Snowflake Summit 2026 最速レポート 最終日
– Oracleリアルタイム連携&データ基盤移行編 –

目次
- 1 はじめに
- 2 DE301:Real-Time Openflow Oracle CDC for Enterprise with Yes Energy’s Story
- 3 おさらい:「Openflow」とOracleコネクタについて
- 4 DBA最大の不安「本番DBは大丈夫?」─ ベンチマーク
- 5 ユーザー実例:Yes Energyの「リアルタイム電力データ」基盤
- 6 「障害が起きたら?」─ 復旧の実際
- 7 まとめ
- 8 MI202:A Unified Data Foundation: iSpot’s Move from Redshift to Snowflake on AWS
- 9 なぜ、移行するのか ─「統合データ基盤」というゴール
- 10 「Massive Data Footprint」─ 移行前の規模
- 11 レガシーの複雑さと、移行で狙った効果
- 12 なぜ、Snowflakeだったのか
- 13 ビジネスを止めない移行アプローチ
- 14 デモ:「Snowflake AIM Migration Agent」
- 15 まとめ ─ 移行後の「End State」と、ビジネスインパクト
- 16 Summit総括 ─ 全日程を終えて
はじめに
こんにちは、ちゅらデータの菊地です。
本日もSnowflake Summit 2026の最速レポートをお届けします。
いよいよ最終日です。最後までしっかりセッションの内容をお届けしていきます。
DE301:Real-Time Openflow Oracle CDC for Enterprise with Yes Energy’s Story
本日最初のセッションは、こちら。
OracleのデータをリアルタイムでSnowflakeへ取り込むOpenflowのOracleコネクタについて、Snowflakeによるベンチマークと、実際に導入したYes Energyの運用・障害復旧のリアルな話が語られました。
登壇は、SnowflakeのJakub Puchalskiさんと、Yes EnergyのDan Goodmanさんのお二人です。
私自身、前職で6年ほどOracle Databaseのテクニカルサポートに従事していました。
だからこそ、「OracleのデータをリアルタイムでSnowflakeへ、しかも本番DBに負担をかけずに運ぶ」というテーマは、個人的にずっと気になっていたところです。
当時、毎日向き合っていた「Redoログ」や、「SCN」といったキーワードが次々に出てくるので、アーカイブフルなどの障害対応を思い出して、胃がキュッとなりました。
おさらい:「Openflow」とOracleコネクタについて
Openflowは、あらゆるソースからあらゆるデスティネーションへデータを動かせる、包括的なデータムーブメント基盤です。
ちょうど1年前のSnowflake Summit 2025で発表され、現在はGA(一般提供)になっています。
Snowflake専用ではなく、HTTPエンドポイントや他プラットフォーム、Icebergテーブルにも送れるのが特徴で、約500個のビルディングブロック(プロセッサ)を組み合わせて自由にデータフローを作れます。
そのうえで、用途ごとにテンプレート化された「コネクタ」も用意されており、その1つが今回のOracleコネクタです。

Oracleコネクタは、変更データキャプチャ(CDC)ベースで、増分をほぼリアルタイムに取り込みます。
内部ではOracle純正のXStream APIを活用しており、インフラを追加構築することなくDBへ直接アクセスし、SQLコマンドで設定できます。
XStreamで捉えた変更をSnowpipe StreamingでSnowflakeへ送り、数秒で「ジャーナルテーブル」(変更を一旦ためる中間テーブル)に着地、そのあとMERGE処理(デフォルト毎分、変更可)でターゲットテーブルへ反映する、という流れです。
Openflow自体は、Apache NiFiベースとのことでした。

DBA最大の不安「本番DBは大丈夫?」─ ベンチマーク
CDCの話になると、Oracle DBAから必ず出てくるのが「CDCを有効にすると本番DBの性能が落ちるのでは?最悪、クラッシュしないか?」という不安です。
セッションでは、この問いにデータで答える、という形でベンチマーク結果が紹介されました。

ベンチマーク環境は64 vCPU / 256GB RAMのAWS RDS Oracle 19cで、HammerDB TPC-Cを使って毎秒37,000トランザクション(37,000+ TPS)の負荷をかけ続けた状態での測定です。
結果は、次のとおり説明されました。
- ・CPUオーバーヘッドは合計で約3%。しかも、XStream Captureプロセス自体は約1%のみで、残りはサプリメンタル・ロギング(Supplemental Logging)由来。
- ・コミットレイテンシは2ms未満を維持。XStreamは非同期で、トランザクションパスには触れないため。
- ・Redoログの増加は1.5倍。よく恐れられる5〜10倍ではなく、線形で見積もり可能。
- ・TPSへの影響は、極端な高負荷下でも8〜9%。しかもこれは、I/O起因であってCPU起因ではなく、そもそも多くの本番システムは37K TPSには達しない、という補足あり。
なお、サプリメンタル・ロギングとは、CDC側が変更された行を正しく特定できるよう、Oracleが主キー列の値などの追加情報を通常よりも多く、Redoログへ書き出す設定のことです。
今回のオーバーヘッドの主因も、XStream本体ではなく、このログ書き込み(I/O)の側にありました。

「オーバーヘッドは、XStreamではなくサプリメンタル・ロギング由来であり、コストはI/Oであってメモリやその他ではない」というのが、登壇者の結論でした。
なお、このベンチマークはOracle側でも検証され、Medium記事として公開されているとのことです。
ユーザー実例:Yes Energyの「リアルタイム電力データ」基盤
セッションの後半は、Yes EnergyのDan Goodmanさんによる実例パートです。
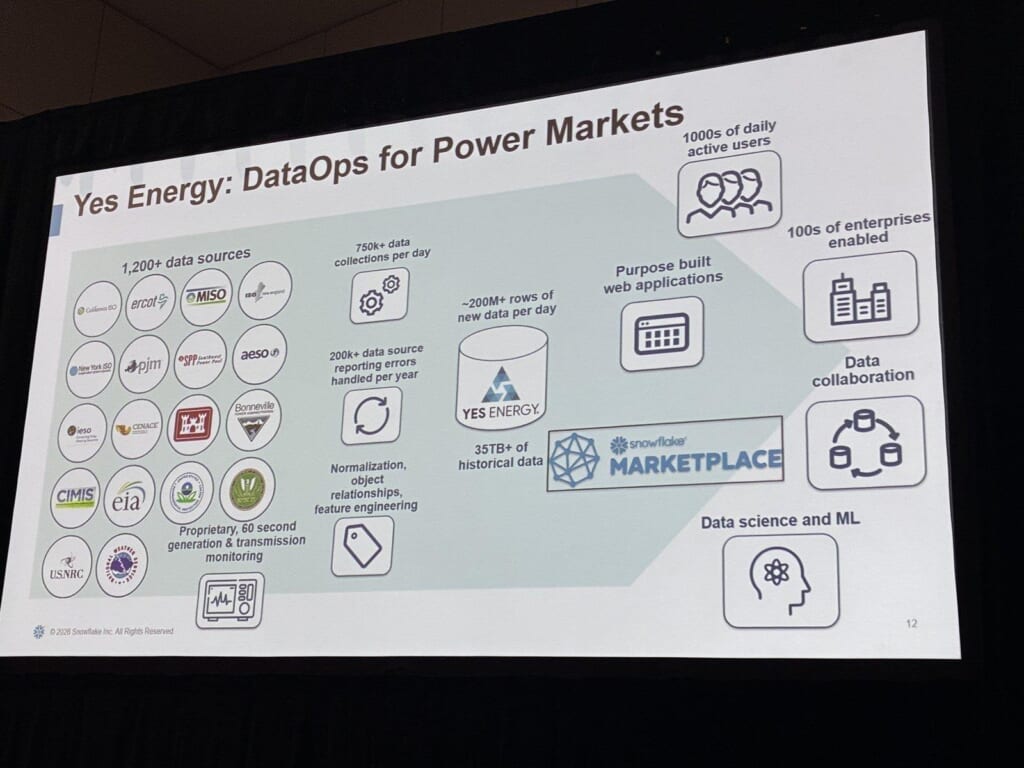
Yes Energyは北米の電力市場予測を手がける企業で、1,200以上のデータソースから、1日あたり750k件超のデータ収集・約2億行超の新規データを扱い、35TB超の履歴データを保有されており、これらをSnowflake Marketplaceで配信しているそうです。
Snowflakeの利用歴は、6年以上とのことでした。
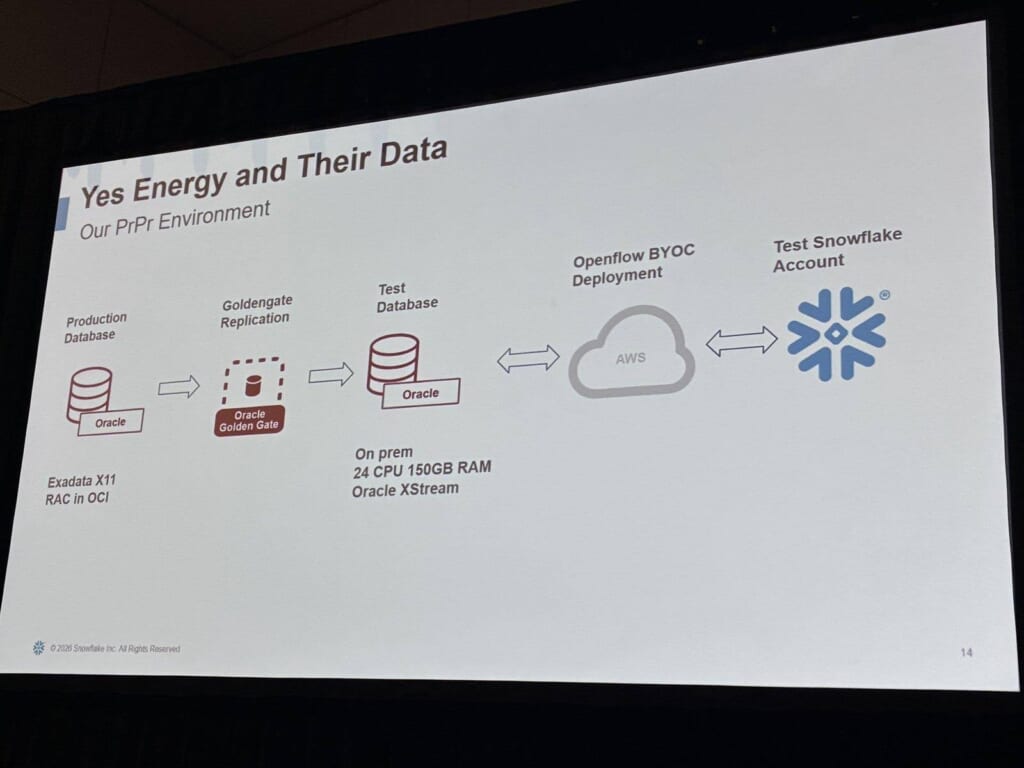
検証環境は、本番のOracle(OCI上のExadata X11 RAC)から、GoldenGateで約90%のデータをオンプレのテストDB(24 CPU/150GB RAM)へ複製し、そこからOpenflow(AWS上のBYOCデプロイ)を経て、テスト用Snowflakeアカウントへ流す、という構成です。
テスト環境は月1回、本番スナップショットからリフレッシュしているとのことでした。
プレビューでは、3つのテーブルを複製。
1つは、極小のテーブル、あとの2つが代表的なものでした。
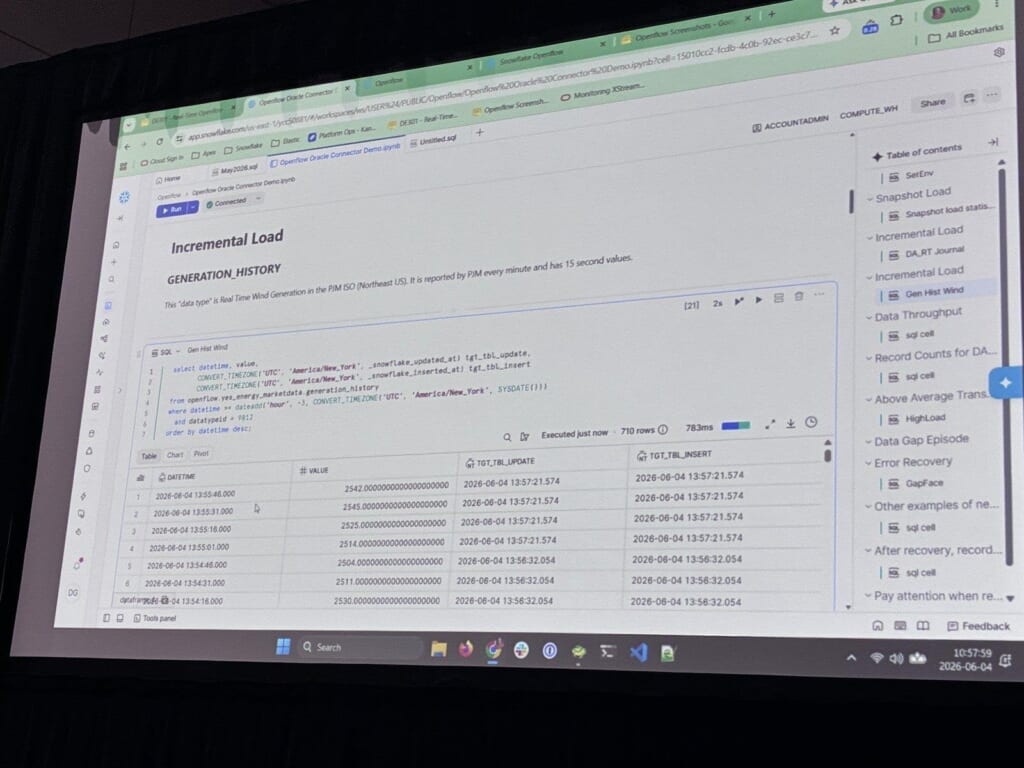
日中はほぼ更新が走る「DA_RT_SUMMARY」(約10億行、約100万更新/時、複合主キー、非パーティション)と、ほぼ挿入の「GENERATION_HISTORY」(約13億行、日次パーティション)です。
設定は、SnowflakeのAIアシスタント「CoCo」(Cortex Code CLI)のOpenflowスキルを使い、コネクタの構成からOracle側のXStream Server設定、デバッグまで対話で進められるデモも披露されました。

性能面で印象的だったのが、スナップショット(初回ロード)の改善です。
当初は、シングルスレッドで約2週間かかっていたものが、改善後は4.5時間で完了。
約13億行のGENERATION_HISTORYを一気に取り込める点が強調されていました。
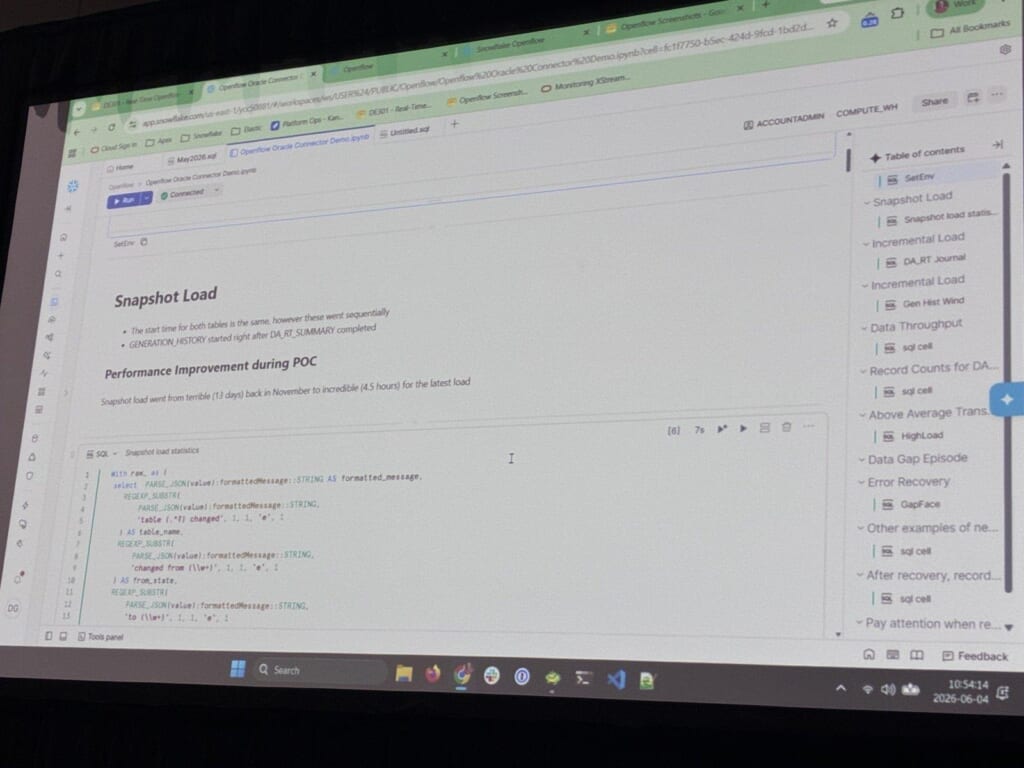
増分の反映も速く、本番DBからいくつもの中継(コピーや変換)を挟んだ構成でも、変更が約21秒でSnowflake側に現れるライブデモが示されました。
生成履歴データ(PJM ISO)は毎分公開・15秒値で、サマリーテーブルは約120万件/時を安定して処理。
日に一度の翌日市場データ(約70万行)の山や、ソースDBが本番のトランザクションレートを守るために自動でスロットリングし、その後回復する様子も実データで紹介されました。
「障害が起きたら?」─ 復旧の実際
個人的に一番ありがたかったのが、うまくいった話だけでなく、障害と復旧のリアルな話まで共有いただいた点です。
XStreamはOracleにビルトインされていて、常にトランザクション性能を優先する保護機構を持っており、外部向けのRedoログ解析を遅らせてでも本番を守る、という設計になっているそうです。
実際にYes Energyでは、月次リフレッシュ後にアーカイブログ格納先が逼迫し、さらにOpenflowが追いつく前にランタイムとコネクタをアップグレードしてしまった結果、ORA-21560が発生するインシデントがあったとのこと。
SCNを戻して復旧を試みる中で手順を一つ飛ばしてしまい、最終的に状態を強制クリアして復旧したものの、GENERATION_HISTORYで数日分・約20万行が欠損。
その後、Snowflakeのエンジニアリングと正しい手順を確認した、という生々しい振り返りでした。

復旧の基本的な手順として、コネクタを停止し、Oracle側でXStreamのSCNをリセット、Openflow側で「XStream開始位置 = Earliest」「reread tables = Any active」の2パラメータを変更して再起動、ギャップが埋まったらパラメータを元に戻す、という流れが示されました。
MERGE戦略のおかげで、時間を戻しすぎても重複が出ず整合性が保たれる点が、復旧の心理的ハードルを下げていて、実用上ありがたいと感じました。

まとめ
OpenflowのOracleコネクタは、「CDCは本番DBに優しくない」という長年の常識に、XStream+Snowpipe Streamingという組み合わせと具体的なベンチマークで正面から答えたセッションでした。
CPU約3%・コミット2ms未満・Redo1.5倍という数字は、DBAが導入を社内提案する際の強い材料になりそうです。
加えて、Yes Energyの実例で「障害は起きる。でも、明確な復旧パスがある」ところまで見せていただけたことが大きく、PoC段階での率直な学びまで共有された点に好感が持てました。
Oracleを基幹に据えつつデータ活用・AIへ踏み出したい組織にとって、有力な選択肢として今後広がっていきそうだと感じます。
設定や運用はCoCo(Cortex Code CLI)のOpenflowスキルでかなり省力化できるため、まずは小さく試してみる価値は十分にありそうです。
セッションの終盤では、コネクタの技術ドキュメントとベンチマーク記事へのQRコードも案内されていました。
気になる方は、ぜひどうぞ。
MI202:A Unified Data Foundation: iSpot’s Move from Redshift to Snowflake on AWS
続いてのセッションは、広告測定企業iSpotによる、Amazon RedshiftからSnowflake on AWS への移行の話です。
「スケールする統合データ基盤」をどう作ったか、そしてSnowflakeのAI移行エージェントのライブデモまで見られた、実践的な内容でした。
登壇は、iSpotのLucas Crowleyさんと、SnowflakeのFederico Zoufalyさんです。
なぜ、移行するのか ─「統合データ基盤」というゴール
移行は本来リスクの高い取り組みですが、それでも進めるのは、新しいプラットフォームを活かし、サイロを排除して、データエンジニアリングから分析・AI・アプリ/コラボレーションまでを一つの基盤に統合するためだと語られました。
iSpotのCEOの言葉を引用して「データ戦略なしにAI戦略は成り立たない。まず、全データを一つの統合基盤に集約して初めて、本当に活用できる」という考えが紹介されました。

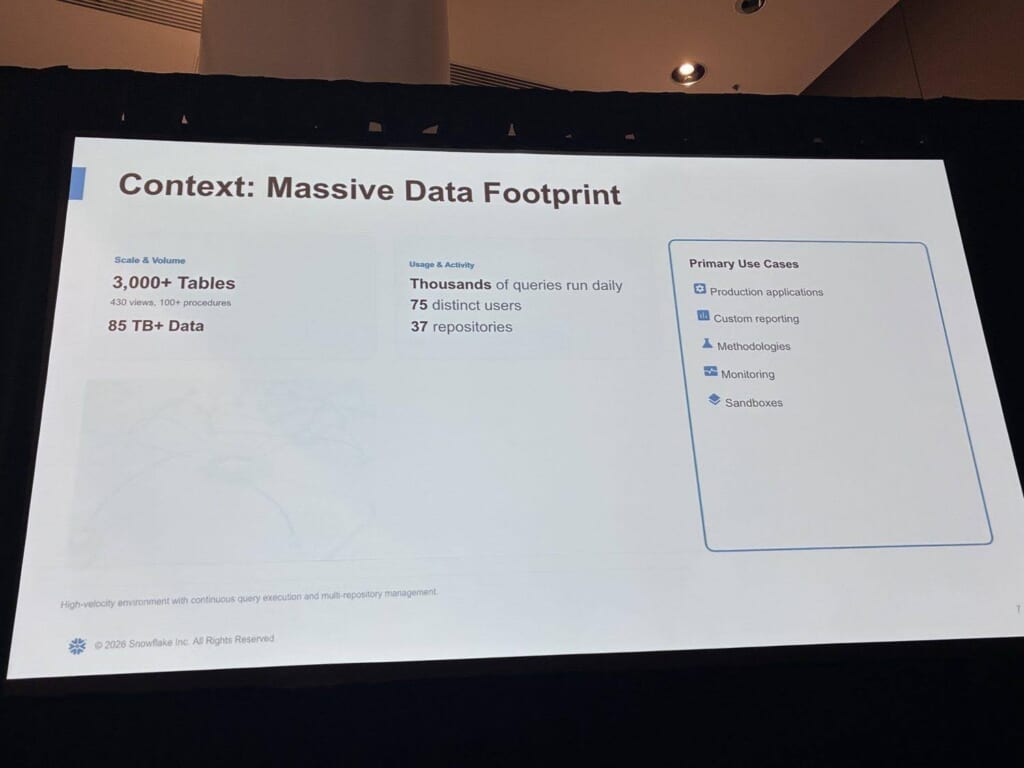
「Massive Data Footprint」─ 移行前の規模
移行前のiSpotのデータ規模が、具体的な数字で示されました。
テーブルは3,000以上(うちビュー430、プロシージャ1,001)、データ量は85TB超。
日々数千のクエリが走り、75ユーザー・37リポジトリが関わる、継続的なクエリ実行とマルチリポジトリ運用の高負荷環境でした。
レガシーの複雑さと、移行で狙った効果
移行前は、4つの異なる組織がそれぞれの使い方でデータを扱い、同じデータが重複して存在していたそうで、明確なオーナーのいない「データの墓場」や、並行運用による保守・コストの負担が課題でした。
ビジネス面で狙った効果として、サポート対応を減らしてロードマップに集中できること、不要なデータを落として「コンピュートコストを約30%削減」できること、そして本番データが既にSnowflakeにあることで開発もスムーズになること、が挙げられました。

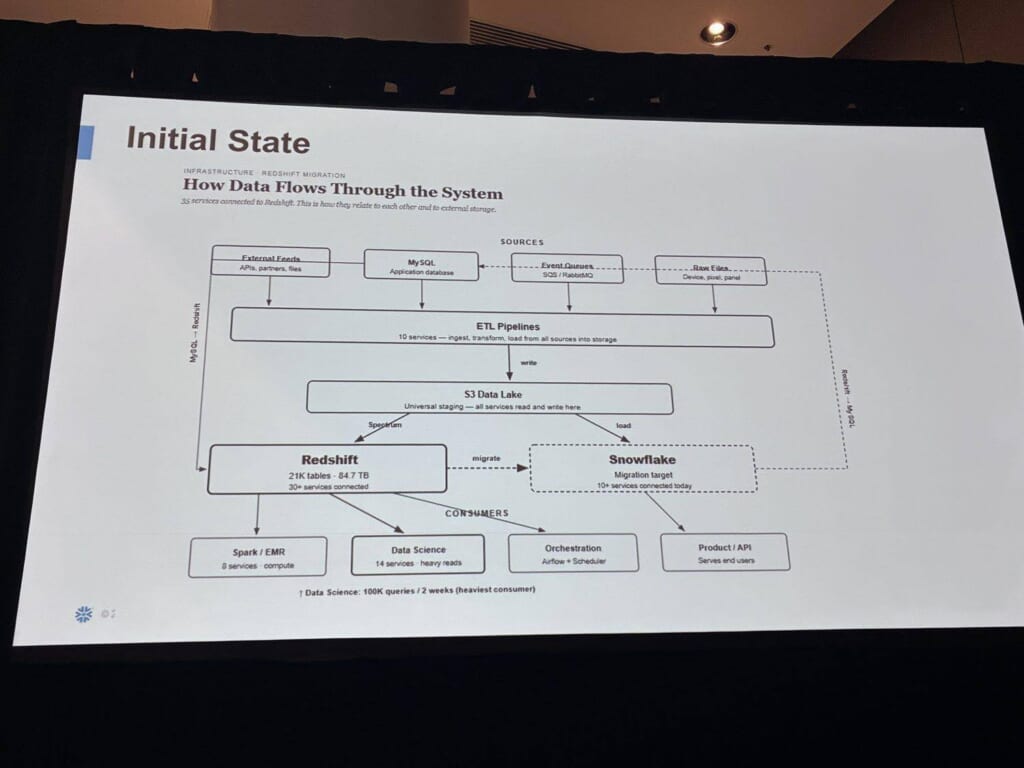
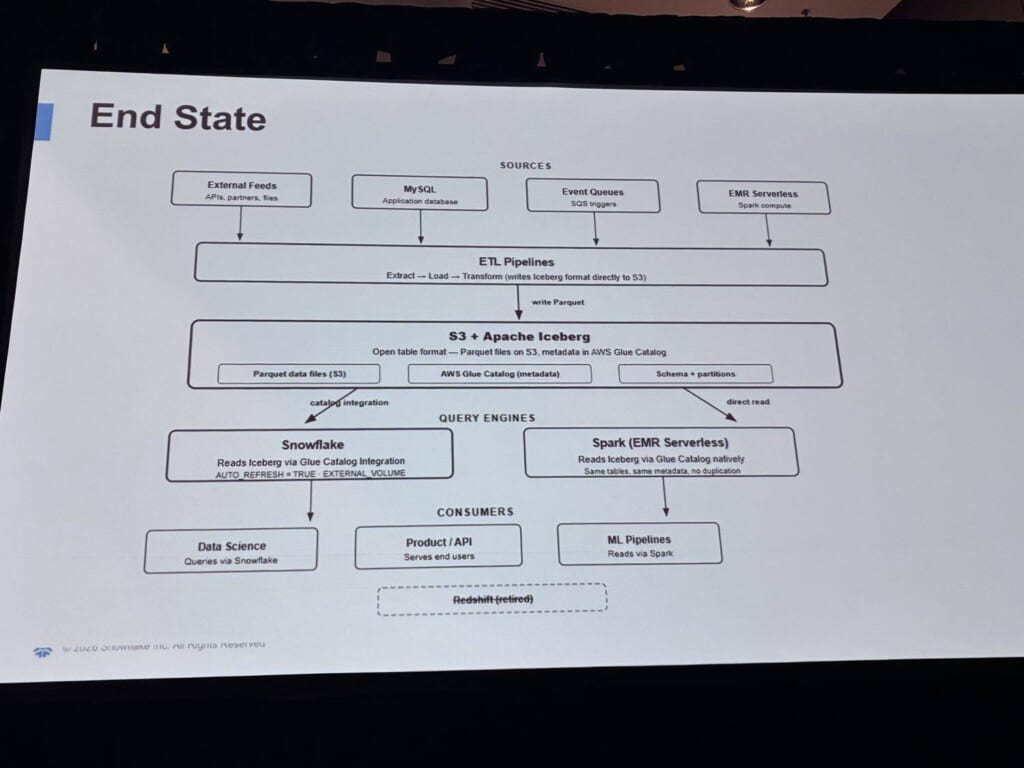
構成図も共有されました。
外部イベントやMySQLアプリDB、各種データファイルなどのソースからETLを経て、全サービスが読み書きする共通のS3データレイクへ。そこからRedshiftとSnowflakeへ流れる構成です。
Redshiftはテーブル2.5K・84.7TB・30以上のサービスが接続。同じデータがRedshiftとSnowflakeの間を何重にもコピーされ、10年以上積み上がった構成のなかで、単一の信頼できるデータ源(Single Source of Truth)が崩れていました。
なぜ、Snowflakeだったのか
選定理由として、技術的で辛抱強いサポート体制、モダンなワークフローへの移行を後押しするモダナイズ性、そして自社のユースケースに合わせてコードをスムーズに準備でき、巨大スコープも扱えるツールの3点が挙げられました。
すべてが一か所に集まることでデータ活用が進む点も大きく、Federicoさんのチームがプロジェクトを予算内に収まるよう分割し、選択肢を提示してくれたと振り返りました。
協力は双方向で、iSpot側からのフィードバックがツール改善にもつながったそうです。

ビジネスを止めない移行アプローチ
移行は「ビジネスを止めずにモダナイズする」ことを軸に進められました。
原則は、影響を最小化する/価値の高いワークロードを優先する/早期にガバナンスを確立する/長期スケールを見据えて設計する、の4点です。
実行面では、現行ワークロードの棚卸し → ターゲットアーキテクチャの定義 → 段階的な移行 → 結果の検証 → 冗長なシステムの廃止、という流れです。
教訓としては、組織のアラインメント、ビジネスとITの共同ガバナンス、部門横断のコラボレーション、そして簡素化への注力が挙げられました。
技術部門だけで移行せず、アナリストを含むビジネス側を最初の段階から巻き込むことの重要性を、繰り返し強調されていました。

デモ:「Snowflake AIM Migration Agent」
後半は、SnowflakeのAI移行エージェント「Snowflake AIM Migration Agent」のライブデモです。
現在は、CoCo CLIの中で利用できるとのことでした。
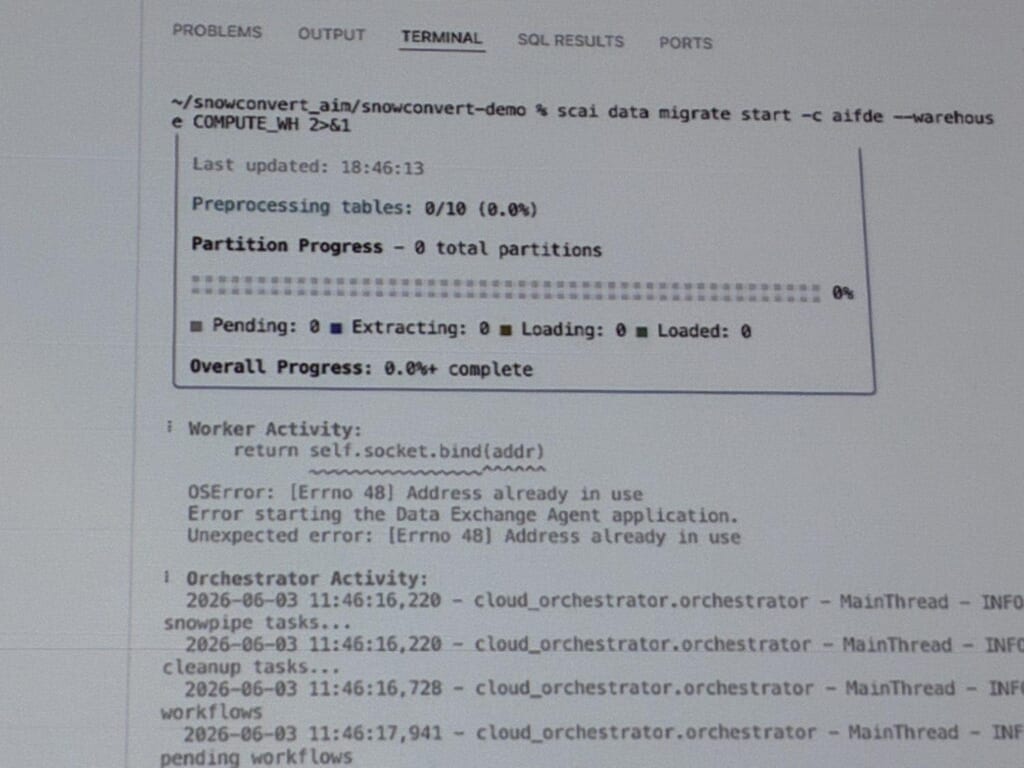
CoCo内のプロンプトから始めると、エージェントが自動でインストールされ、「データを移行したい」と伝えると接続先(今回はRedshift)の情報を聞かれ、移行プロジェクトを組み立ててくれます。
仕組みは、決定論的な移行エンジンとAIの組み合わせ。
プロジェクト初期化(各オブジェクトの状態を追跡)→ ソーススキーマからオブジェクト定義やDDLを抽出 → Snowflake SQLへ変換 → デプロイ、という流れを、AIが全体調整しながら進めます。
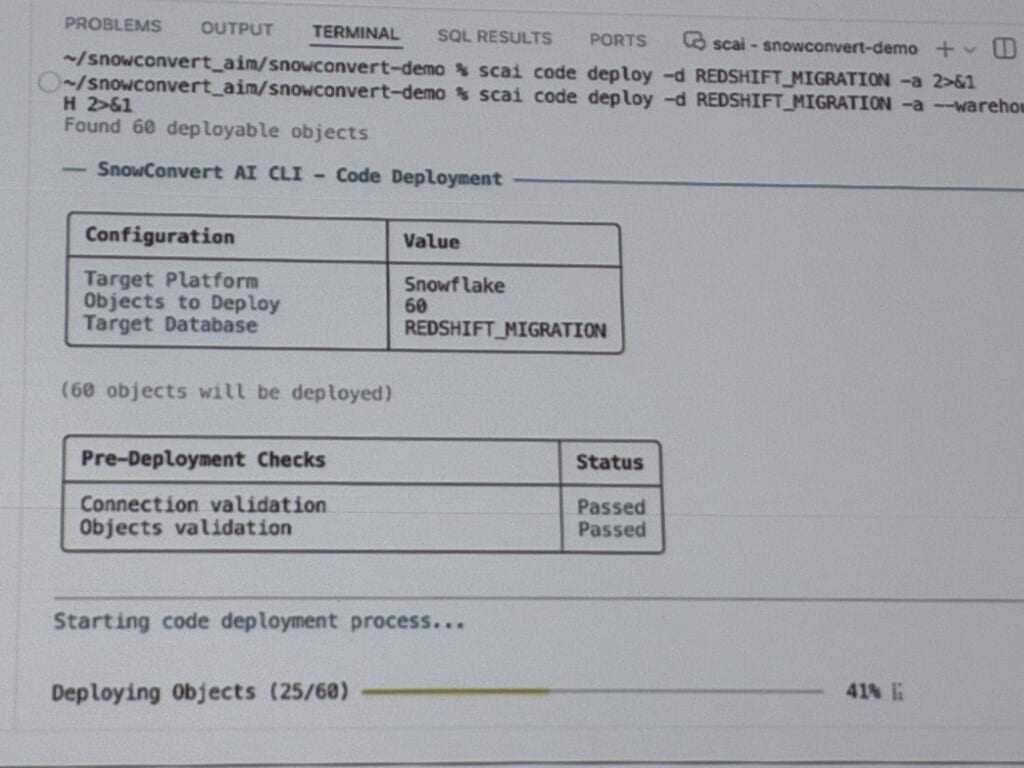
デモでは60オブジェクトをデプロイし、23件がエラーに。
そこをAIが調査して修正(例:マテリアライズドビューをDynamic Tableへ置き換え、未対応のUDFを変換)し、最終的に通していく様子まで、包み隠さず見せてくれました。
テストは、Snowflakeで実行するコードを生成する片側方式と、RedshiftとSnowflakeの双方で実行して結果を比較する両側方式の2通りです。
データにアクセスできなければ合成データを生成し、アクセスできれば実データで比較します。
データ移行と検証は統合され、AIがトリガーしつつ、並列ワーカーでスケール実行されていました。
まとめ ─ 移行後の「End State」と、ビジネスインパクト
移行後のEnd Stateは、S3上にApache Iceberg(オープンテーブル形式)を据え、SnowflakeとSpark(EMR Serverless)が同じデータをクエリエンジンとして共有し、Redshiftは役目を終えて廃止、という統合された姿でした。
ビジネスインパクトとしては、「コスト高で複雑・サイロ化・AIの遅れ」という以前の姿から、「簡単で効率的・統合された基盤・Time-to-Marketの加速」へ、という整理が示されました。
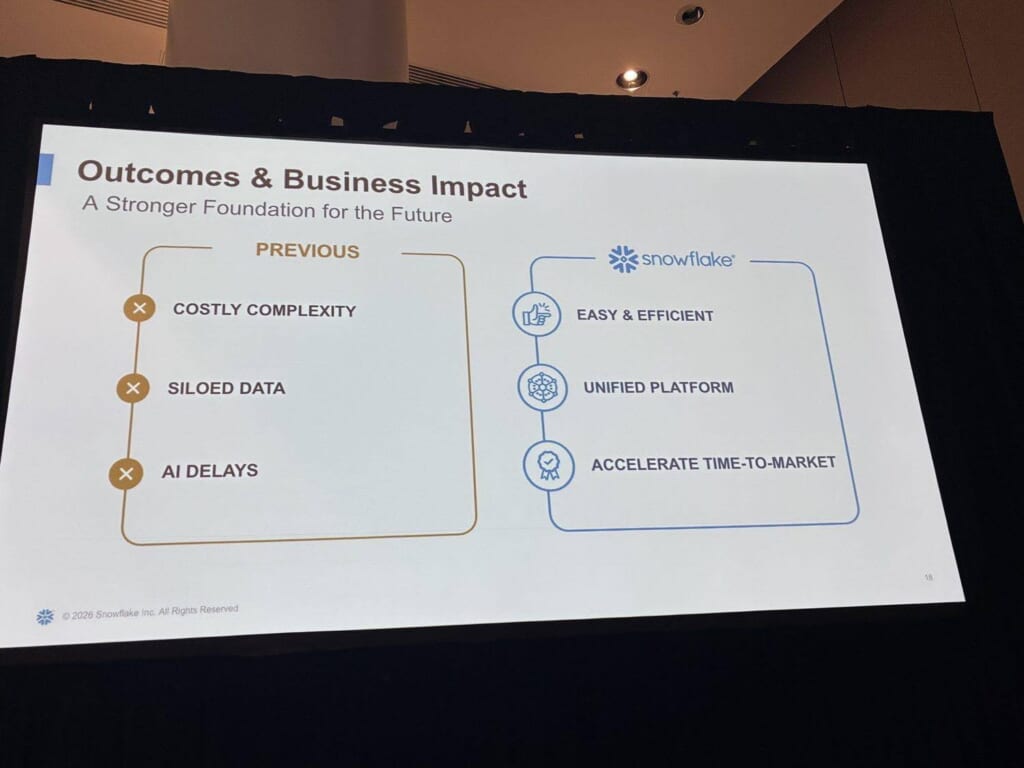
繰り返し語られたのが「データ戦略なしに、AI戦略なし」というメッセージです。
AI活用を見据える組織ほど、まずデータを1つの基盤に揃えることが出発点になる、と印象づけるセッションでした。
Summit総括 ─ 全日程を終えて
前日編から始まったSnowflake Summit 2026のレポートも、これで最終回です。
初日のキーノートからこの最終日まで、セッションの中で一貫して語られていたのは「データ戦略なしに、AI戦略なし」というメッセージでした。
昨年(2025)のSummitが「AIエージェントは魔法の杖ではない。まず、何から始めるか」という“これから”の空気感であったのに対し、今年はCoCoやCoWorkといったエージェントが当たり前に現場の作業へ入り込み、実装の段階へと進んでいました。
まずは企業の中にあるデータを1つの基盤に整え、その上でエージェントが働く—この1年の変化を肌で感じた数日間でした。
このページをシェアする: