテクチャは3層で構成されています。
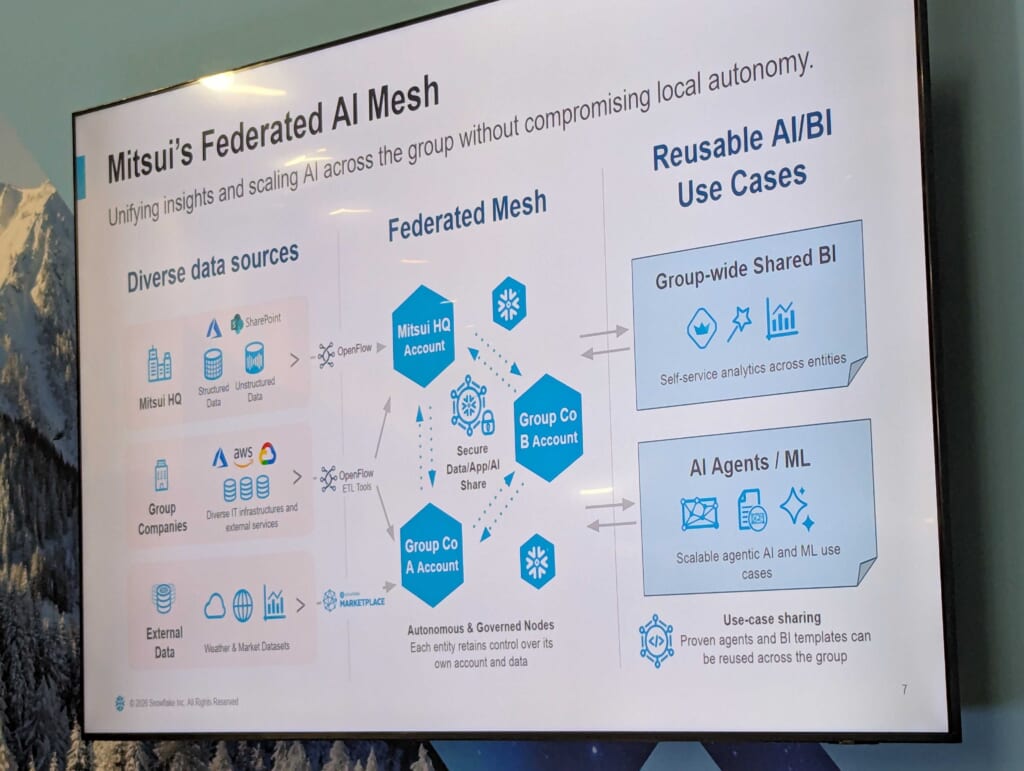
[左] データソース層
構造化データ(レガシーシステム、グループ会社DB)
非構造化データ(報告書、市場情報、外部ドキュメント)
↓
[中] 生成AI層
Snowflake上のCortex AI
↓
[右] 再利用可能なAI/BIユースケース
グループ横断の共有BI
各種エージェント、機械学習ユースケース
重要なのは、すべてのデータを一か所に集める必要はないという設計思想です。
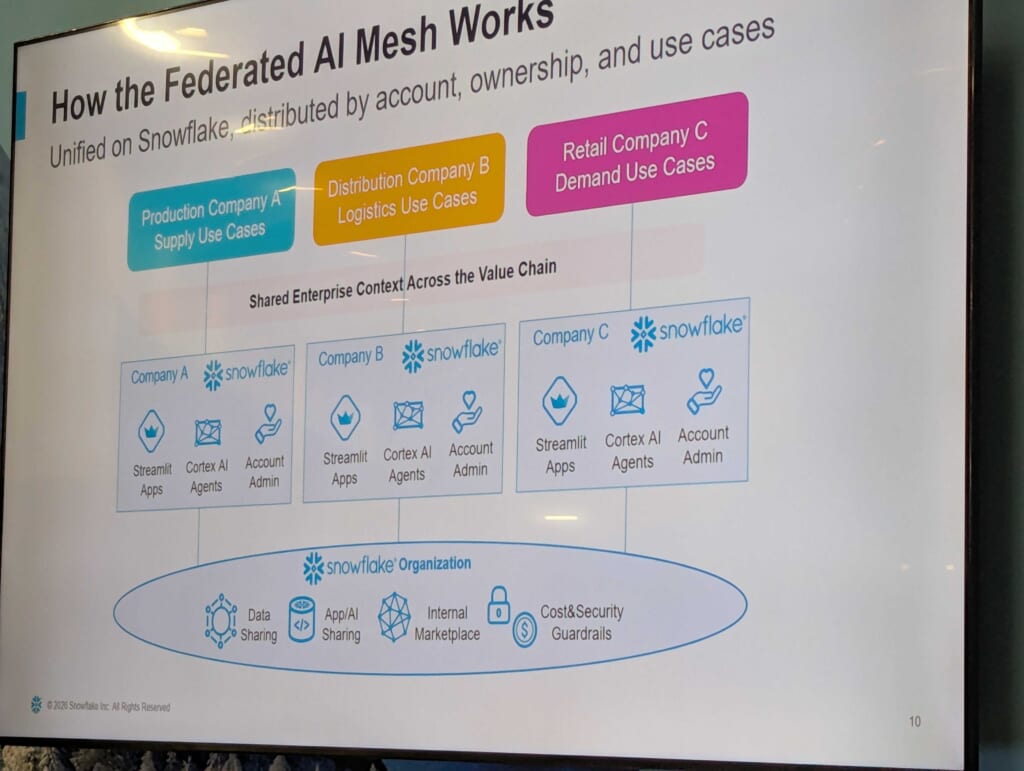
Snowflakeのセキュアデータ共有(Secure Data Sharing)を活用することで、データを物理的に移動・複製せずに、組織間でデータ・アプリ・AIを安全に共有できます。現在、三井グループはグローバルで100以上のSnowflakeアカウントを単一のSnow Organization配下で管理しています。たとえば、サプライチェーンにおける連携は次のようになります。
| 会社種別 | 共有するデータ |
|---|---|
| 生産会社 | サプライ信号(在庫・製造状況) |
| 流通会社 | 物流データ |
| 販売会社 | 販売データ |
これらのデータを一か所に集めることなく「エンタープライズコンテキスト」として接続することで、グループ全体がひとつの統合チームとして機能できます。
ビジネス主導のエージェント開発
スケールするAIにとって重要な点として強調されたのは、エージェント開発の課題が「技術」ではなく「コンテキスト」にあるという点です。
「難しいのは技術的な実装ではなく、ビジネスユーザーがどのようにデータを使い、AIエージェントにコンテキストを提供するかを理解することだ」

この課題を解決するために採用したアプローチが「ビジネス主導のエージェント開発」です。ビジネスユーザー自身がコンテキストを提供できる仕組みを整備することで、エンジニアのボトルネックなしにエージェントを量産できる体制を構築しました。
結果:
過去4週間で、30以上のエージェント開発、 150以上のAIユースケース、100以上の事業部門とグループ会社がプラットフォームを通してAIエージェントを利用しました。
AI採用の形態も「機能別(特定チームが担当)」から「分散型(各部門が自律的に展開)」へとシフトしています。
AIエージェントを用いた意思決定の強化
セッションの中では再利用可能なフレームワークとして、多様なビジネス形態をまたいでスケールする次の4つの例が紹介されました。

| エージェント | 役割 | ユースケース |
|---|---|---|
| 1.ナレッジエージェント | 過去の報告書・意思決定の蓄積知識を検索・合成 | 「過去5年間の類似案件の意思決定プロセスを教えて」 |
| 2.ポートフォリオ管理エージェント | 事業ポートフォリオのリスク特定・資料作成支援 | 「このポートフォリオのリスクをまとめて、ディスカッションポイントを作成して」 |
| 3.データ分析エージェント | 構造化・非構造化データを組み合わせた市場分析 | 「エネルギー市場のトレンドについて構造化データと報告書を横断して分析して」 |
| 4.オフィスサポートエージェント | ビジネス文脈を理解した業務支援 | 「関連業務の文脈を踏まえて、このメールの下書きを作成して」 |
これらの共通した目標は、意思決定の迅速化と標準化であると説明されました。
フェデレーテッドAI メッシュがどのように動作しているか
AIとデータのパイプラインを支えるガバナンス基盤として、Snowflakeを用いて、以下の内容が整備されているそうです。
- ・アカウントガバナンス:100以上のアカウントを一元的に管理するポリシー
- ・アクセス制御:誰がどのデータにアクセスできるかの明確な定義
- ・共有基準:データ・アプリ・AIを共有する際のルール整備
- ・継続的改善:データ管理・AI領域へとサポートを段階的に拡大中
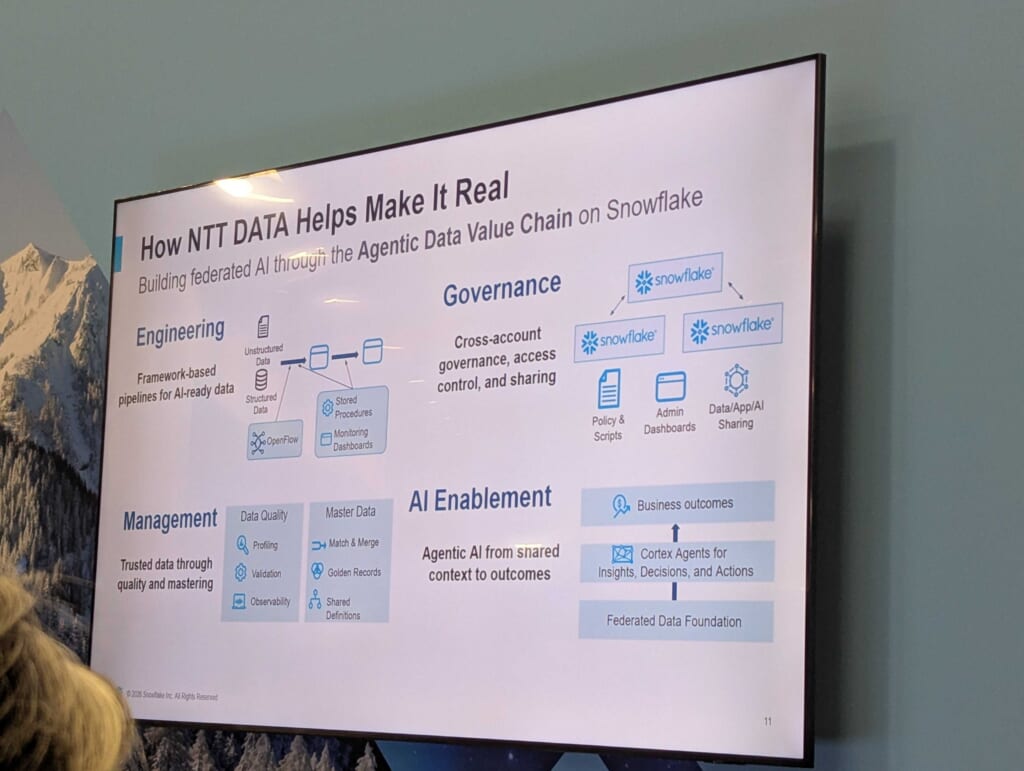
これらグローバルスケーリングを実現するために、NTTデータとのパートナーシップが重要な役割を担っていたそうで、日本・米国・各地域のデータスペシャリストとデリバリーチームが連携し、地域ごとの規制やビジネス優先事項に対応しながら一貫したAIジャーニーを支援する体制を構築して支援されたとのことでした。さすが渋谷さんたち…。
自分ごととしてのフェデレーテッドAIメッシュの今後の想像
このセッションで語られた取り組みは、まさに現在進行形のベストプラクティスです。そして今回発表された新機能群は、この戦略をさらに加速させる方向に揃っていると感じました。
ここからは私の想像で、Summit 2026で発表された新機能をこのアーキテクチャに取り入れていくとしたら、といったアイデアを書いていきます。
Cortex Sense ——コンテキスト提供の民主化の加速
このアーキテクチャで最も重要な要素のひとつが「ビジネスユーザーによるコンテキスト提供」です。
Cortex Senseは、データ・ビジネス定義・運用知識を自動で統合してAIエージェントへ供給する共有コンテキスト層と説明されていました。プリビルトのプラグインとMCPコネクタを備え、ビジネスユーザーが自分の知識をエージェントに登録できる仕組みを提供するそうです。
「ビジネス主導のエージェント開発」において、ビジネスユーザーのコンテキスト提供コストを劇的に下げるソリューションになり得ます。
Cortex Agent Sharing ——ローカル成果のグループ資産化
現在のアーキテクチャでは、AIエージェントを100以上のアカウントに展開するには相当な運用コストがかかります。Cortex Agent Sharingは、エージェントを他アカウント・パートナー・Marketplaceへ展開できる機能です(現在、パブリックプレビュー)。
Step 3の「価値がスケールして境界を超える」を技術的に実現する仕組みとして、すでに採用されているかも知れません。
CoWork(旧 Snowflake Intelligence)——全従業員へのAI浸透
ガバナンスされた単一インターフェースから、自然言語でデータアクセス・ワークフロー横断推論・アクション実行ができるCoWorkは、まさに「非エンジニアのビジネスユーザーがAIを使う」ためのフロントエンドです。Deep ResearchやMCP連携も備えており、ナレッジエージェントやデータ分析エージェントのユーザーインターフェースとして親和性が高いでしょう。
Open Sharing ——フェデレーテッドなデータ流通の加速
Open Sharing は、外部エンジンからSnowflake管理のIcebergテーブルへ双方向アクセスを可能にします。100以上のアカウントをまたぐカタログ管理と、Open Data Sharing(コピー・ベンダーロックインなし)の組み合わせは、「接続はするが集約はしない」というアーキテクチャ思想と完全に一致します。
Agent Identity ——エージェントの信頼性確保
各AIエージェントに検証済みアイデンティティを付与し、RBACと監査証跡を適用するAgent Identityは、エンタープライズでの大規模エージェント展開において必須の機能です。150以上のユースケースを管理する規模になると、「どのエージェントが何にアクセスしたか」の可視化と制御は不可欠です。
「エージェントからは参照専用」「エージェントには特定データは見せない」など、人間向けではないきめ細やかな制御が可能になります。
Cortex Training——グループ独自のモデル構築
MistralやQwen等のオープンウェイトモデルを、自社データで微調整・トレーニングできるCortex Trainingは、各社が保有する固有の業界知識(エネルギー市場、サプライチェーン等)をモデルに組み込む可能性を開きます。データを外部に出さずにフルマネージドGPU上で実行できる点も、ガバナンス観点で魅力です。
まとめ
このセッションから学んだ最も重要なメッセージは…。
- 1.「接続はするが、集約はしない」という思想の普遍性
データを一か所に集めることが目的ではなく、必要な場所で必要なコンテキストとしてデータが使える状態を作ることが目的。この設計思想は、組織規模や業種を問わず、適用できるはずです。 - 2.ビジネス主導のエージェント開発において、技術よりコンテキスト提供が鍵
「エンジニアが作る」から「ビジネスユーザーがコンテキストを提供してエージェントを育てる」へのシフトが、スケールの本質的な条件です。BIの世界であったようなセルフサービス化が、多様な領域へのエージェントのスケールを実現します。 - 3.Snowflake Summit 2026の新機能群はこの戦略を加速する方向に揃っている
Cortex Sense、Cortex Agent Sharing、Horizon Catalog、Agent Identityなど、発表された機能群は「フェデレーテッドAIメッシュ」を実装するための技術的なピースが揃いつつあることを示しています。
グローバルな多角化企業が、AIをエンタープライズスケールで実装するという難題に正面から向き合い、実績と共に語られたこのセッションは、同様の課題を持つ多くの企業にとって貴重なロードマップになると感じました。
このページをシェアする: