Snowflake Summit 2022 現地レポート

こんにちは、DATUM STUDIOの梶谷です。
Snowflakeユーザーの皆さま、Snowflake Summit 2022は怒涛の新機能ラッシュでしたね!すでに録画配信をチェックされている方もいらっしゃるでしょうか?
DATUM STUDIOとちゅらデータでは、4人のメンバーでSnowflake Summit 2022に参加してきました。今回のブログではこのイベントについてレポートします。
最高に楽しくエキサイティングな体験ができましたので、少しでもその雰囲気をお伝えできればと思います!

画像はSnowflake Summit 2022トップページより。現在(2022/7/25)は次回版に切り替えられています。
Snowflake Summitとは?
年に一度開催されるSnowflake最大のイベントです。今回のSummitは6/13から6/16までの4日間にわたってラスベガスで開催されました。
今回は2019年以来となるオフライン開催でした。それゆえにか、前回以上に数多くの革新的な新機能が発表され、3年分の思いが込められているように感じられました。
Snowflake Summitの会場
ラスベガスにある Caesars forum がメイン会場でした。全体図はこちら。
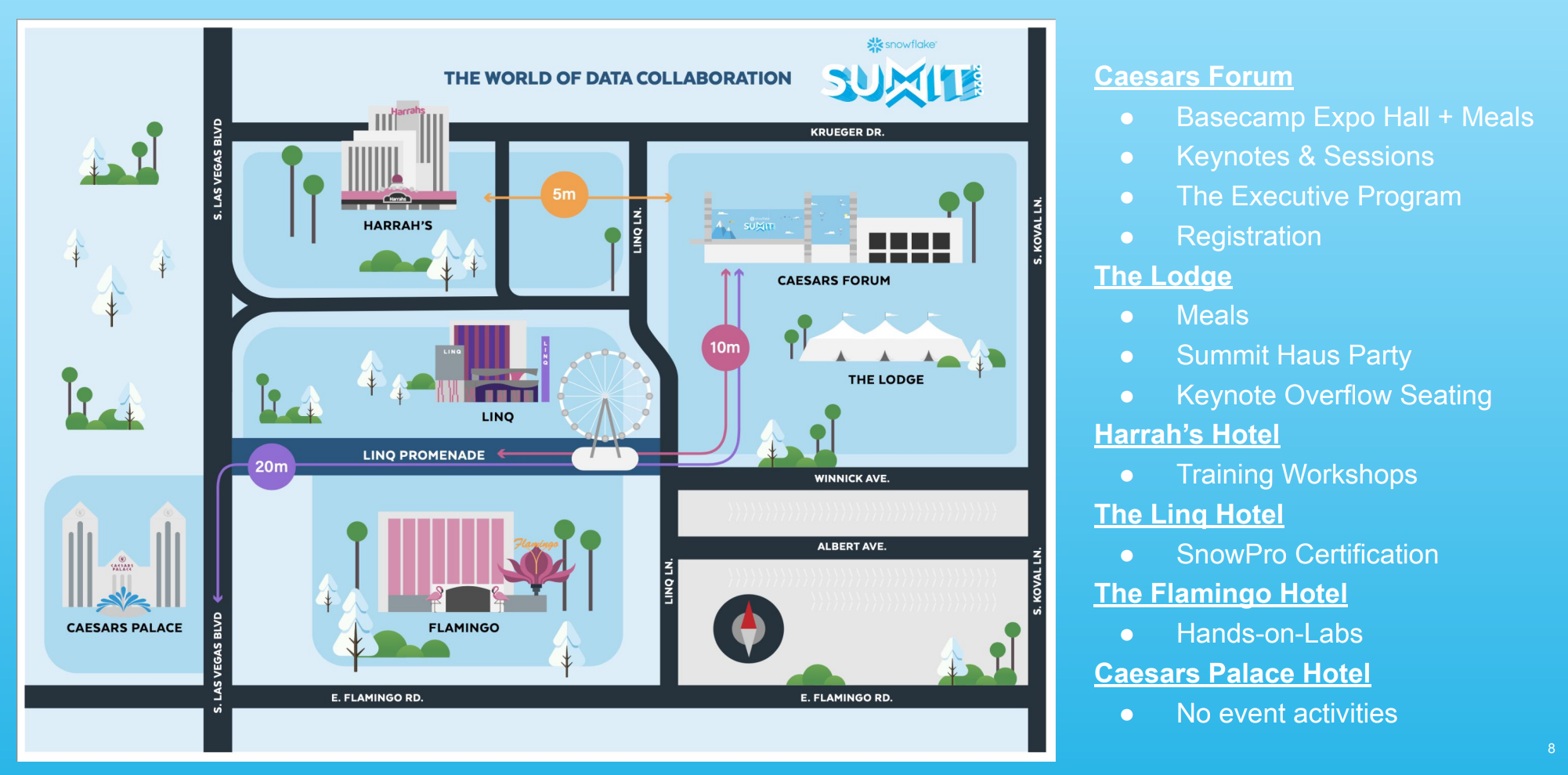
Caesars forumの外にロッジ(大きなテント)があり、食事をとったりKeynoteのライブ中継を見られるようになっていました。周辺のホテルは、認定試験やトレーニングの会場になっていたようです。
メイン会場の中はこんな感じでした。下の会場マップで、★の位置から☆の位置までを歩いたものです。
会場の様子はこちら
【https://youtu.be/dWVCPiZ0kzI】
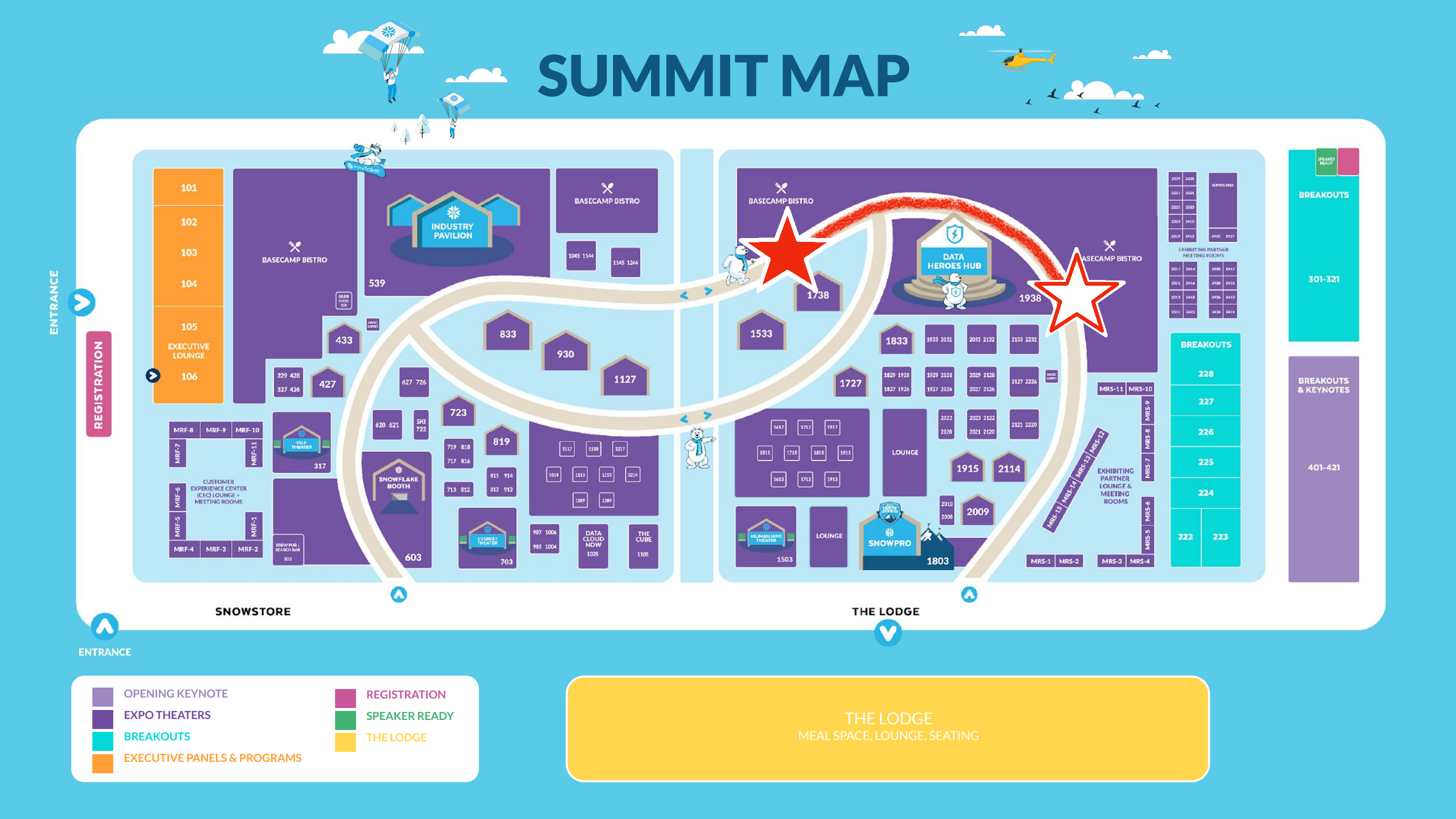
事前にマップを見て、そんなに広くないのかな?というイメージを持っていたのですが、実際の会場は広くて、どこを見ても賑やかでした。
Keynote会場となるホールです。盛り上がりの様子はKeynoteにて。

こちらはパートナーブース。みんな大好きdbtのブースは、いつ見ても人だかりができていました。詳しくはパートナーブースにて。

Snowflakeグッズショップもありました。個人的に一番かわいいと思ったのは右のスキーウェアです。店頭では発見できなかったのですが、もし見つけたら即購入していたと思います。(スキーもスノボもやらないですが)

開催期間中はブレックファストとランチをとれるコーナーがオープンします。

時間帯と場所によってメニューが違っていました。


何も考えずにおいしそうなものを取っていくと、お皿の茶色比率がだいぶ高くなります。カロリーは正義、肉こそ至高なので仕方ないですね。会場にいる間は、カロリーコントロールなどという考えは捨ててアメリカンな食事を楽しみました。
Snowflake Summit内のKeynote
今回のSummitでは、Opening Keynoteとテーマ別Keynoteを合わせて、5つのKeynoteがありました。
まずはSummitの目玉、Snowflake Summit Opening Keynoteに参加しました。会場は超満員で、私が着いた頃には入場制限が始まっていました。(のんびりブレックファストを頂いている場合ではなかった。。)制限のため、ロッジで中継を見るように誘導された方もいるようです。
ホール内はこんな感じです。始まる前からワクワクしますね!
ホール内の動画はこちら
【https://youtube.com/shorts/keL0qTk3J8o?feature=share】
Opening Keynoteで発表されたアップデートや新機能については、すでにSnowflake Blogやこちらの激アツなまとめ記事にてまとめられているので、ここでは個人的に印象に残った発表をピックアップしたいと思います。
ストレージ拡張:オンプレにあるデータも扱えちゃう
ストレージ関連の機能拡張がいくつか発表されました。まずはApache icebergをネイティブテーブルのように扱えるNative iceberg table。

「ネイティブテーブルのように扱える」とは、タイムトラベルやレプリケーションなど、通常のテーブルで可能な操作が全てできるということです。データはSnowflakeの外にあるのにSnowflakeの機能が使えるなんて、良いことしかないですね。
そして驚かされたのが、オンプレミスストレージにあるデータを外部テーブルとして扱えるようになる、という発表でした。Snowflakeといえばクラウドネイティブ、全てクラウドで…というイメージが強かったので、まさかオンプレに拡張するとは思いもよりませんでした。
別セッションで得た情報によると、接続可能なストレージはAWS S3 互換APIが使用可能なものになるようです。現在、Dell・Pure Storageとパートナーシップを組んで開発中とのことで、続報が楽しみです。
データをSnowflakeの外に置いていても、Snowflakeの性能や便利機能の恩恵を受けられる範囲がどんどん広がっていきますね。
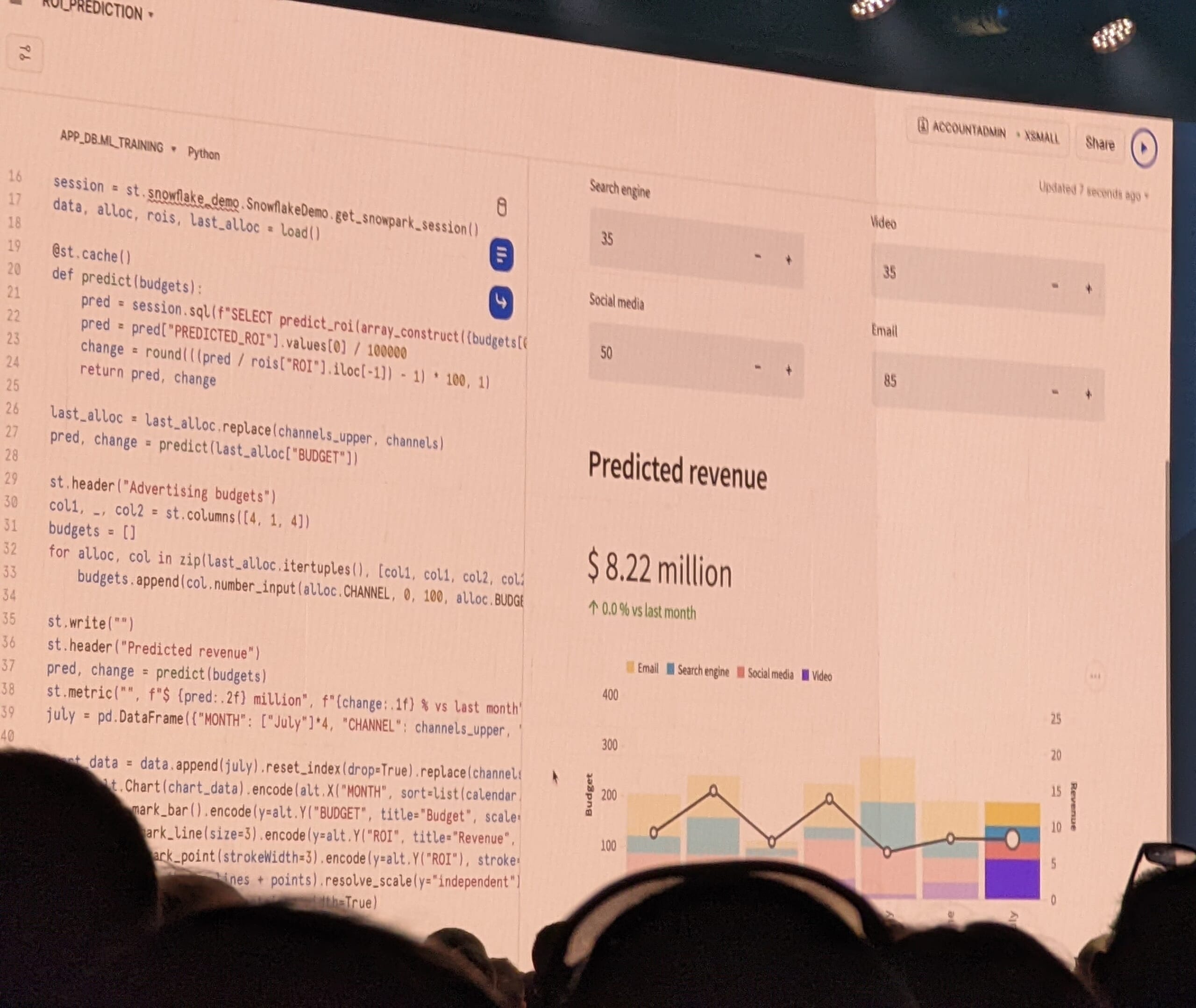
Snowpark for Python:Snowflakeで機械学習しよう
2021年のSnowdayでのプライベートプレビュー発表を経て、いよいよPythonサポートがパブリックプレビューになりました。デモでは、学習を行うコードをストアドプロシージャとしてSnowflakeに作成し、Snowflake上で学習を行う様子が実演されました。
以前、弊社メンバーがSnowparkでの機械学習を試みたのですが、当時(2021/06/30)は学習がサポートされていませんでした。その頃から「学習も推論も一貫してSnowflakeで実行させたいなあ。学習のほうがマシンパワーが必要だし、学習もSnowflakeのリソースで実行できるといいなあ…」と、学習がサポートされるのを待ち続けていたので、思わず『きたー!』と声が出てしまいました。ガッツポーズ付きで。隣の方、再びごめんなさい。
機械学習のワークフローをSnowflakeで実行できるようになれば、Snowflakeの活用範囲がさらに広がりますね!
また、機械学習向けにメモリを積んだLarge memory instanceが選べるようになるというのも、期待が高まるポイントです。

Streamlit統合:Snowflakeでデータアプリケーション
2022年3月にあったStreamlit買収の発表以来、動向がずっと気になっていたのがStreamlitでした。

まさか、Snowsight上でStreamlitで作ったアプリケーションを動かせるとは…
通常、Streamlitで作成したアプリケーションを公開するには、何かしらのサーバでStreamlitをホストするか、またはStreamlit Cloudを使う必要があります。ですが、Snowsightに組み込めればサーバの準備は不要になりますね。
また、画面左側のエディタで、Pythonコードを書けるようになっていますね。ということは、Python環境の準備すら不要で、Snowflakeアカウントを準備すればデータアプリケーション開発ができちゃうということですね。
データアプリケーションの配布が可能になる新機能 Native Application も発表され、Snowflakeでデータアプリケーションの開発も公開も可能になりそうです。Streamlitとのコラボレーションがこんな方向に進化するなんて想像していませんでした。まさに魔法…。
Unistore:OLTPとOLAPを1つのデータで
そろそろOpening Keynoteも終了かな、と思いはじめた頃、突然ステージにBenoit氏が登場。「何か重要なことを忘れているんじゃないかい?」「アプリケーションを開発するなら、OLTPが必要じゃないか!」といった掛け合いが行われたあと、満を持して最後に発表されたのがUnistoreでした。OLTPとOLAP、両方を同時に実現する新たなワークロードの登場です。

デモでは、架空のショップ「Snowshop」のデータベースとしてHybrid table(OLTPとOLAPのハイブリッド。新たなテーブルタイプ)を使用し、プライマリキーや外部キー制約が効く様子を実演していました。
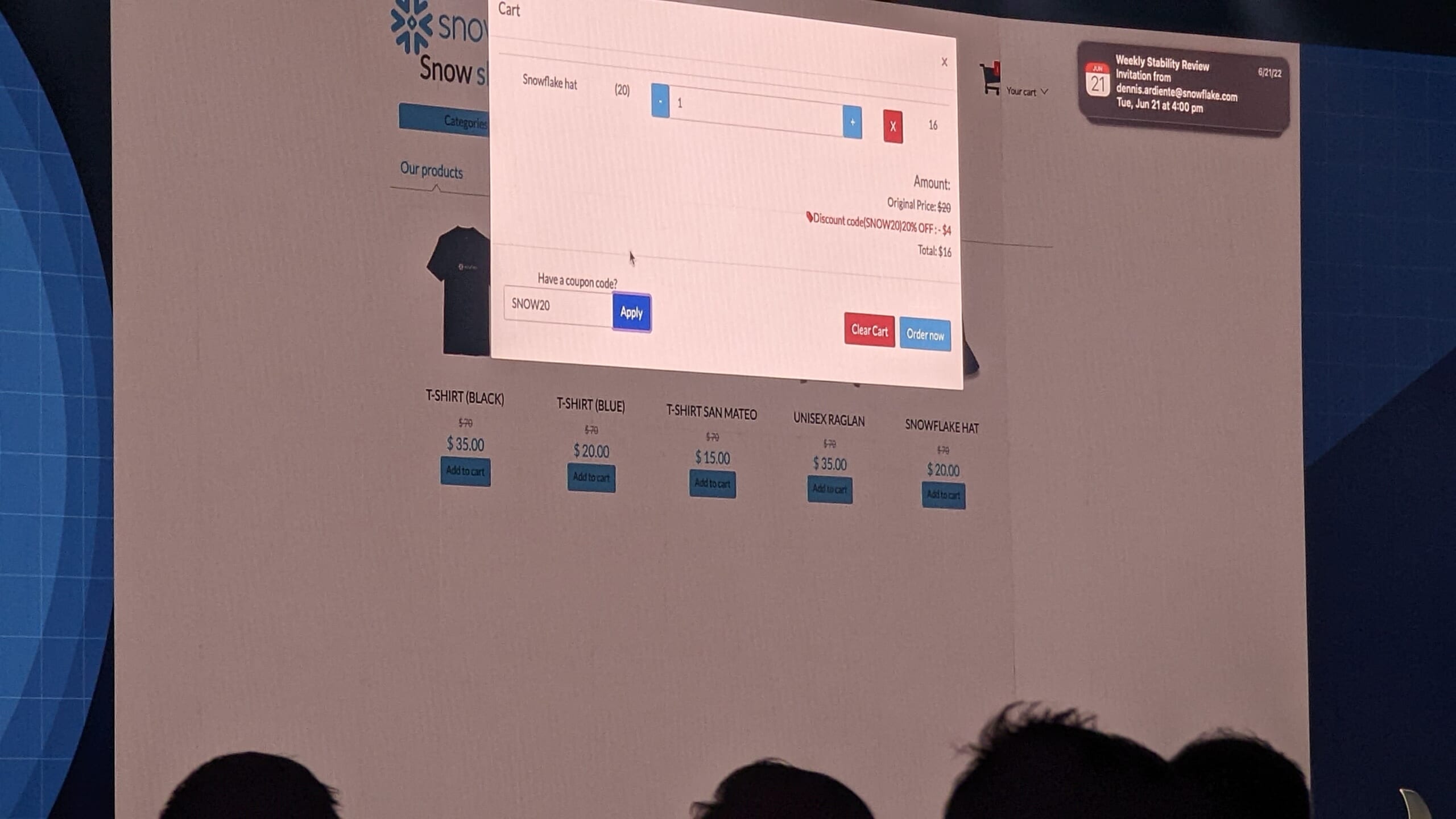
より詳しい説明をWhat’s Newセッションにて聞いてきましたので、詳細はそちらをお読みください。
特に印象に残った発表は以上です。2時間30分、エキサイティングな発表の連続でした。進化しすぎです、Snowflake。衝撃が大きすぎて、次のセッション(What’s New:Streamlit)を聞き逃してしまいました..。
今回の発表で「DISRUPT APP DEVELOPMENT」というキーワードが何度か登場しました。これまでのアプリケーション開発を破壊するという力強いメッセージですが、今回発表された様々な新機能によって、Snowflakeは本当にアプリケーション開発に革命を起こしてくれそうだと感じました。OLTPとOLAPを統合してリアルタイムでデータを活用できたり、Snowflake上でデータアプリケーションの開発と公開が簡単にできるなんて、革命ですよね。
他のKeynoteにも参加しました。こちらはKeynote: Building in the Data Cloud – Machine Learning and Application Developmentの様子です。
Snowpark for Pythonによる機械学習とネイティブアプリケーションの説明&デモ。
Opening Keynoteで紹介されたSnowpark for Pythonによる機械学習、およびNative Applicationについて、詳細に説明していました。


Snowflake Summit内のセッション
今回のSummitでは、新機能解説セッションやカスタマーセッションなど、250以上のセッションが開催されました。
ここでは、私が参加したものをピックアップしてご紹介します。
What’s New セッション
新機能セッションです。What’s New: Unistore brings transactional use cases to the Data Cloud に参加しました。大注目のUnistoreについて、Adobeの事例紹介と技術解説のセッションです。
サミットのアジェンダページによると、Keynote含めて313セッションあったようです。
まず、Unistoreの概要から。トランザクションデータと分析データが分かれていて、データをトランザクション系から分析系に移動するのに時間がかかったりすると、データへのアクセスまでにかかった時間の分だけイノベーションは遅延してしまいます。そこで、1つのデータセットでトランザクションデータも分析データも扱えるようにし、トランザクションデータに対しリアルタイム分析を可能にするのが Unistore というアプローチです。
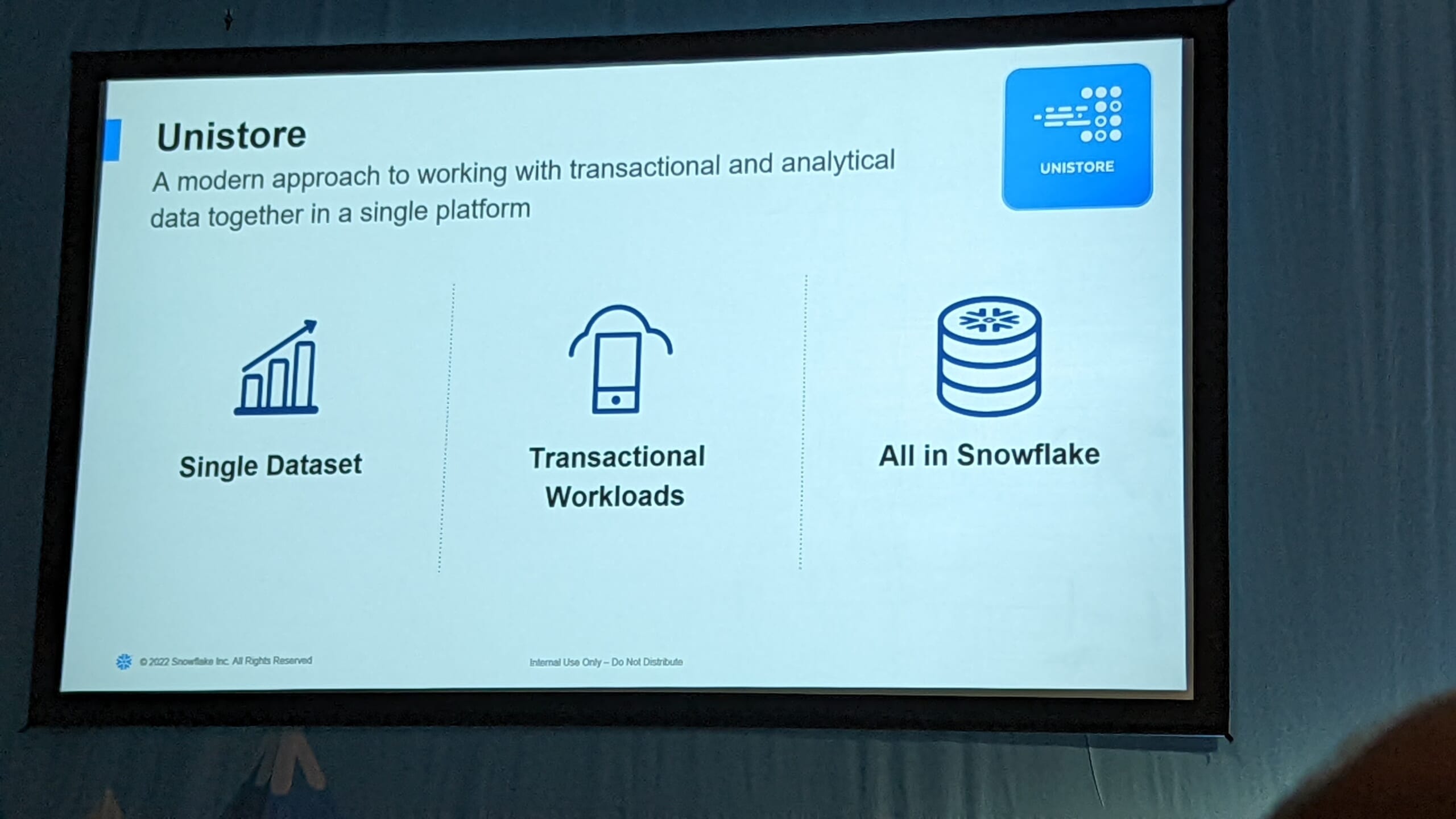
トランザクション系と分析系テーブルのハイブリッドということで、Hybrid tableという新たなテーブルで定義します。作り方は CREATE HYBRID TABLE <table_name> ( <col_name> PRIMARY KEY …) と宣言するだけ。また、通常のテーブルでは NOT NULL 以外の制約は強制されませんが、Hybrid tableではユニークキー、外部キー制約、インデックスを設定することができます。
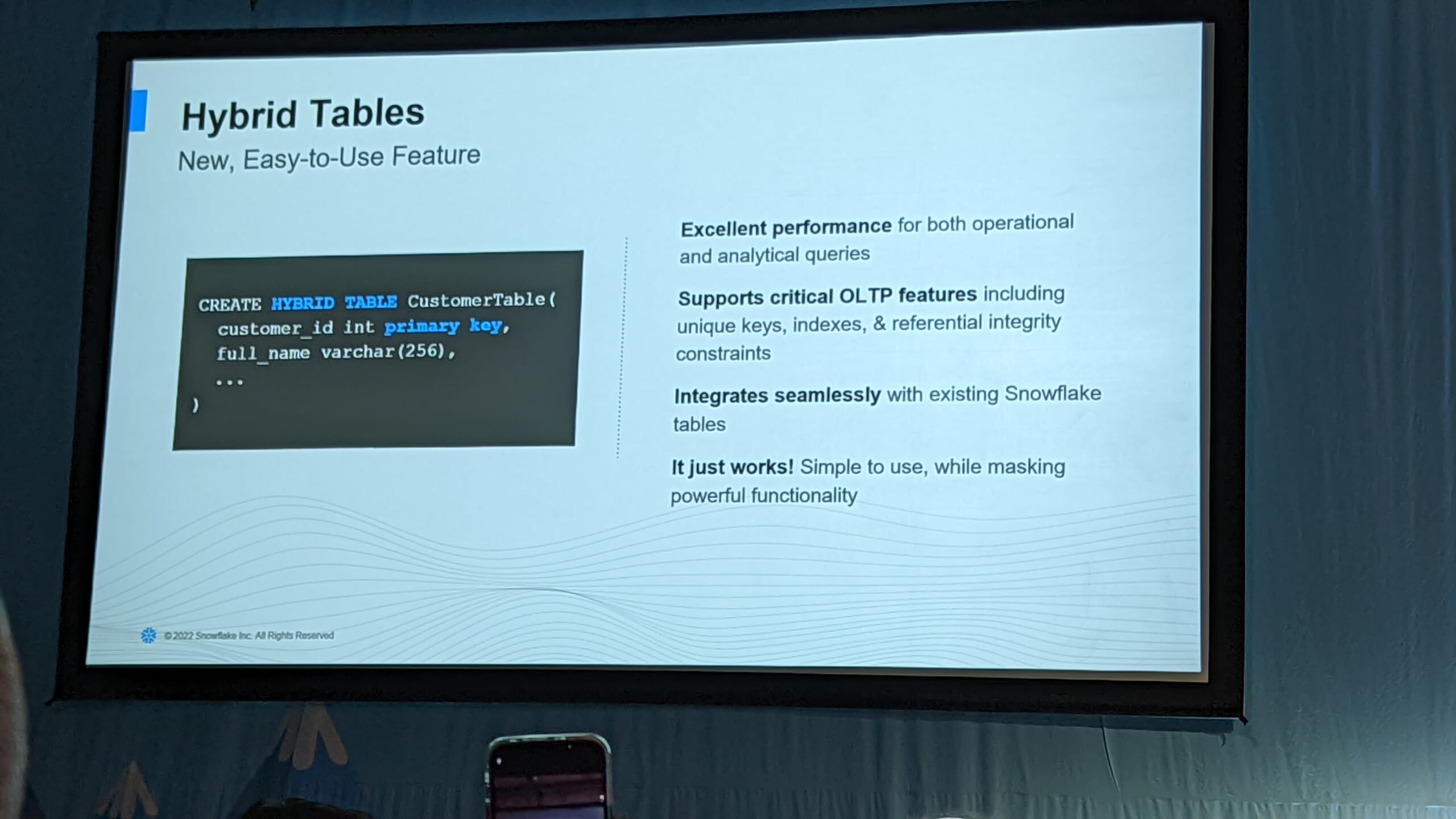
Adobeの事例では、マーケティング分析系とトランザクション系でそれぞれ分離していたデータベースをUnistoreに統合することで、プラットフォームをシンプル化した取り組みを紹介していました。既存のデータベースが持っていたワークロードの統合や、運用コストの削減も実現しているようです。Requirementsに「100-1000QPS、50-100ms latency」とあり、早く検証したい気持ちでいっぱいです。


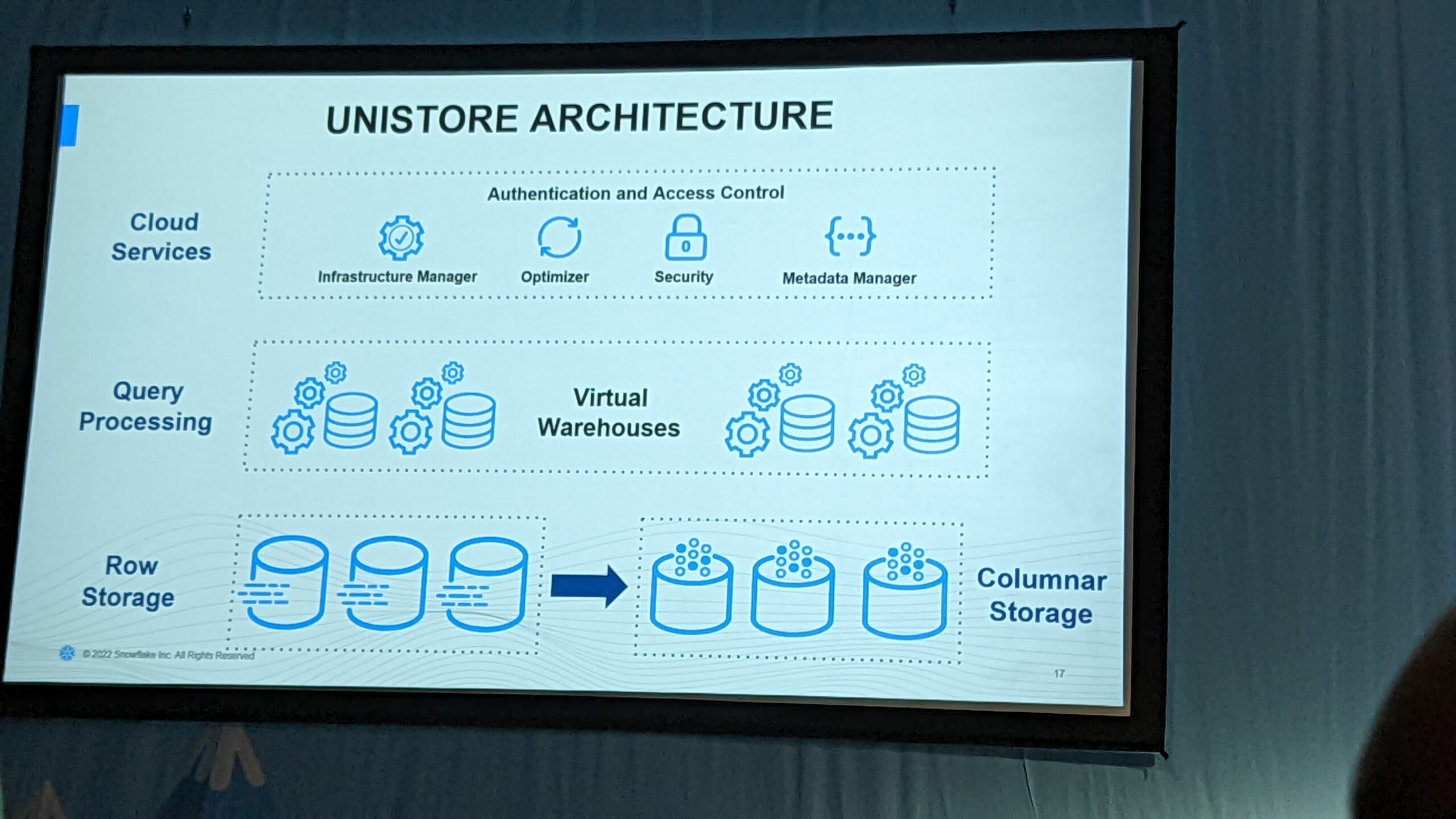
アーキテクチャの解説です。Snowflakeのデータストレージといえば列指向ストレージでした。Unistoreでは、行指向ストレージと列指向ストレージの両持ちになります。まず行指向側を更新し、それを列指向側に反映する仕組みのようです。
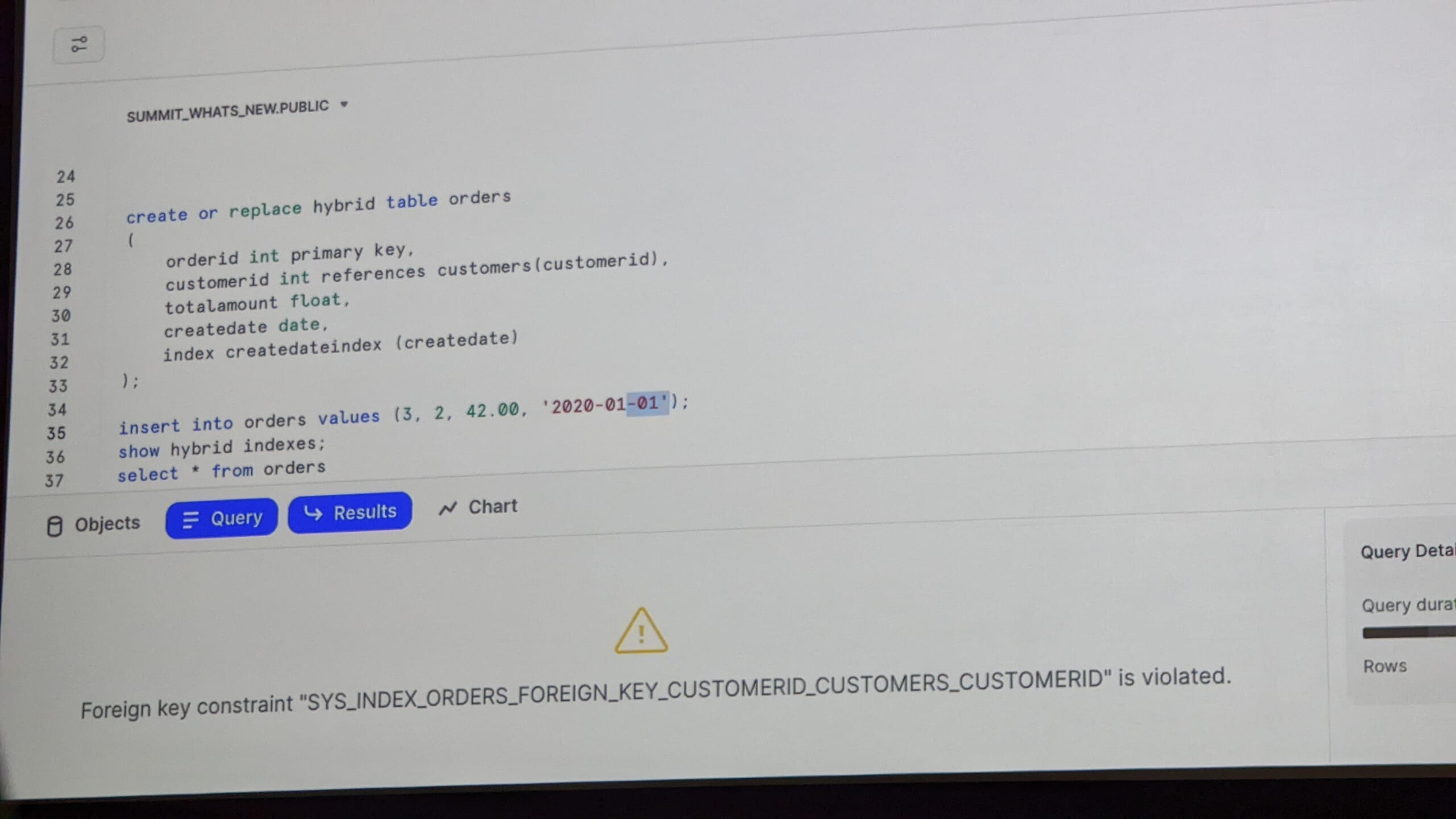
最後にデモです。ユニークキー、外部キー制約の実演でした。
デモの後は質問タイム。私が見たセッションの中では最長の質問列ができていました。別の時間枠でデモセッションが行われたのですが、そちらはほぼ質問対応で終わったそうです。
Unistoreに対する期待感がますます高まる内容でした。プライベートプレビューが待ち遠しい!
カスタマーセッション
Using Terraform to Manage Snowflake に参加しました。Indeedのエンジニアによる Terraform での Snowflake オブジェクト管理についての解説です。弊社ではTerraformを導入しているプロジェクトが多いため、これは聞かねばと思い参加しました。
まずは基本的なTerraformコードの説明。オブジェクトのコードと権限付与のコードです。
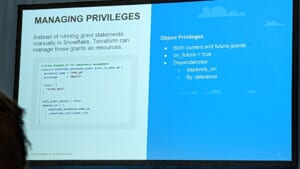
下のような複雑なパターンでは、
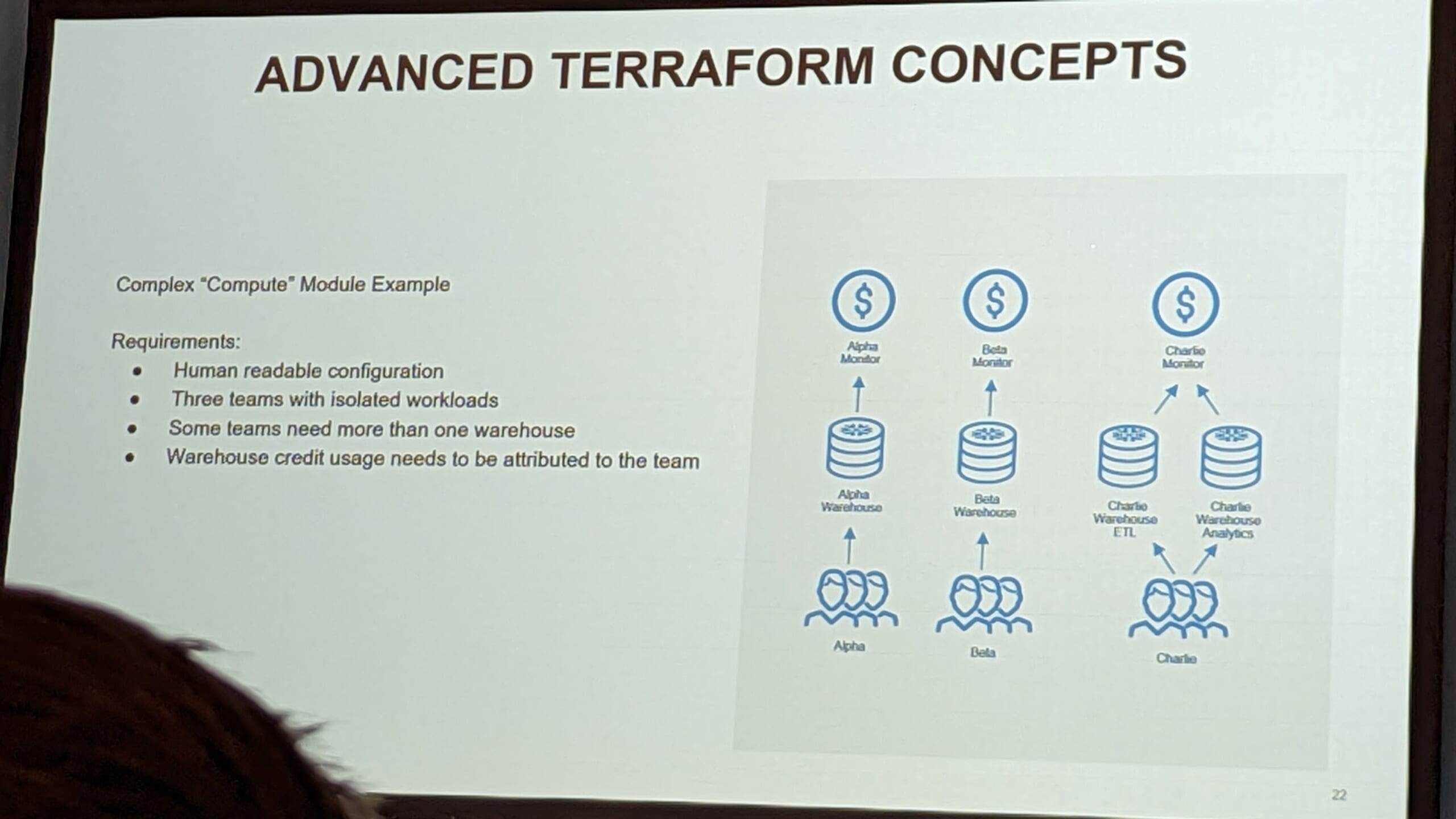
モジュール化と、設定をyamlで管理するテクニックを組み合わせていました。

デプロイやテストなど複数のカテゴリについて、ベストプラクティスの解説がありました。「デプロイプロセスでは複数アカウントに対してCI/CDパイプラインを組む」「テストはGoのTerratestで組むとよい」などなど、どれも非常にうなづける内容でした。

また、考慮すべき事項として「IdPが管理するユーザーとロールは管理できないので注意」という項目がありました。IdPがユーザーを管理しているケースはまだ検討したことがなかったので、似たケースがあったらこのセッションを思い出したいですね。
結論として、TerraformでSnowflakeオブジェクトを管理するかどうかは
・管理対象オブジェクトやユーザーが少ない場合、Terraformで管理するのはあまりうれしくないかも
・IdPが管理するユーザー&ロールがなければ最適(使えはするが範囲が狭くなる)
ということを述べられていました。
全体を通して、わかるわかるぞ…と理解のできる部分が多く、また、私がまだ使っていないテストのプラクティスや考慮事項について知見が得られ、とても良いセクションでした。思わずセッション概要ページにあるRateで★5つけちゃいました。
人気があるセッションは立ち見が出たり、入場規制されたりしていました。他に私が参加しようとしていたものでは、DevOpsセッションが満員で見られませんでした…。
今回、個人でスケジュールを立ててセッションをまわったのですが、4日間で250セッションもあるので、同時間帯に複数のセッションが開かれ、スケジュールが重なりがちでした。気になるセッションを全部スケジュールに入れたら、こんなことになっていました。

こうなってしまうので、次回は複数人で手分けしたほうが良いな、と思いました。
パートナーブース
気になるツールの詳しい話を聞きに行こう!というわけで、パートナーのブースでは、製品デモの視聴や質疑応答ができます。
Summitまで全く知らなかった会社や製品と出会えて、界隈のトレンドを知ることができ、とても良い機会でした。
ここでは、訪問したパートナーブースの一部をご紹介します。
Hightouch
リバースETLツール「Hightouch」を開発する会社です。リバースETLとは、データウェアハウスに置かれたデータを他のサービスやツールに連携して利活用できるようにすることです。ETLの逆をするので、リバースETLというわけです。
最近、私の周りでもにわかにリバースETLというワードが聞こえてきており、気になったので訪問してみました。

Alation
データガバナンス系の製品シリーズ「Alation」を扱う会社です。データに対して、データカタログやデータフローダイアグラムを参照したり、データスチュワートを割り当てるなどができます。デモはこちら。
こちらもPartner of the yearを受賞しており、授賞式で名前を知りました。
Immuta
こちらもデータガバナンス系のツールを扱う会社です。データアクセスコントロール(列レベル/行レベルセキュリティ、データマスキングなど)に長けているようです。
Snowflake以外に、Redshift、Databricks等にも対応しています。
VaultSpeed
Data Vaultモデリングツール。自動的にData Vaultモデルを構築し、ER図の書き起こしなどを行ってくれます。Data Vaultモデルを構築するのに使えるものといったらdbtVaultしか知らなかったので、まさかData Vaultモデルに特化したツールが存在するとは!
ブースでは、Tシャツをはじめとして様々なグッズを配布していました。まとめて撮影したものがこちらになります。

どの会社も(もちろんSnowflakeも)グッズがおしゃれでかわいいですね。Tシャツは普段着として頻繁に着ています。
おわりに
最後までお読みいただき、ありがとうございました。
現地で観たKeynoteの盛り上がりや、まだ存在も知らなかったツールに出会えたこと、また、他社ユーザーの皆さまと交流させて頂いたことも、全てが貴重な経験でした。
現場からは以上となります。来年も、現地からのレポートをお届けできればと思います!MAKE IT SNOW!
このページをシェアする: