Snowflake Summit 2026 最速レポートDay2
【セッション解説】-Fivetran × dbt Labs が描く「Open Data Infrastructure」とエージェント時代のデータ基盤-

目次
DATUM STUDIOの唐内です。
現在サンフランシスコで開催中の「Snowflake Summit 2026」より、業界の注目を集めたDay2のセッションをご紹介します。
登壇は、前日(2026年6月1日)に経営統合(合併)を発表したばかりのFivetranのCEOであるジョージ・フレイザー氏と、dbt Labsの創業者(統合会社 社長)であるトリスタン・ハンディ氏のお二人です。テーマは、合併の中核コンセプトである「Open Data Infrastructure(オープン・データ・インフラストラクチャ / ODI)」です。
「AIエージェントが主要となるデータ消費者の時代に、いまのデータ基盤は耐えられるのか?」という問いを軸に、新発表のプロダクトと、実際にエージェントで社内データを分析するライブデモまで盛り込まれた、密度の高い内容でした。
はじめに:なぜいま「Open Data Infrastructure」なのか?
この10年で普及した「モダンデータスタック(MDS)」は、人間がBIツール越しにデータを見ることを前提に設計されてきました。しかし2026年現在、データを読みに来る主役は人間からAIエージェントへと移りつつあります。
エージェントはマシン速度で動き、無限に並列化でき、24時間止まりません。つまり桁違いの量のクエリをデータ基盤に投げてきます。これがコスト・ガバナンス・オブザーバビリティのすべてに新たな負荷をかけます。両社が掲げるODIは、この変化に「オープンスタンダードとポータビリティ」で備えよう、という提案です。
AIがゲームを変える:エージェントは「新しい主要データ消費者」

冒頭、両氏は同業者アンケートの数字(AIを生産性向上に重視=77% / ハルシネーション懸念=71% / ウェアハウス・コンピュート支出増=57%)を引きつつ、「自分の前提に柔軟であれ」と強調しました。変化が速すぎて「毎年、仕事の50〜100%を学び直す」感覚だとおっしゃており、思わず何度もうなずいてしまいました。
そのうえで提示されたのが「いまのデータ基盤を信頼してエージェントを動かせるか?」という、3つの問いです。
- 1.規模に応じてエージェントのコストを捌けるか
- 2.データはガバナンスされ、正確で、追跡可能か
- 3.ポータブルで、オープンスタンダードの上に作られているか
Fivetran社内では、エージェントの活用によりクエリ量が月10%(=年3倍)で増加しているとのこと。量の急増にどう備えるかが、まさに今回のテーマです。
MDS から ODI へ:何が変わるのか
両氏によれば、ODIはMDSの単なる言い換えではなく、業界が経ている進化に名前を与えたものです。主な変化点は次の2つです。
- 1.セマンティックモデルのマルチコンシューマ化:以前は単一のBIツールに全振りできたが、今はAIエージェントも消費できる必要がある
- 2.データレイク(オープンテーブルフォーマット)の重要性:コスト抑制と、将来対応の鍵。2年前のIcebergを巡る動きが転換点だった
そして「エージェントに必要なインフラ」を次の3本柱で整理しています。
- 1.信頼でき、ガバナンスされた、エージェント向けデータ
- 2.柔軟でポータブルなデータ(定義・リネージ・ロジックがクラウド / ツールをまたいで持ち運べる)
- 3.スケーラブルで最適化されたインフラ(暴走するコンピュート / トークンコストを抑える)
ODIは「12種類のツールの寄せ集め」ではなく、オープンスタンダードに基づくリファレンス実装であり、好きな部品を抜き差しできる点がポイントだと説明されました。
Fivetran + dbt Labs:信頼できるインフラ
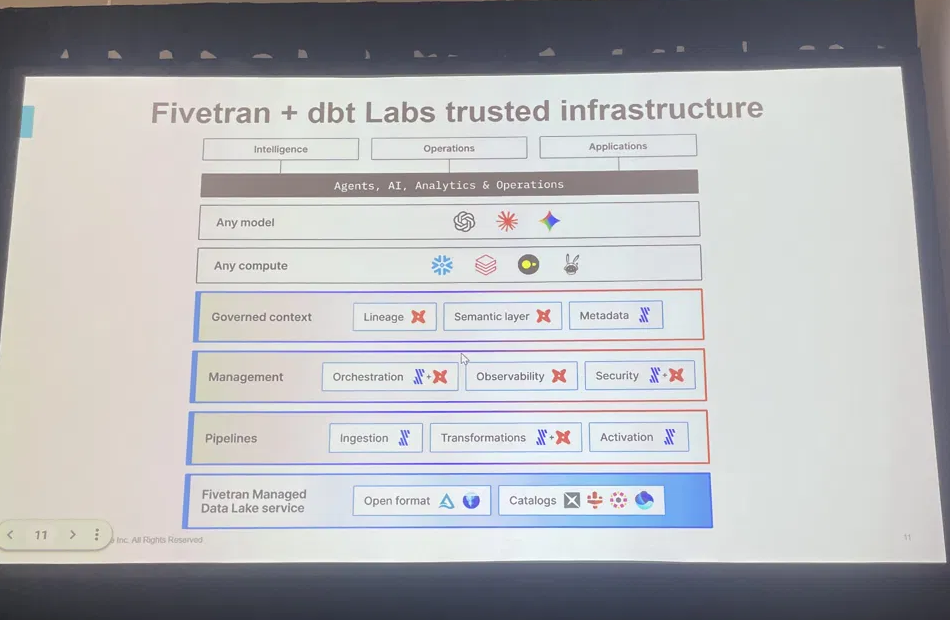
具体的なレイヤー構成は、以下のとおりです(下から上へ)。
- ・Fivetran Managed Data Lake service:Open format(Iceberg等) / Catalogs。デスティネーション設定だけでソースのミラーをIcebergで取得でき、更新・削除も自動
- ・Pipelines:Ingestion / Transformations / Activation
- ・Management:Orchestration / Observability / Security
- ・Governed context:Lineage / Semantic layer / Metadata
- ・Any compute:Snowflake、Databricksほか任意のコンピュート
- ・Any model:OpenAI、Anthropic、Gemini ほか任意のモデル
- ・最上段:Intelligence / Operations / Applications(Agents, AI, Analytics & Operations)
取り込みはFivetran、変換管理はdbt、リネージ・セマンティックの標準もdbtが担う、という役割分担です。
新発表(1):dbt Core v2.0

dbt史上、メジャーバージョンが上がるのは1.0以来2回目です。dbt Fusionエンジンの成果を、信頼されたOSS標準(Apache 2.0ライセンス)に取り込んだのが本リリースです。
- ・オープンソースランタイム:dbtプラットフォームの裏側と同じエンジンを、自由に使い拡張できる
- ・完全なローカル配布:コア言語・ウェアハウスアダプタ・SQL解析が機能制限なしでローカル利用可能
- ・シームレスなプラットフォームアクセス:ターミナルからログインすれば、既存ワークフローを変えずに追加機能を解放
速度面では、プロジェクトと測り方によりますが、dbt buildが10〜30倍高速化。Pythonランタイムとの二重保守をやめ、エンジンを一本化した点も大きな意味を持ちます。
「合併後にdbtが、オープン性から離れるのでは」という懸念に対する、明確な回答と言えそうです。
新発表(2):dbt State / dbt Wizard / Agents Schema

今週発表された新機能は、次の3つです。
- 1.dbt State:
データ・コードの変更を検出し、ビルドが必要なモデルだけを再構築。CloudとCoreをまたいで結果を再利用・クローンできる。dbt Core 1.7+ / Fusion / dbt Platformで利用可
- 2.dbt Wizard:
dbtに特化したエージェント型コーディングハーネス。リネージ・テスト・コントラクト・メトリック定義の豊富なコンテキストを持つ。Codexベースで、無料・BYOK(自分のAPIキーを持ち込む)方式。Claude CodeなどからもSkills / MCP / API経由で利用可
- 3.Agents Schema(オープンソース):
DWH / データレイク内の1スキーマを、エージェント向け共有コンテキスト層に指定する仕組み。ファイルシステムのAGENTS.mdのDWH版。agentsスキーマのrootテーブルにMarkdownでマップを書き、各プロバイダが行を寄稿する
dbt Stateは特に効果が大きく、後述のとおり社内で64%のコンピュート削減を実現したとのことです。
コンテキストはどこに置くべきか:共有 vs 個人
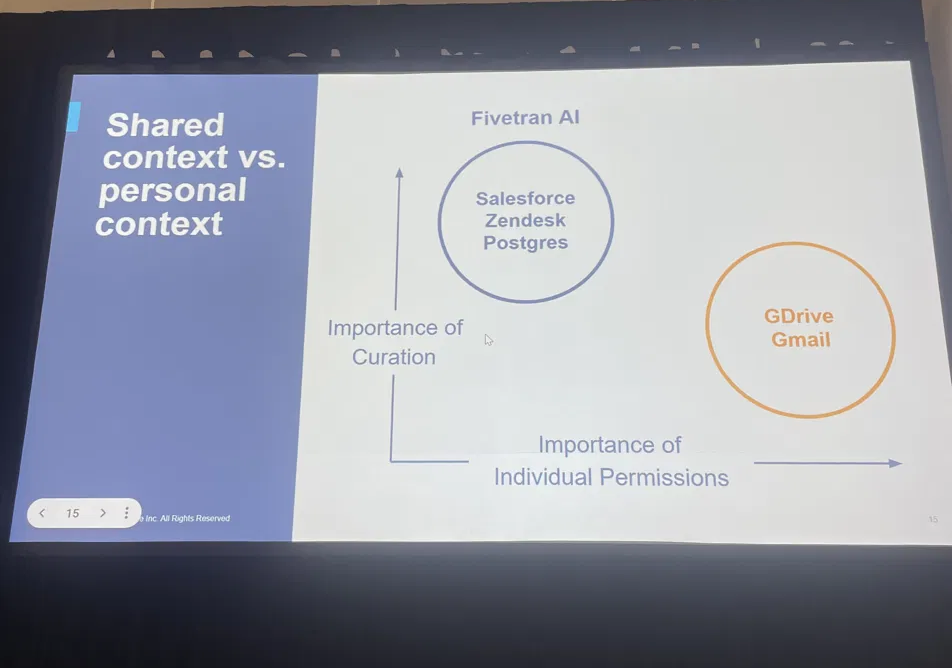
「コンテキストをDWHに置くべき」とはいえ、すべてが対象ではありません。両氏は2つの軸(キュレーションの重要度 / 個別権限の重要度)で整理しました。
- ・個人コンテキスト(GDrive、Gmail など):
私的で、キュレーションをあまり要さない。MCPやAPI直接呼び出しが有効。ClaudeやChatGPTの組み込みコネクタが適する
- ・共有コンテキスト(Salesforce、Zendesk、Postgres など):
BIと同様にキュレーションが必須。一方で個別権限は通常は不要。自前のデータ基盤に集約し、AIをその上に乗せるべき(APIを直接叩く別経路を作らない)
「AIにコンテキストを提供することを、今後のデータチームの役割の一部とみなす」というメッセージが、印象的でした。
ライブデモ:「Fivetran Chat」

本セッションのハイライトが、ジョージ氏が実際に使ったという対話型分析エージェント「Fivetran Chat」のデモです。
ノートPC上のエージェントがDWHに接続し、Agents Schemaを頼りに分析します。経営会議中の素朴な問いから、その場で以下の内容が返ってきたといいます。
- ・データレイク採用顧客の内訳:
コマーシャル389社 / エンタープライズ104社。コマーシャルの社数が大半だが、売上加重ではエンタープライズの浸透も近い
- ・上位20社と累積シェア:
上位20社でData Lake売上の35.00%、最大の単一アカウントでも3.89%と、集中は緩やか
- ・Gong通話記録の横断分析:
上位各社の通話記録を読み、「なぜデータレイクを採用したか」を再構築。動機はウェアハウスコスト、マルチエンジンの柔軟性、CDCの鮮度 / 正確性、脆いコネクタ / API保守の置き換えに集約された
使った部品は、Fivetranコネクタ+10年使ってきたdbtモデル+agentsスキーマのMarkdown+短いCodex Skill(Skill Creatorで約3分)のみ。新しいものをほとんど導入せず、この体験を作れる、という点が要諦でした。
まとめ:信頼できるのは「すでに持っているデータ基盤」

dbt Stateによる差分ビルドは、設計パートナー実績で平均30%、Fivetran社内では変換コンピュートの64%という大幅なコスト削減につながったと紹介されました。
Ramp(コンテキスト豊富なコーディングエージェントがマージPRの50%超を駆動)、OpenAI(高インパクトな分析を”日単位でなく分単位”で)、Infinite Lambda(18か月分を数週間に圧縮)など、実適用事例も示されました。
セッションの結論はシンプルで、AIエージェントを動かす最良のデータ基盤は、多くの場合「あなたがすでに持っているデータ基盤」である——少しの拡張(ドメイン追加、データのマップ作成)を施し、オープンスタンダードの上に組むことで、特定ベンダーに縛られずエージェント時代に備えられる、というメッセージでした。
DATUM STUDIOでも、Snowflakeを中心としたELTパイプライン設計やCI / CD、データ基盤のガバナンス設計を数多く手がけています。
今回のODIの考え方は、これからエージェント活用を見据えてデータ基盤を整える企業にとって、実践的な指針になりそうです。
このページをシェアする: