Snowflake Summit 2026 最速レポート Day2
Platform Keynote・JAPANレセプション紹介編

目次
- 1 はじめに
- 2 Platform Keynote
- 3 What’s New with Snowflake CoWork ―「自分専用の作業エージェント」へ
- 3.1 AIなしの一日と、目指す働き方
- 3.2 デモ止まりの3つの壁と、Snowflakeの3ステップ
- 3.3 全体像:「Agentic Control Plane」とCortex AIアーキテクチャ
- 3.4 「データと対話」から「自分専用の作業エージェント」へ
- 3.5 CoWorkの新機能(1) Personal Agent
- 3.6 CoWorkの新機能(2)Autonomous Agent
- 3.7 CoWorkの新機能(3)Dashboards & Collaboration
- 3.8 採用実績と自社活用(Raven)
- 3.9 デモ:一日の始まりを丸ごと
- 3.10 顧客事例:Wolfspeed ―「知って・大規模に解いて・実行する」AI
- 3.11 まとめ
- 4 What’s New: Connectivity for AI-Ready Pipelines, with AI
- 5 リアルタイムの瞬間をつなぐ「Snowflake Datastream」
- 6 Snowpipe Streamingの進化とExodusPointの事例
- 7 システム・オブ・レコードをAIエージェントへ「Zero-Copy Integration」
- 8 データライフサイクル全体をつなぐ「Openflow」
- 9 ファイルをより安価に取り込む「Snowpipe」とHUMANの事例
- 10 まとめ
- 11 夜は「JAPANレセプション」へ
はじめに
こんにちは。時差ボケと食べ過ぎ(前日編を参照)による胃もたれが続いている、ちゅらデータの菊地です。本日もSnowflake Summit 2026の最速レポートをお届けします。
2日目は、朝9時のPlatform Keynoteから始まり、その後は複数セッションをはしご、締めくくりは18時からのJAPANレセプションです。それでは、本日も張り切っていきます。
Platform Keynote
2日目の朝はPlatform Keynoteから。AI Data Cloudの全体像が熱く語られ、「4つのAct」で新機能が次々と紹介されました。
主役は、開発者向け「CoCo」とナレッジワーカー向け「CoWork」の2大エージェントです。Kafka互換の「Snowflake Datastream」、ガバナンスの「Horizon Context」、性能を底上げする「Adaptive Compute」など、発表は多岐にわたりました。架空企業「Snow Music」のデモでは、パイプライン障害をCoCoがその場で診断・修復してみせ、SpaceXとの提携発表も飛び出すなど、発表のたびに会場内が沸き、お祭りのようなキーノートでした。
※詳細は別記事で公開予定です。お楽しみに!

What’s New with Snowflake CoWork ―「自分専用の作業エージェント」へ
続いては「What’s New with Snowflake CoWork ― The Personal Work Agent, Built on Your Business」のセッションです。
旧・Snowflake Intelligenceが「Snowflake CoWork」へと進化し、データと対話するだけでなく、文脈を理解して読み書き・実行までこなす、”パーソナル・ワークエージェント”になった、という内容です。登壇はSnowflakeのWilliam Allen氏、Effie Goenawan氏と、顧客WolfspeedのUnni Velayudhan氏でした。

AIなしの一日と、目指す働き方
導入は、AIを使わない知識労働者の「ある一日」。朝に生データを集め、データの不整合に気づいてチケットを起票し、ダッシュボードを行き来し、最後はExcelとPowerPointで手作りし、上層部から別の切り口を求められてやり直し…。気づけば一日が終わり、ゴール設定していた意思決定にはたどり着かない、という流れです。
これからの働き方は、agentic・proactive・outcome-drivenであるべきで、人は自律型エージェントをsteering / governing / approvingする側に回る、と説明されました。

デモ止まりの3つの壁と、Snowflakeの3ステップ
多くの生成AIプロジェクトはデモの直後に止まる。
その理由は、
- 1.「No Shared Truth(指標や定義が、エージェント間でズレる)」
- 2.「No Governance Guardrails(ポリシー違反でIT / 法務部門に止められる)」
- 3.「No Business Context(価値が出るまで、数週間の手作業)」
の3点であると整理していました。

その答えとなるのが、次の3ステップです。
- 1.Agree on Reality(同じガバナンス下のデータ・指標・定義を、すべてのエージェントで共有)
- 2.Reason Over It(部分的なスナップショットではなく、全コンテキストでのオーケストレーション)
- 3.Act Coherently(すべての操作を、ガードレールと監査証跡の中で)
ガバナンス・データ・インテリジェンスが、既に一体である単一プラットフォーム、という主張です。

全体像:「Agentic Control Plane」とCortex AIアーキテクチャ
製品の中心に置かれるのが、Agentic Control Planeです。Snowflake CoWorkとSnowflake CoCoの2つのアプリが、AIモデル・社内データ&コンテキスト・ソフトウェア&アプリケーションをつなぐ、ハブを介して動きます。
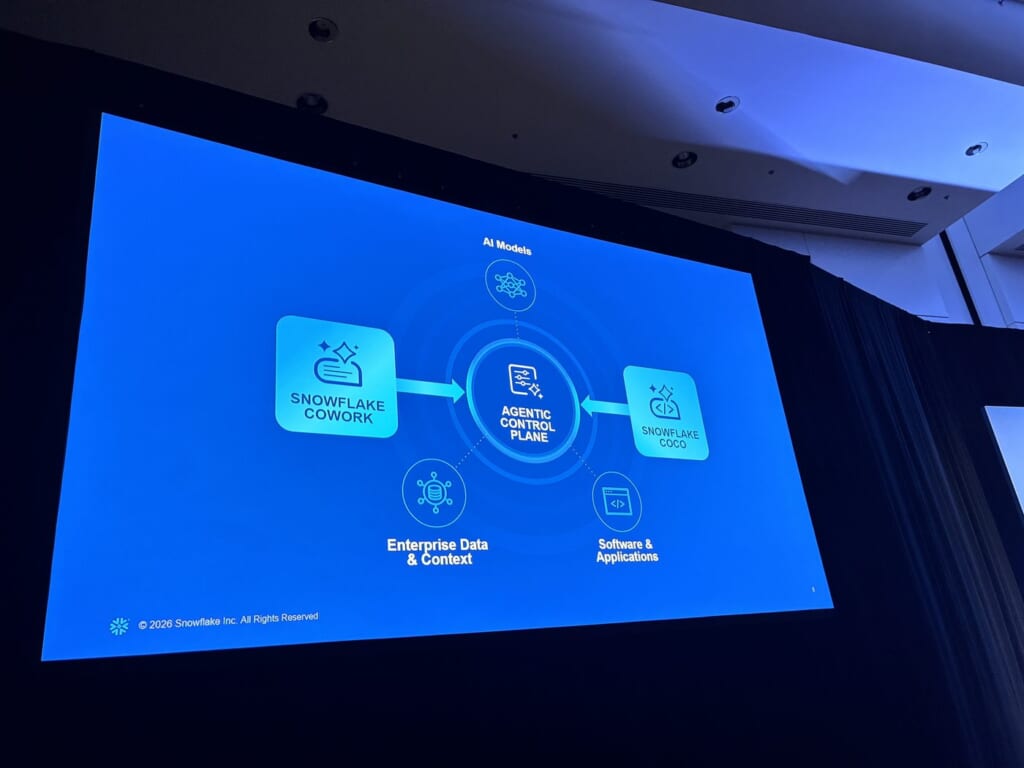
アーキテクチャは、APPS(CoWork / CoCo) / APIS(Cortex Agents / Cortex AI Functions) / CONTEXT(Cortex Sense Runtime・MCP & Connectors・Semantic Views・Business Logic)の3層です。
横断的にGovernance|Policy Control|Audit & Lineageが効き、基盤モデルはOpenAI・Anthropic・Gemini・Meta・Grok・Mistral AI・DeepSeek・Snowflakeから選べる構成です。

「データと対話」から「自分専用の作業エージェント」へ
旧・Snowflake Intelligenceは、読み取り専用のQ&Aで先にエージェントを選び、毎回ゼロから始める使い方でした。
CoWorkは読み書き・実行を行い、適切なエージェントへ自動でルーティングし(agent router)、ユーザーを記憶して学習します。位置づけは「One AI workspace」= 参謀長。メール・会話・社内データ・各種アプリ&MCPといった文脈を取り込み、資料・文書・ダッシュボード・メール・アクションといった成果へつなげます。

CoWorkの新機能(1) Personal Agent
新機能は、3本柱(Personal Agent / Autonomous Agents / Dashboards & Collaboration)で語られました。

1本目のPersonal Agentは、Sales / Finance / Ops / Productなどのサブエージェントと、Slack・Gmail・Jira・SalesforceなどのMCPツールを1つのエージェントに束ねます。動作は各ユーザーの権限の範囲内で、PDF・PPTX・高度な分析・スキルといった機能を備えます。
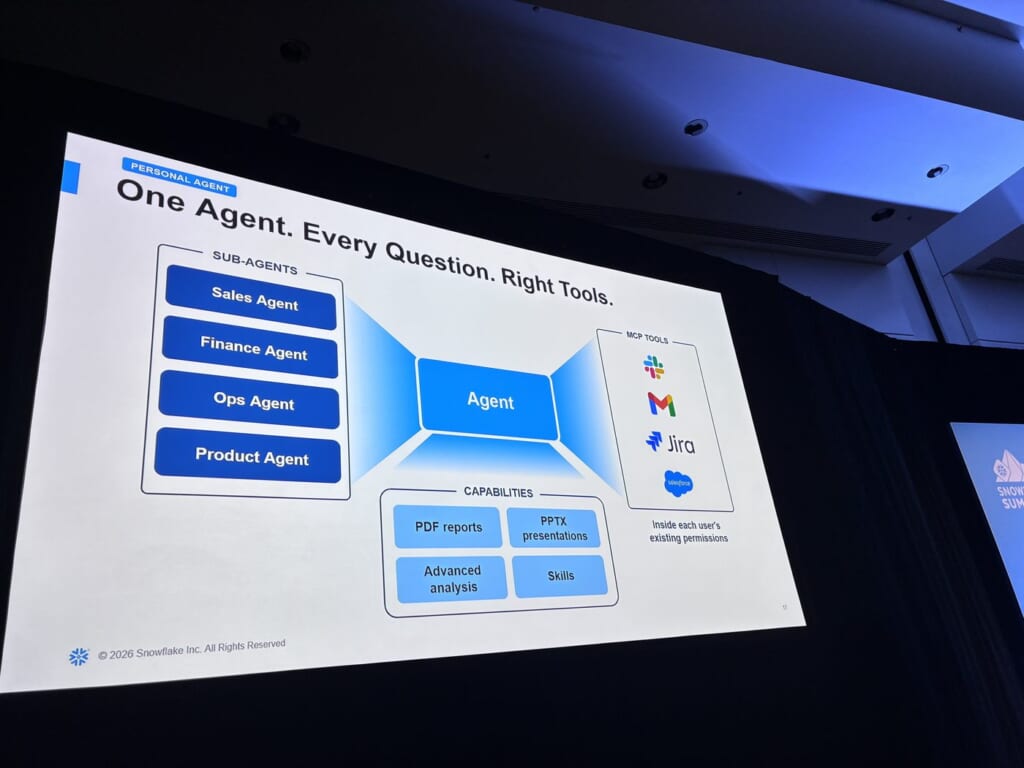
さらに、好みや役割・繰り返しタスクを横断して覚えるUser Memory、定型業務を一言スキル化して組織で共有できるUser Skills、Finance & Salesの事前バンドルであるPlugins、Face IDで開くことができ、フル機能が使えるiOSアプリも紹介されました。そのうち多くは、公開プレビューやGAが近い段階です。
CoWorkの新機能(2)Autonomous Agent
2本目は、自律エージェントです。Automationsは自然言語で一度設定するだけで、変化・理由・次アクション付きのブリーフィングを定期配信し、1クリックで追質問でき、RBAC・コスト可視化・監査証跡付きで動きます。
ダッシュボードでは届かない問いには、構造化+非構造化を横断するDeep Research(多段推論・全引用)と、大量の非構造化データへ定量クエリを投げるAnalytical Searchが対応しています。単一エージェント比で+52.2%の改善(CoWork’s Hybrid Deep Research Benchmark)と示されました。

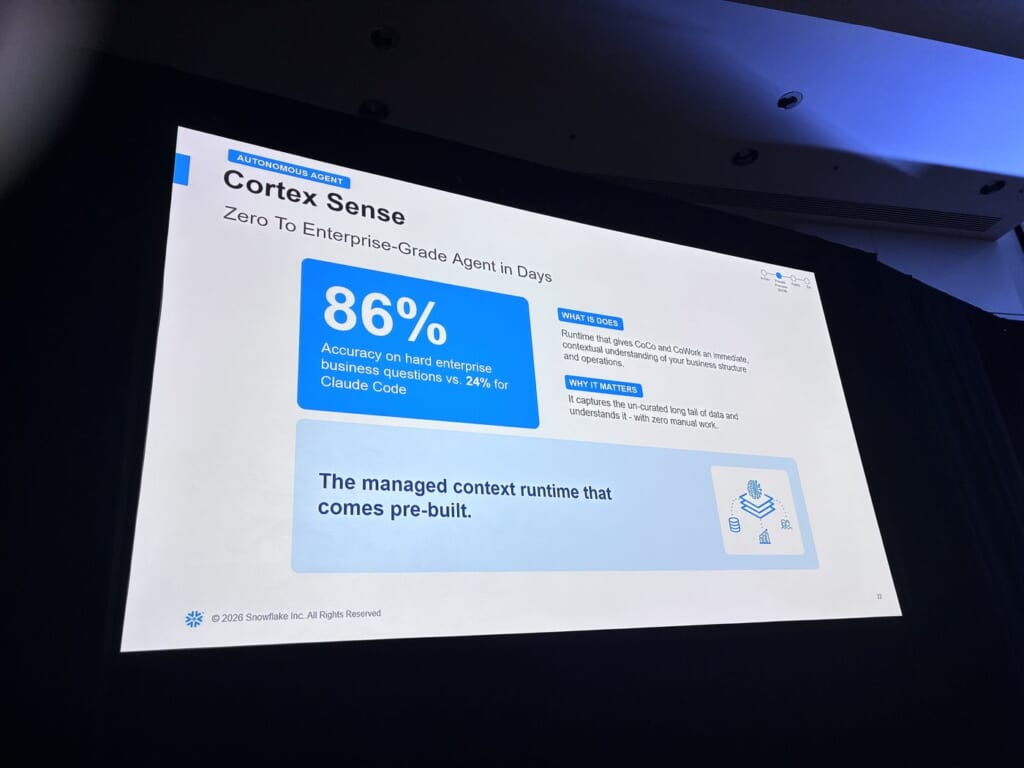
ゼロから数日で実運用級のエージェントにするCortex Senseは、難問の正答率がスライド上で86%(比較対象のClaude Codeは24%)と表示されていました。事前構築済みのマネージドなcontext runtimeと説明されました。
加えて、CoWork内で安全にPythonを実行し(データはSnowflake圏外に出ない)、PDF・PPTX・カスタム文書まで生成するCode Execution Toolも、紹介されました。
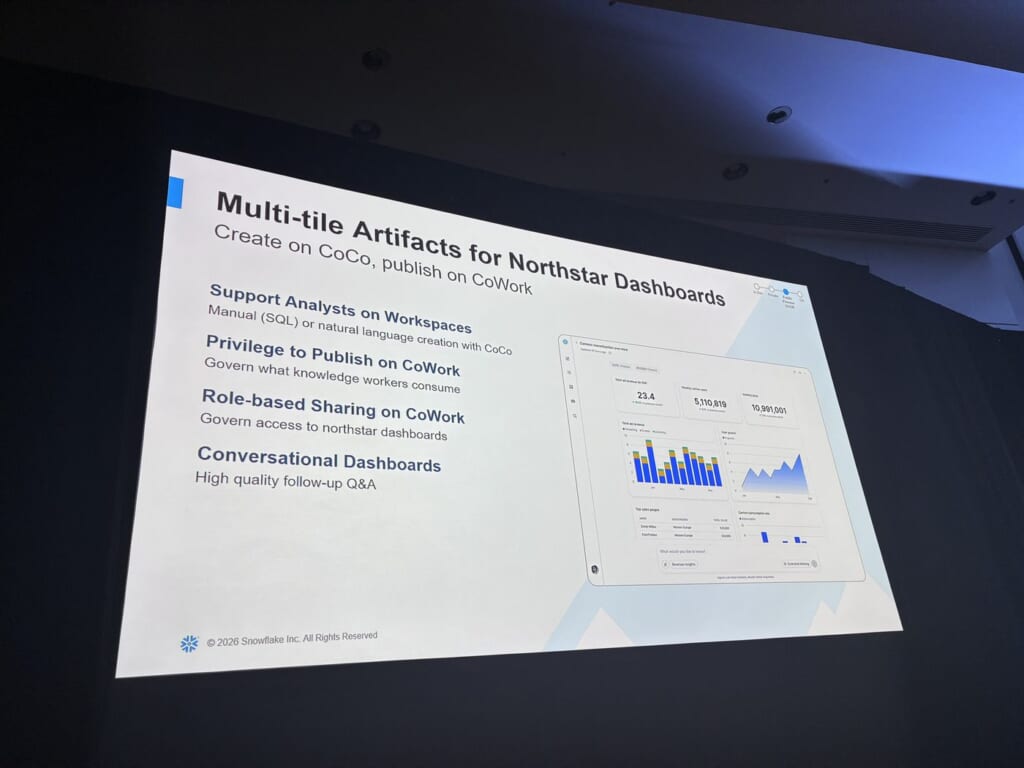
CoWorkの新機能(3)Dashboards & Collaboration
3本目はダッシュボードと共同作業です。データで更新され、閲覧権限を尊重するArtifacts、引用付きで静的スクショから脱却するConversation Sharing、ロール別RBACのマルチタイルnorthstarダッシュボードが示されました。northstarダッシュボードは、CoCoで作成しCoWorkで公開、という分担です。
採用実績と自社活用(Raven)
週次13,600アカウントがSnowflakeのAI機能を利用し、USA Bobsled and Skeletonからは、自然言語で具体的に問うことができ、選手向けの実行可能な示唆が得られる、という趣旨のコメントも紹介されました。
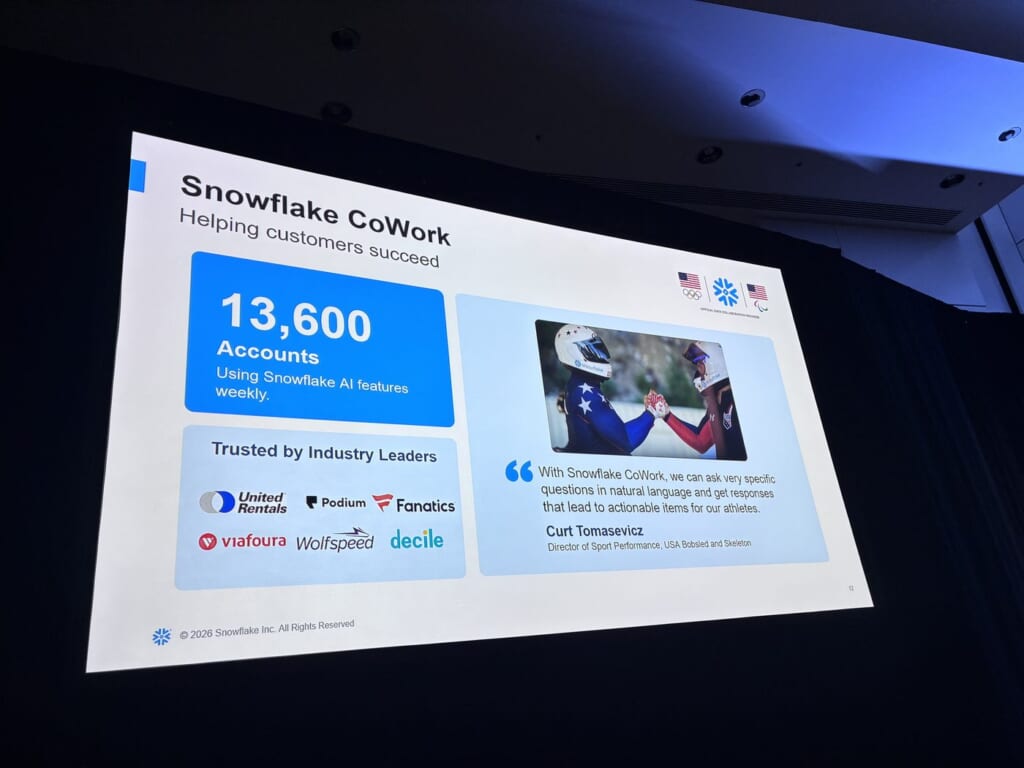
Snowflake社も自社で営業エージェント「Raven」を全社のgo-to-marketで活用されているそう。6,000人規模のGTM組織向けで、$16M+の間接費削減・>80 FTE相当の生産性回収・5x RoI・100万件超の質問、という数字が示されました。

デモ:一日の始まりを丸ごと
デモでは、Effie氏が営業リーダーになりきり「一日の始まり」を実演します。
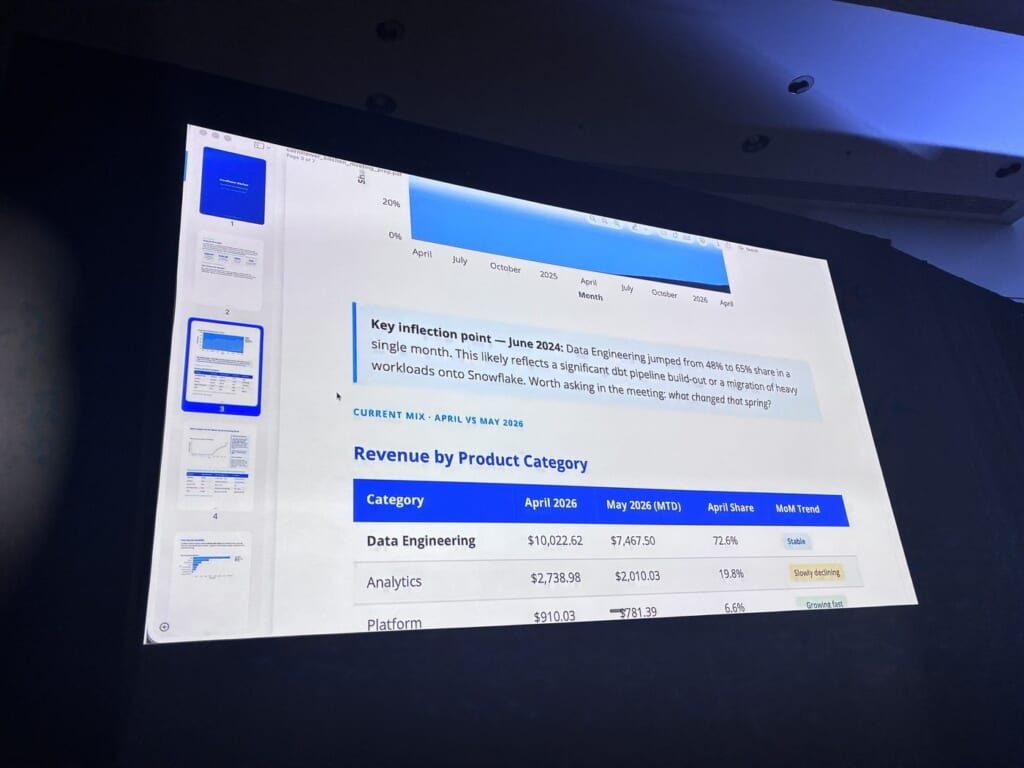
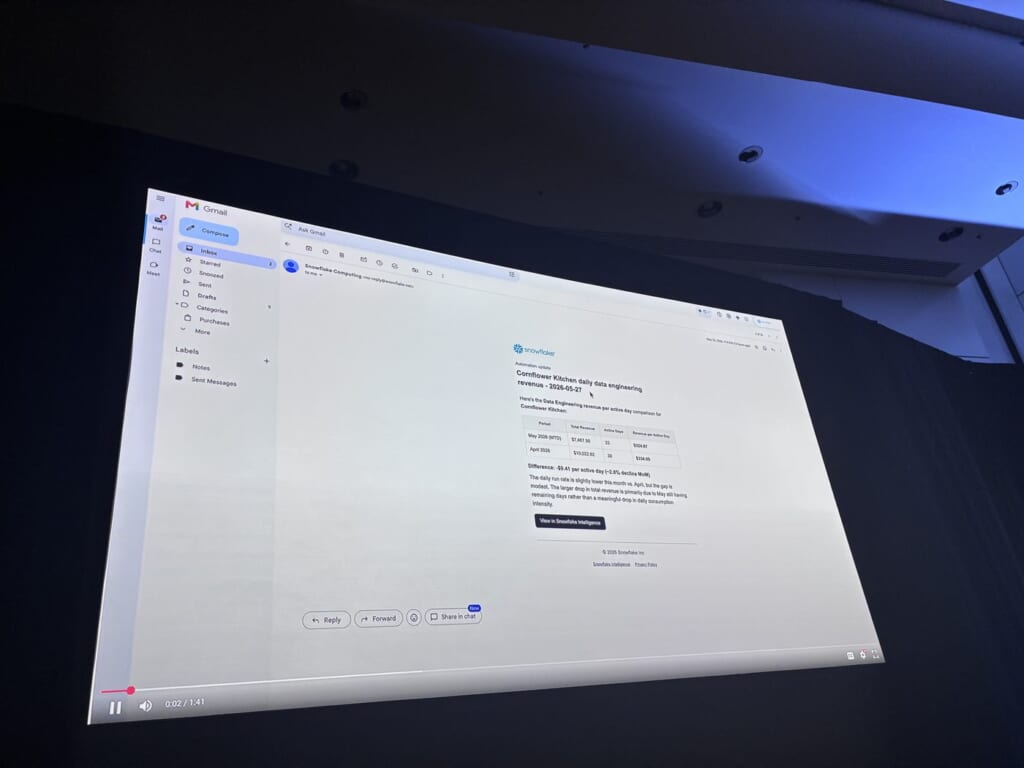
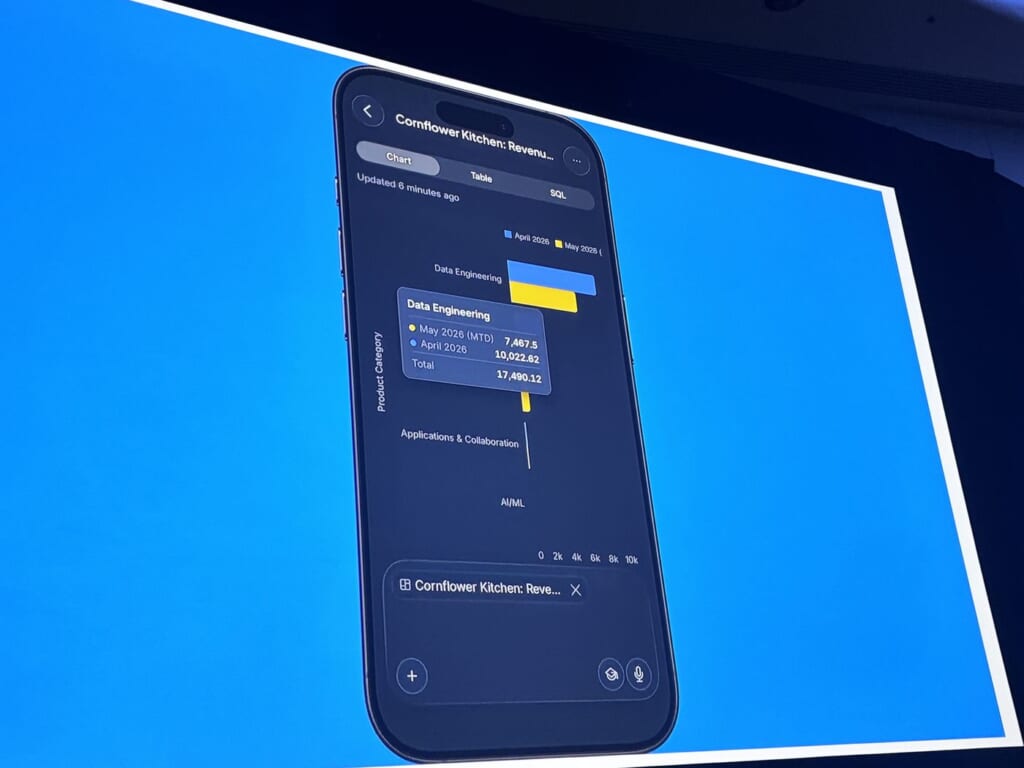
AutomationsからDeep Researchのレポートを開き、それをPDF化し、同僚へGmailで配信、ダッシュボードを自然言語で操作、最後はiOSアプリで外出先から継続―という一連の流れを、アプリを切り替えることなく実演していました。題材は架空顧客のCornflower Kitchenで、金額やクレジットはすべてデモ用に用意された例です。

顧客事例:Wolfspeed ―「知って・大規模に解いて・実行する」AI
後半は、顧客Wolfspeedの事例です。シリコンカーバイド(SiC)半導体メーカーで、原料結晶から完成パワーデバイスまで垂直統合し、AIデータセンター・産業用電源・自動車・航空宇宙&防衛・再生可能エネルギーに供給しています。

2021年以前はサイロ化していたデータを、2021年以降に統合データ&ガバナンスへ、2025年以降はEnterprise AI Knowledge Hubによるインテリジェンス層へと積み上げ、既存のデータガバナンスやセキュリティ体制を再利用しつつ、エージェント層にガードレールを足したと説明しました。
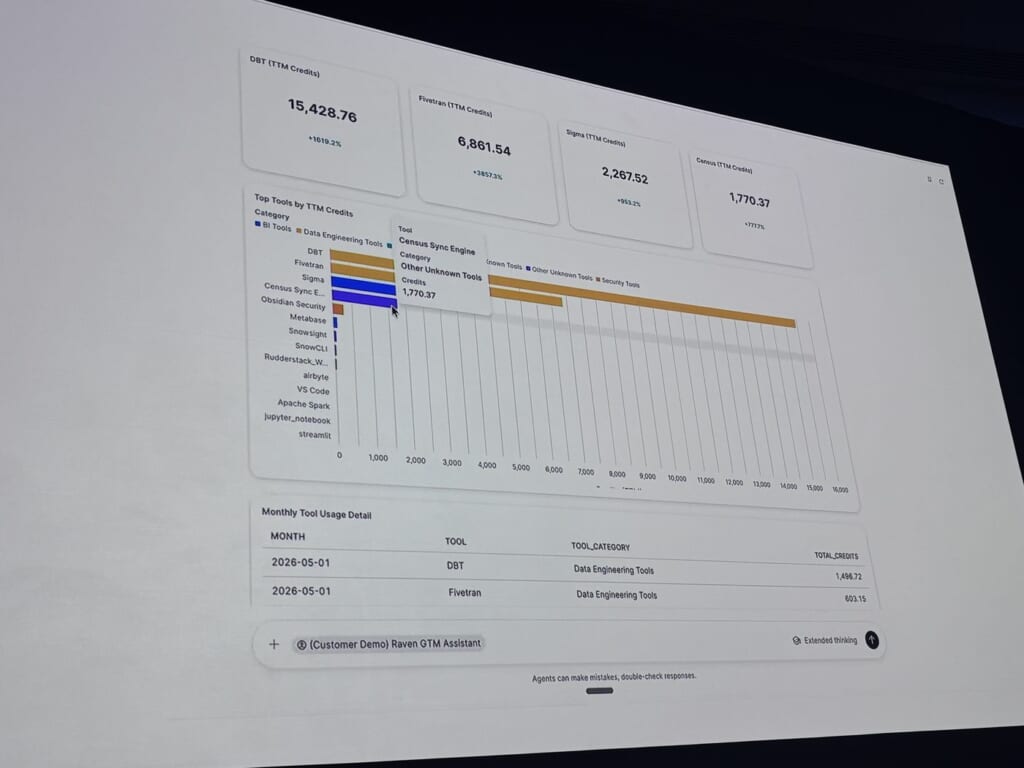
狙いは、「問題解決を助ける」段階から「問題を解決する」段階へ移ること。
鍵はMTTR(問題解決までの平均時間)の短縮だといいます。工場フロアでは3交代・8時間運用のシフト引き継ぎを自動化し、ツールのアラートやオペレーターのコメント、保全・安全イベント、過去の学びをAIがまとめて次シフトへ、優先アクションを渡します(人による検証あり)。
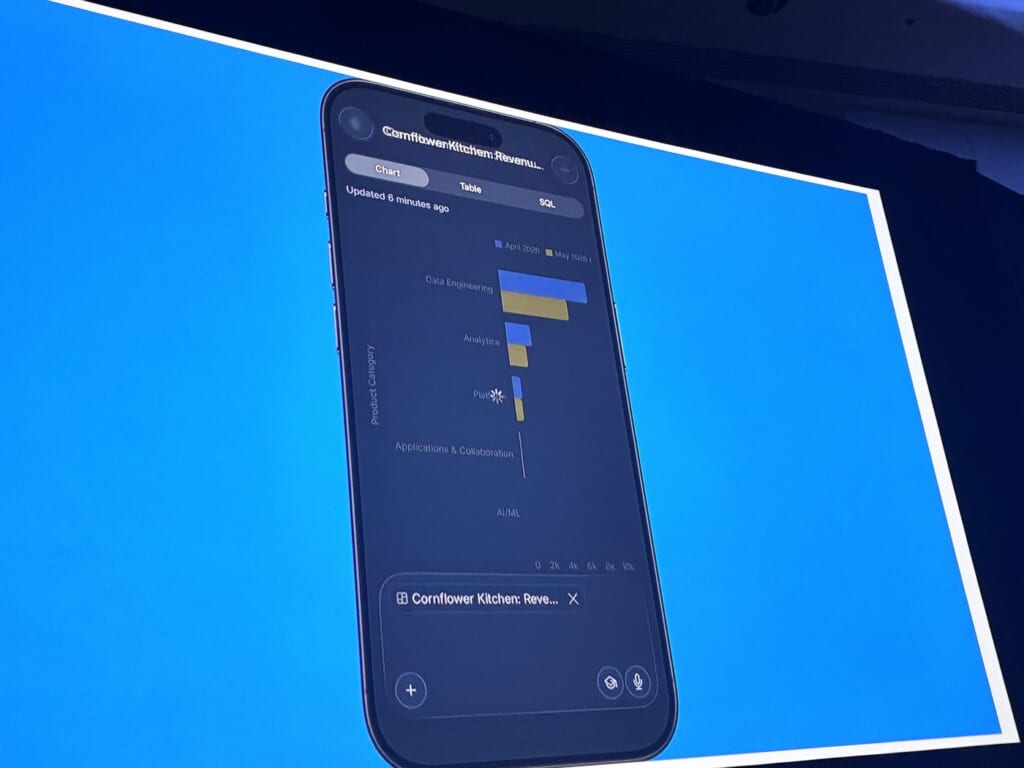
コーポレートでは、予算対比や粗利ドライバといった問いに対し、Snowflake Intelligenceをレポートツールからインサイトエンジンへ引き上げ、ERP・調達・経費などを横断して対話的に深掘りできるようにしたと紹介されました。

成功の土台として、Enterprise AI Knowledge Hub・Cortex Ready Data Products・ガバナンス保証・ROIフレームワーク・チェンジマネジメントを列挙。
ガバナンスの重要性は「ブレーキの効かないスポーツカーは運転しない。しかもブレーキが効くかまで確かめる」と表現されました。今後は、Cognitive System―DataからBusiness Context / Semantic Layer、Intelligence Layerを重ね、解決策が問題を待ち受ける構造―を展望し、Snowflake Intelligenceを「あらゆるインテリジェンスへの単一の窓」にすると述べられました。

まとめ
旧・Snowflake Intelligenceからの最大の変化は、”対話”から”実行”へ踏み込み、エージェントを「毎朝の起点」に据えようとしている点です。
ガバナンスと監査を最初から組み込み、複数の基盤モデルを選べる設計は、社内導入のハードルを下げる方向に働きそうで、今後はBIの置き換えというより「毎日の業務の入口」を狙う製品として広がっていくと見られます。
一方でWolfspeedの事例が示すとおり、効果を出せるかどうかはセマンティック層とビジネス文脈をどれだけきちんと整備できるか、そして現場の採用(チェンジマネジメント)に懸かっています。まずは1つの業務やロールを決め、試す→ 作る → 評価 → デプロイの小さなループから始めるのが現実的でしょう。まさに「shall we?」の時代ですね。
What’s New: Connectivity for AI-Ready Pipelines, with AI
続いて「What’s New: Connectivity for AI-Ready Pipelines, with AI(WN207B)」に参加しました。
Snowflakeへのデータ接続・取り込み(コネクティビティ)まわりのアップデートを、デモと顧客事例を交えて一気に紹介するセッションです。
登壇はSnowflakeのSaptarshi Mukherjee氏(Sr. Director of Product Management)とGilberto Hernandez氏(Lead Developer Advocate)、そしてゲストにヘッジファンドExodusPointのMichael Waller氏(Global Head of Data)です。

冒頭では、AIファースト時代に入り、接続性の前提が根本的に3つ変わった、と説明されていました。
1つ目は、エージェントが正しい判断をするには、コンテキストが「新鮮」である必要があること。
2つ目は、データそのものと同じくらい「ビジネス文脈(セマンティクス)」が重要であること。
3つ目は、AIが扱うデータ量が一気に増え、データをAからBへ動かす物理コストが無視できなくなったことです。
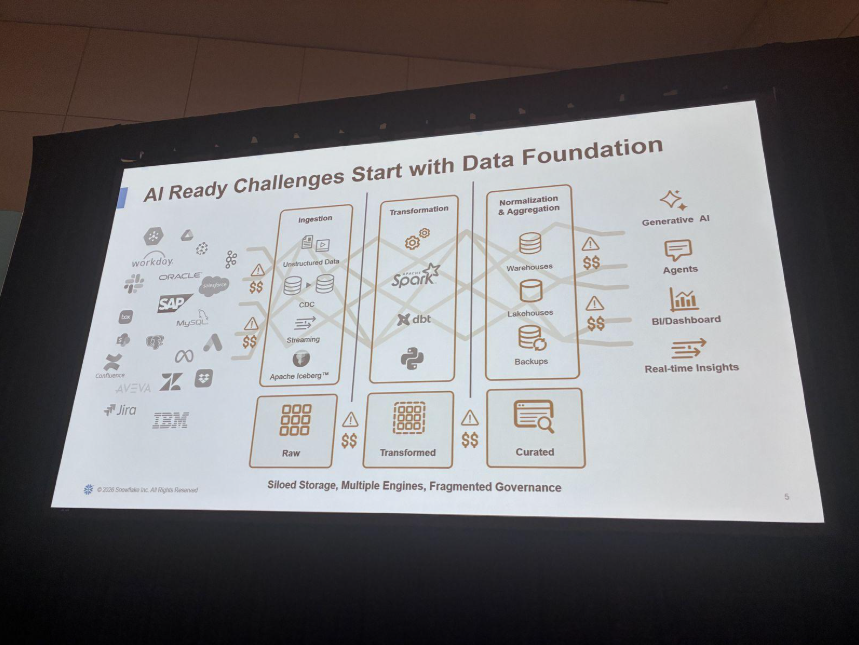
セッションでは、この課題に対する「4つの柱(リアルタイム/システム・オブ・レコード / データライフサイクル全体 / ファイル取り込み)」で構成され、いずれもCoCoから操作できるようにしていく、という流れでした。
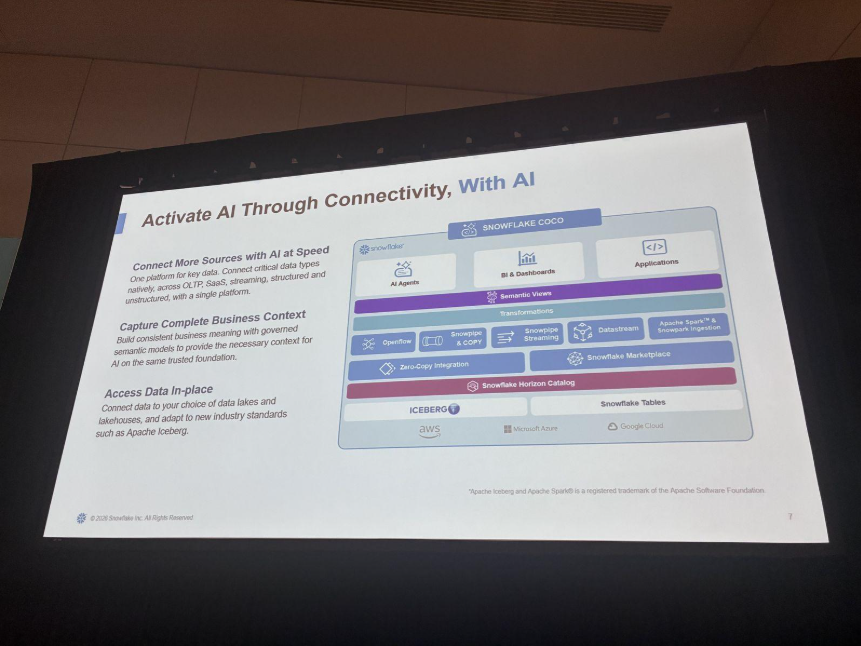
リアルタイムの瞬間をつなぐ「Snowflake Datastream」
最初の柱はリアルタイムです。KafkaはエンタープライズのストリーミングのデファクトだがAPIの認知負荷(パーティションオフセット、スキーマレジストリなど)が高く、インフラ問題になりがち、という前置きから、新サービス「Snowflake Datastream」が発表されました。
Kafka互換のプロデューサー / コンシューマーをフルサポートしつつ、Snowflakeが完全マネージドで水平スケールする、ファーストパーティのサービスです。
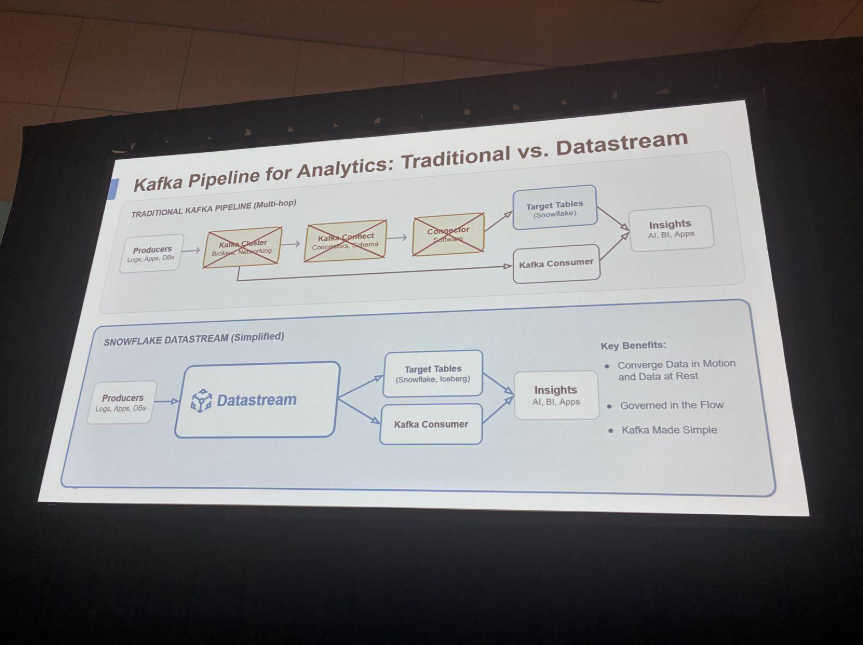
最大のポイントは、Datastreamにpublishされたトピックとテーブルが「二重性(duality)」を持つこと。コネクタを挟まず、pipeを指定するだけでトピックがSnowflakeのテーブルに自動マテリアライズされます。レイテンシはプロデューサーからDatastreamまでが500ミリ秒、IcebergやFDNテーブルへのマテリアライズが一桁ミリ秒台になる、と紹介されていました。

ここから、Gilbertoさんによるライブデモへ。製造現場のセンサー群(ステータス・温度・振動・圧力などをほぼ毎秒生成)のデータを、ストリーミング基盤を一から構築することなくSnowflakeへ流し込み、エージェントに分析させるまでを実演されていました。
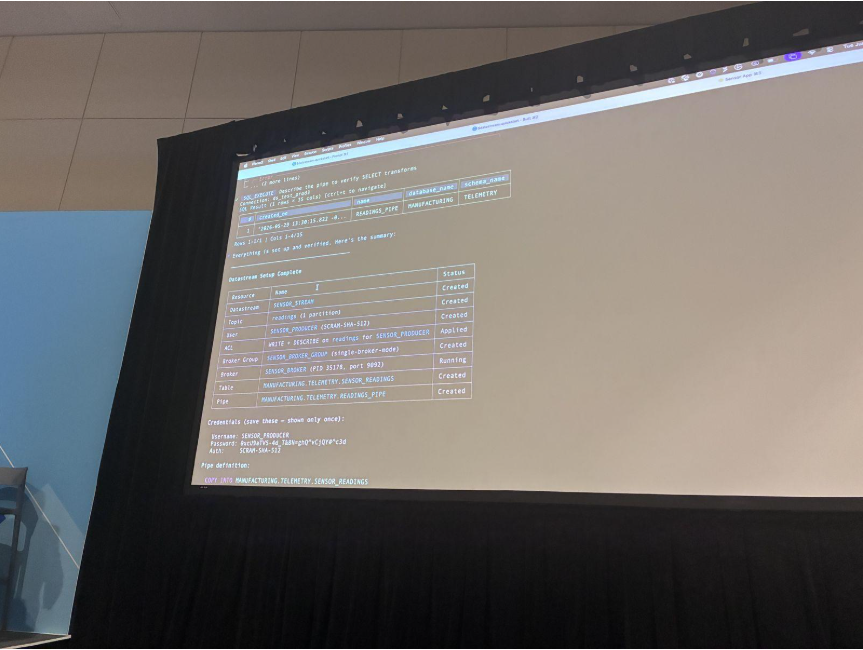
プロデューサー側は、他のセットアップと同じ標準のKafkaクライアントライブラリをそのまま利用。違いは、接続先がDatastreamになるだけで、追加インフラも別クラスタも不要です。
実際にテーブルへの行数がライブで増えていき、その上の動的テーブルが毎秒更新される様子も紹介されました。
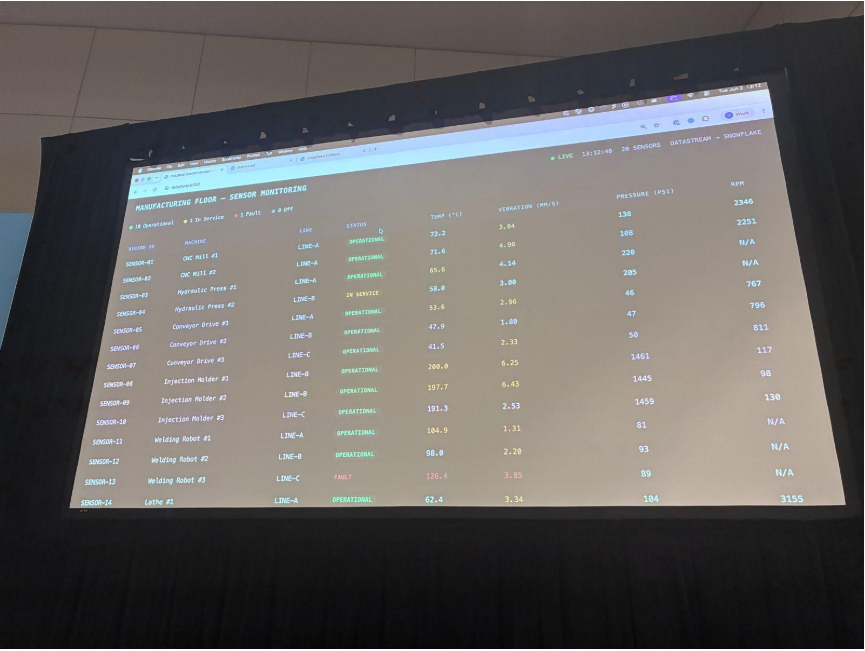
最後に、CoWork上のエージェントへセマンティックビュー経由で文脈を与え、「直近30秒で正常範囲外で動作しているセンサーは?どう対処すべき?」と質問します。
エージェントが過熱・過速・過遅のセンサーを特定し、技術者の派遣など故障前のアクションにつなげられるところまで実演されました。
Datastreamは6月末にプライベートプレビュー開始予定で、このセッションが初の公開デモとのこと。会場では、QRコードからデモ登録ができる案内もありました。
Snowpipe Streamingの進化とExodusPointの事例
Kafka APIを意識せず、とにかくイベントをSnowflakeへ流したい、というニーズに応えるのがSnowpipe Streamingです。
次世代アーキテクチャでGAとなり、テーブルあたり最大10GB/sのスループットに対応します。信頼性面ではError Tables(挿入できなかった行を確認可能)がGA、Kafka Connector 4.0もSnowpipe Streaming上でGAになりました。
さらに、次の新機能が2つ紹介されました。
1つは、Elastic Channelsです。プロデューサー側がSDKでチャネルを維持する必要がなくなり、IoTデバイスやセンサー、ルーターなどが生のペイロードのまま直接Snowflakeへストリームできるようになります。
もう1つは、Durable Acknowledgementsです。REST API経由でペイロードを送ると、250ミリ秒以内に「データは確実にSnowflakeに着地する」という耐久性のあるackが返るため、クライアント側でポーリングする必要がなくなります。
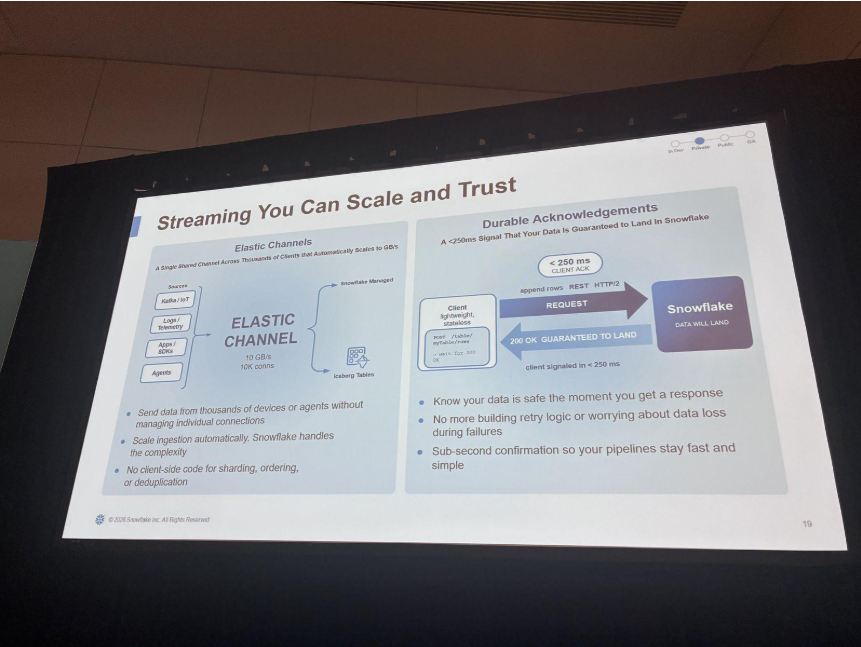
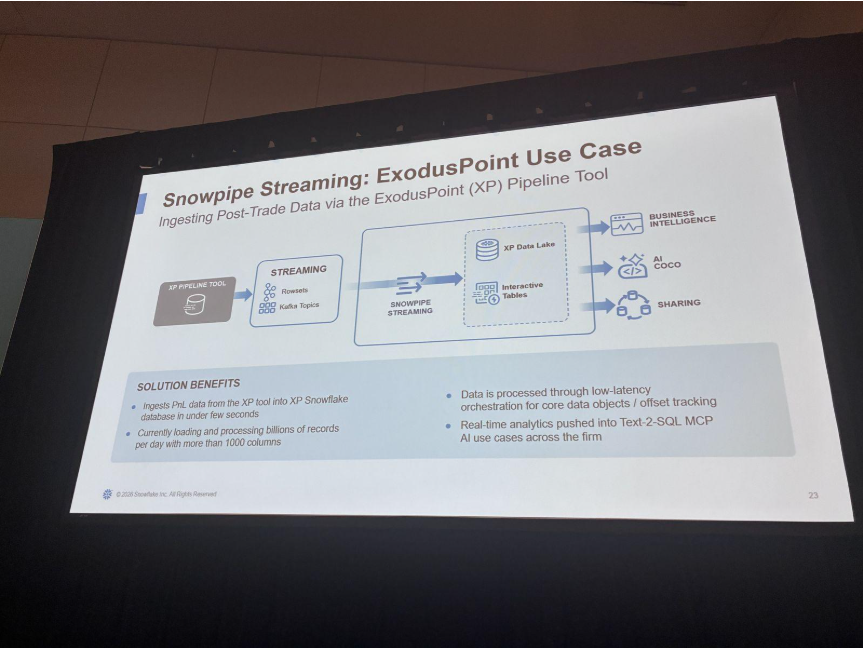
ここで、ExodusPointのMichael Waller氏が登壇されました。ヘッジファンドでは、トレードキャプチャやポートフォリオ管理、バック / ミドルオフィスの照合まで、Kafkaを中核のメッセージ基盤として使っているとのこと。P&LやリスクのデータをSnowpipe Streaming経由でSnowflakeへ取り込み、低遅延の分析をBIやAI、社内のデータ共有につなげていると紹介されました。

印象的だったのは、規模感とチャネル分散の工夫です。1日に数十億件・1000列超のポストトレードレコードを扱い、社内のパイプラインツールでKafkaとSnowpipe Streaming APIの間に入り、1つのトピックパーティションを100〜1,000チャネルへ分散できるとのこと。共通構成として「1,024チャネル」を使い、水平スケールさせていると紹介していました。
システム・オブ・レコードをAIエージェントへ「Zero-Copy Integration」
2つ目の柱は、イベントは出さないがアプリケーションに閉じ込められているデータ(ERPやCRMなど)です。
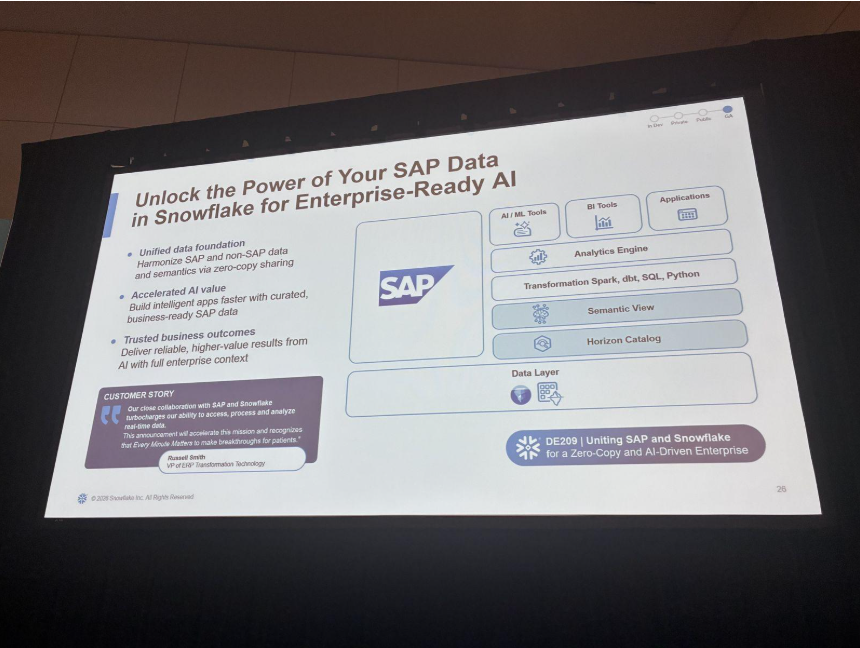
ここではIcebergを仲介役に、データをその場(in-place)で参照するZero-Copy Integrationへの投資が紹介されました。SAPはGA、IBM(メインフレーム連携)は新パートナーシップで、ゼロコピー統合が実現します。
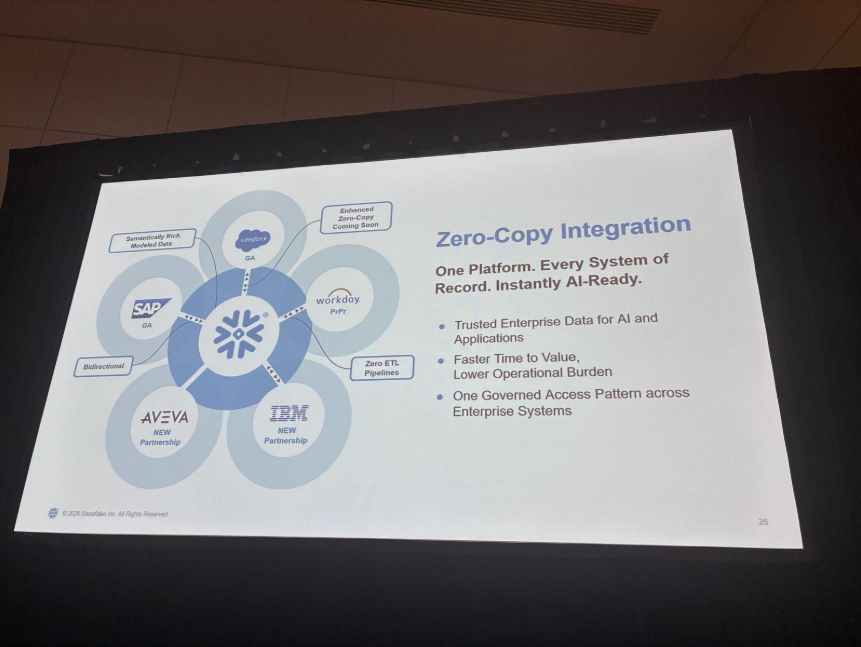
SAPについては、データ層をIcebergでゼロコピー参照しつつ、SAP固有のスキーマ注釈から「何がマテリアルか」「総勘定元帳とは」「サプライヤーとは」といったセマンティックビューをCoCoがその場で生成する、という点が強調されました。従来のETLを大量に書く必要がなく、POC中の顧客もその簡素さに驚かれているとのことです。
データライフサイクル全体をつなぐ「Openflow」
3つ目の柱は、OracleやMySQL、PostgreSQLなどのトランザクションDBを含むデータライフサイクル全体です。
Openflowは昨年AWS / Azureで提供開始されましたが、今年は Google Cloud も加わり、全ハイパースケーラー対応となりました。
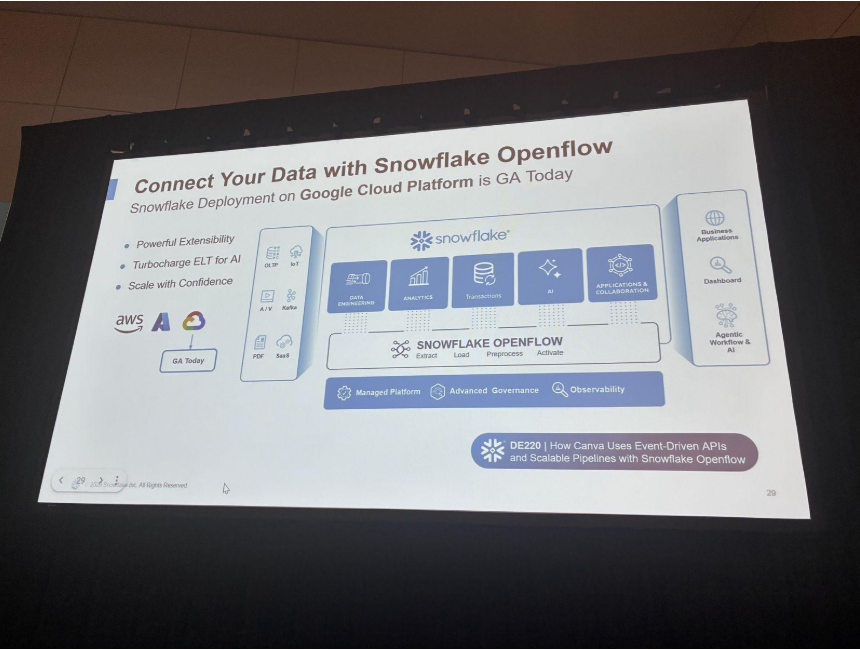
Openflow自体のアップデートも多数。Oracle CDCがGA、ウィザード形式のコネクタ設定(PrPr)、Observability Dashboard、CoCoによるセットアップ / デバッグ / 監視スキルなどが紹介され、新コネクタとしてSQL Server CT & CDC、Salesforce Bulk API、Veeva、MongoDB、Shopify、MariaDB、BigQuery、Jira V2、SharePoint V2が挙げられました。

Oracleについては昨年のSnowflakeとの提携を受け、Oracle Connector for OpenflowがGAに。CoCo+OpenflowでExadata OracleのCDCデータを直接Snowflakeへ取り込み、AIエージェントが扱えるようになります。クライアント側の問題までCoCoがトラブルシュートできる点も紹介されました。

ファイルをより安価に取り込む「Snowpipe」とHUMANの事例
4つ目の柱は、オブジェクトストアからの大規模ファイル取り込みをいかに安価に行うか、です。
昨年発表のper-GB価格モデルが全エディションでGAとなり、IcebergでもFDNテーブル形式でも、従来比50%超のコスト削減が実現しているとのことです。

顧客事例として紹介されたのがHUMAN(Sightline)。1日120万ファイル・150TB超のParquetを取り込むという規模で、Snowflakeの外でファイルを統合せずに済ませたいというニーズに対し、Snowpipeで旧モデル比75%超のコスト削減を達成したとのことです。

あわせて、取り込み時にデータをトークナイズする機能(KafkaやSnowpipeで生値を保存先テーブルに到達させない)や、CoCoにオブジェクトストレージのパスを伝えるだけでSQS通知やIAMロール設定を裏側で済ませ、Snowpipeのセットアップを「radically simple」にする取り組みも紹介されました。
CoCoはSnowflakeの文脈にチューニングされており、内部ベンチマークでは標準のクラウドコードやOpenAI Codexと比べてトークン利用効率が50%以上高い、という説明もありました。
まとめ
「どこにあるデータでも、AIの力を届けられるようにする」という方針のもと、リアルタイム(Datastream / Snowpipe Streaming)、システム・オブ・レコード(Zero-Copy)、ライフサイクル全体(Openflow)、ファイル取り込み(Snowpipe)という4つの柱が、いずれもCoCoから一貫して扱える形で整理されていました。
中でも、Datastreamは「Kafkaをインフラ問題からデータ問題へ」という発想が面白く、Kafka互換のまま追加インフラなしでテーブルに落ちてくる体験は、ストリーミングの構築・運用に悩んできたチームには効きそうです。プライベートプレビューは6月末予定とのことなので、Kafkaを使っている、もしくはこれから使う予定があるユーザーは、まず触ってみる価値がありそうだと感じました。Snowpipe側のコスト削減(50%超、HUMAN事例で75%超)も、AI前提で「全データを扱う」時代における、地味ではあるものの重要な後押しになりそうです。

夜は「JAPANレセプション」へ
一通りのセッションに参加したあとは、18時から開かれた「JAPANレセプション」へ。立食形式で、多くの方と交流しながら過ごすことができ、目の前に並ぶ料理についつい手が伸びて、今回もたくさん食べてしまいました。

なお、今年のレセプションは想像していなかった方との再会が多く、個人的にも記憶に残る年になりそうです。
このページをシェアする: