大規模データを扱うダッシュボードが遅い理由と対策 Snowflakeを使った性能検証環境のご紹介

目次
はじめに
DATUMSTUDIOの生田です。
「作ったダッシュボードが遅い」。 多くの方が経験する悩みではないでしょうか。
特に、大規模データを扱う際に期待したパフォーマンスが得られないという問題に直面しがちです。
パフォーマンスは、データモデルの設計、抽出の有無、データ量、ダッシュボードの複雑さ、
インフラ構成、チューニングの作り込み、など様々な要因で決まります。
本記事では、なぜTableauのダッシュボードが遅くなるのか理由を述べます。
その上で、大規模データを扱うケースで優先して抑えるべき要因についてご紹介します。
ログや各種ツールが提供されますが、実は抽出の振る舞いを外から観察すること自体が困難です。
今回、適切なデータモデル・仕様を設計するために、Snowflakeを用いた性能検証環境を構築しました。
合わせてご紹介します。
Tableauのスケーラビリティと制約
一般に、可用性や同時実行性能はスケールアウト、性能はスケールアップによって向上します。
Tableauにおいても、高可用性構成により、可用性と同時実行性能が向上します。
また、インスタンスのスケールアップにより、表示や抽出の処理性能が向上します。
2020.3より、マルチノード展開時に抽出クエリのロードバランシングが追加されましたが、
実際構築して検証したところ、ノードの追加によって使えるメモリの限界が増えるものの、
CPUの供給力がそれほど増えないことを確認しました。
大規模データ処理時の性能を上げるには、コアノードのスケールアップに頼ることになりますが、
スケールアップの上限は決まっているため、どこかで頭打ちとなります。
限られたリソースを、データ量、ダッシュボードの複雑さ、性能などが奪い合うことになります。
UXの観点で待てる時間は限られていますから、データ量を下げて仕様を単純化する必要があります。
もしデータ量を下げられないのであれば、仕様の単純化で全てを解決する必要があります。
参照1:抽出クエリのロードバランシング
参照2:抽出クエリの負荷が大きい環境用に最適化
参照3:Hyper-charge Big Data Analytics Using Tableau
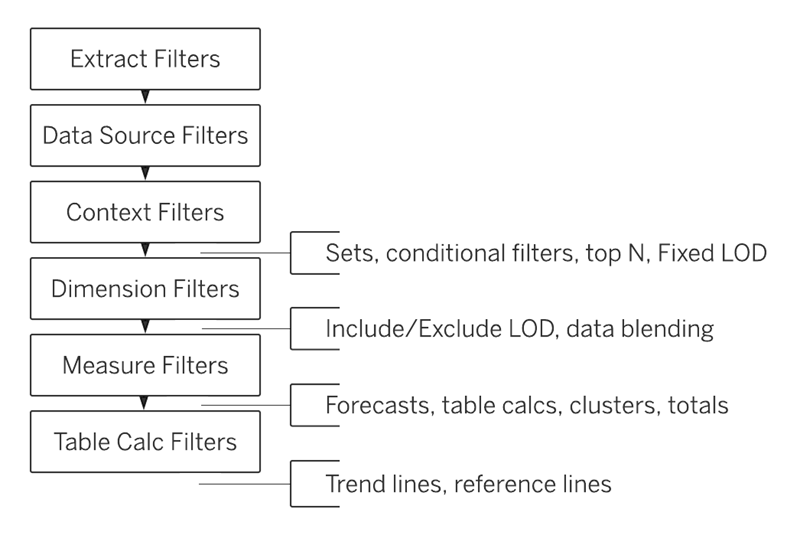
ダッシュボードが遅い理由
前提として、「UI上設定できるからといって性能は保証されない」ことに注意が必要です。
上限が限られたリソースで出来る以上の実装をしたことが遅い理由です。
大規模データを入力した場合、負荷のほぼ全ては「抽出内のクエリ」の実行となります。
その負荷を決める大きな要因は「触るデータのレコード数・データ量」と「仕様の複雑さ」です。
レコード数・データ量
論理テーブルではなく結合後のレコード数・データ量であることに注意してください。
レコード数・データ量が多くなりすぎる例としてマルチファクト分析が挙げられます。
2個以上の大きなテーブルを使ったインタラクティブな仕様を作り込めるようになっていますが、
背後では巨大な結合のため大量にCPUとメモリが消費されます。
意図せず10億行に達していた..ということもあるかと思います。
物理実装は隠蔽されますが、設定内容は最終的にクエリに反映されます。
例えば、不要なカラムがある、不要に型が広い、などによって結合後のデータ量が増えます。
大規模データの入力時にはシビアに効いてきますので、最終的な物理実装を意識してください。
複雑な仕様と実装
LOD表現やフィルタを多用して様々な機能を実現できますが、期待する性能を得られるかは別です。
仕様の複雑さに寄与する要素として、2020.3で導入されたリレーションシップの使用が挙げられます。
リレーションシップにより、粒度が異なるテーブルを効率良く共存させることが可能になりました。
ワークブックの実装が簡単になり、非常に複雑な仕様のダッシュボードを作れるようになりました。
仕様のフットプリントが大きくなると、ワークブック側の処理が増えがちです。
大規模データ入力時には、とにかく仕様のフットプリントを小さく維持する必要があります。
ワークブックのチューニングが足りない
Tableau社はホワイトペーパーで、設定内容がクエリにどう影響するのか説明しています。
また、いわゆるチューニングのテクニック集のようなものが存在します。
データ量を減らすため、または最終的なクエリをシンプルにするため、
仕様ひとつとっても、より良い実装方法と見せ方があります。
チューニング次第でトレードオフのバランスラインが動きますので、
大規模データ入力時に出来る表現を増やすために必要なプロセスです。
速くするために仕様を制限する必要があり、作り上げてからブラッシュアップする類のものではなく
先に意識して作り込むことが重要です。
参照1:効率的に作業できる Tableau ワークブックを設計するためのベストプラクティス
データマートの設計パターン
初期表示・ドリルダウンの上限として5秒を想定し、どのようなデータマートが実現可能かまとめました。
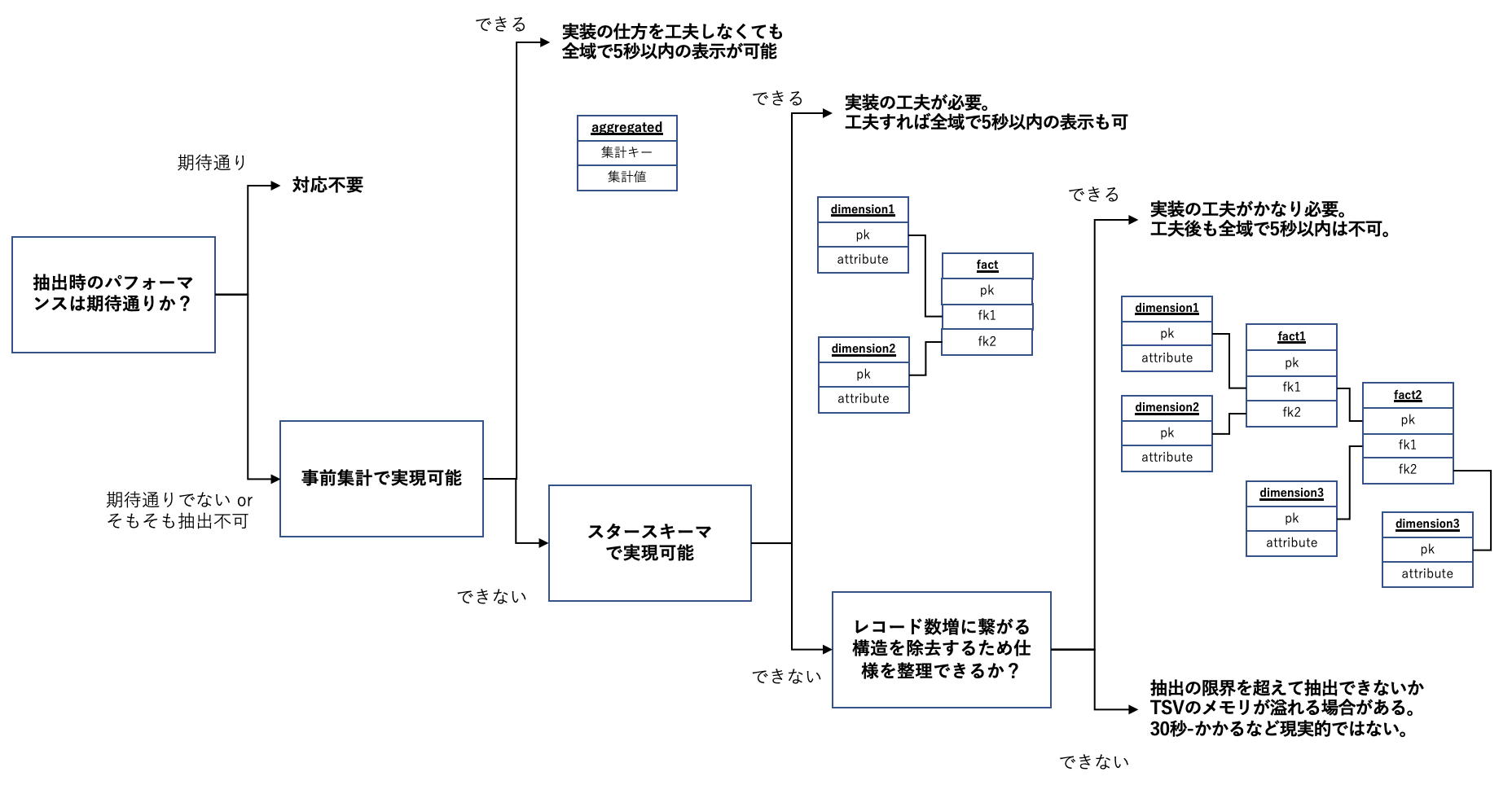
事前集計したテーブル
事前集計により、データの粒度が大きくなりレコード数・データ量が小さくなります。
データマートの値をただ表示するだけ、という実装が可能です。
ワークブックの実装の仕方をそれほど気にせず期待する性能を得られます。
入力となるデータ量に依存しなくなるため、例えファクトの量が1億行を超えても性能が変わりません。
粒度を大きくすると、より小さい粒度でフィルタできなくなるという問題が発生します。
大きなデータを探索的に様々な角度から観察したい、という用途には不向きです。
未集計のスタースキーマ
事前集計せずとも、ファクトテーブルとディメンションテーブルの距離が1のスタースキーマであれば、
仕様とチューニング次第でパフォーマンスが良いダッシュボードを作成できそうです。
フィルタとして使用できるディメンションカラムを自由に選べるメリットがあります。
大きなデータを探索的に様々な角度から観察したい、という用途に対応できます。
何も意識しないでも期待するパフォーマンスを得られる、ということはありません。
入力となるデータ量に依存するため、入力のデータ量に比例してチューニングの要求量が増えます。
あるラインで、どうチューニングしても期待したパフォーマンスを満たせなくなる可能性があります。
結合で重複があまり増えない2個以上のファクト
メジャーとディメンションの距離が2以上離れている場合、集計結果を得るために結合が必要です。
ファクト同士の重複を除去するために正規化するのですから、結合によって除去した重複が現れます。
通常、結合によってレコード数・データ量が増大します。
また、重複したデータセットから重複を除去する必要性が発生します。
後述しますが、論理テーブル内に配置した物理テーブルは抽出時にワイドテーブル化できます。
結合自体のコストはあまり重要ではなく、結合結果のレコード数・データ量・重複除去の有無が重要です。
逆に言うと、結合によってレコード数・データ量が増大せず、重複除去不要なファクト同士なら性能を維持できます。
結合で重複が増える2個以上のファクト
結合によってレコード数・データ量が増大するファクトが複数ある場合、
残念ながら、どうがんばっても期待した性能は得られないはずです。
抽出にはレコード数・データ量の限界があり、あるラインを超えるとそもそも抽出できなくなります。
もし抽出できたとしても表示時にTableauServerのメモリが枯渇したり、絞り込みに1分以上かかるなど、
もはや使い物にならないダッシュボードが出来上がります。
リレーションシップが必要な複雑なデータモデルと仕様にしない
Tableauのデータモデルは論理レイヤ、物理レイヤの2つのレイヤから構成されます。
論理テーブル間を「リレーションシップ」で繋ぐと、コンテキストに応じて動的に結合が解決されます。
対して、物理テーブル間を結合で繋ぐと、コンテキストによらず事前に結合されます。
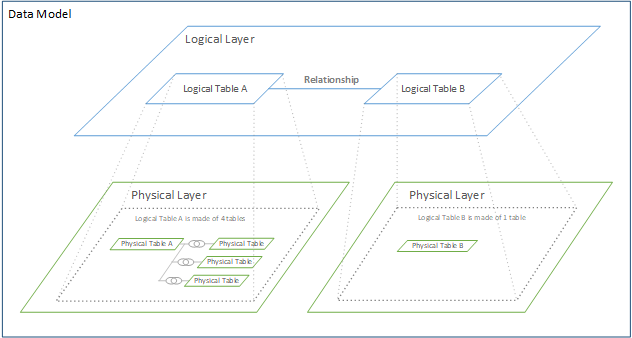
例えば1テーブルしか必要でないチャートにとっては、全テーブルの事前結合は過剰です。
また、事前結合して重複だらけになったデータセットから機能を作り込むのはかなり大変です。
これらのことから、Tableauは「リレーションシップ」の使用を推奨しています。
実際、「リレーションシップ」を使用すると、チャートの実装が非常にシンプルになります。
残念ながら、表示時に結合を解決する仕組みは、性能面でかなり不利なようです。
「リレーションシップ」の使用によって生成されるクエリが複雑になる傾向があるようです。
「リレーションシップ」がなければ実装できないようなデータモデルは複雑すぎます。
結果として大規模データの入力に耐えられないダッシュボードとなります。
スタースキーマまでは「リレーションシップ」が無くても、実装難易度に大差ありません。
マルチファクト化が「リレーションシップ」が必要か否かの境界となります。
BIと非同期タスクを併用する
2個以上のファクトテーブルを関連させなければ価値が生まれないケースはあるかと思います。
例えば下図において、Dimension1の属性2にフィルタを設定し、Fact1の属性1をDimension4の属性1ごとに合計するといったケースです。
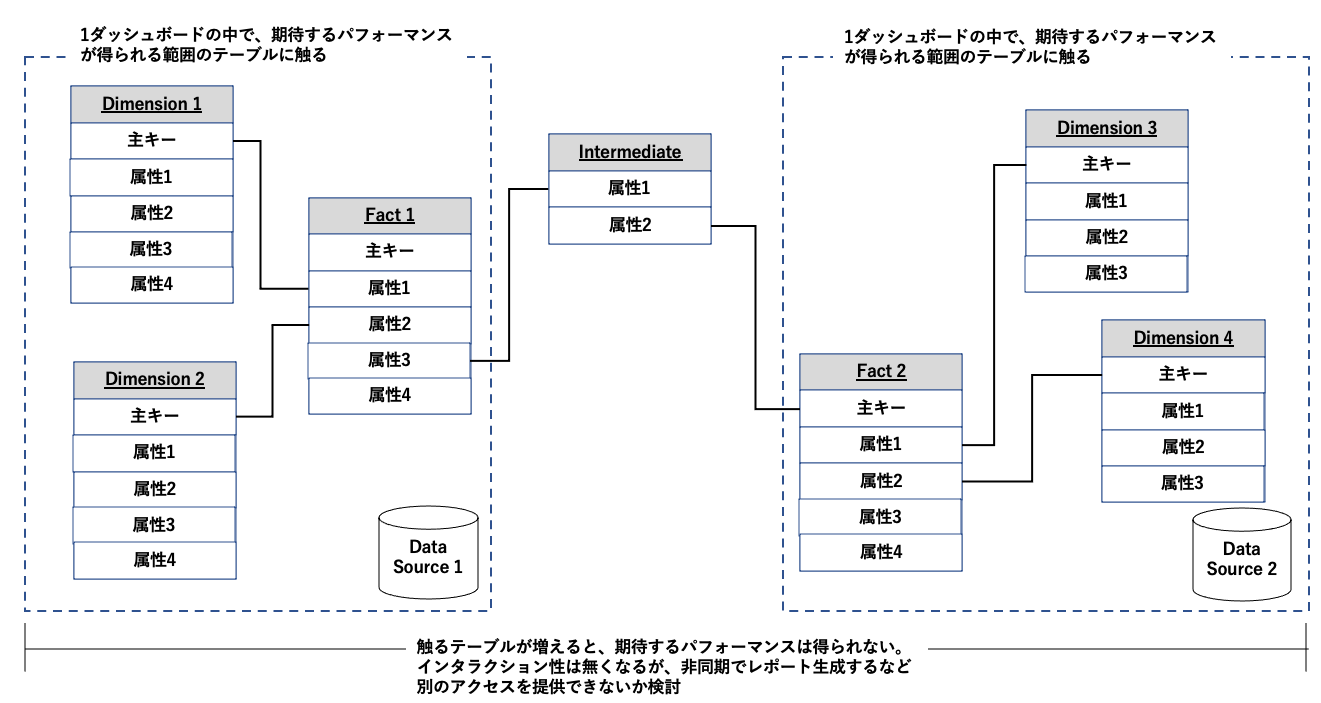
例えクエリの完了まで5分かかったとしても、非同期のバックグラウンドジョブであれば問題ない場合は多いと思います。
全てのTableauで完結するのではなく、別で非同期にレポートを生成する機能を用意することで、ある程度は需要を満たせるはずです。
ビューアクセラレーションによるクエリ結果のキャッシュ
Tableauに限らず、高速化のテクニックとして「クエリ結果をキャッシュする」という考え方があります。
実は、2020.2から2021.4までの間、Data Acceleration Clientというツールが公開されていました。
この機能により、表示に必要なクエリが事前計算され表示時に再利用されます。
ジョブとして実装されており、非同期にバックグラウンドで定期的に実行できます。
2022.1にてビューアクセラレーションとして正式にリリースされました。
Tableau ServerにてUI操作によってジョブ投入できるようになりました。
Tableau Serverにログインし、ビュー画面から機能をON/OFFすることができます。
原理的にクエリが動的に決まるフィルタやドリルダウンには効きませんが、
初期表示だけで完結する仕様であれば有効な施策です。
残念ながら、どの範囲のクエリ結果をキャッシュするのかが明確でない点と、
キャッシュの期間が不明瞭な点が使いづらいな、という感想を持ちました。
ワークブックのチューニング例.コンテキストフィルタの使い方
ワークブックのチューニングの例を1つ挙げます。
コンテキストフィルタを使うと、その選択状態とは関係なくクエリが複雑になります。
このため、コンテキストフィルタを増やせば増やすほどパフォーマンスが悪化します。
唯一、コンテキストフィルタがかなりレコード数を削減する場合に限り、効果が上回ります。
例として「検索条件」のようなUIを上げて説明します。
ダッシュボード全体に影響するフィルタを多く配置することで、探索的にデータを観察しやすくなります。
例えば、ダッシュボードの左ペインにフィルタを並べることで、ECサイトのような一般的なUIを作れます。
下図の通り、コンテキストフィルタはUIで使用する多くのフィルタよりも先に評価されますから、
「検索条件」はコンテキストフィルタによって実装されることが多いかと思います。
初期表示時には何も選択しないでしょうから、
何もしない複雑なクエリによってパフォーマンスが悪化します。
Snowflakeを使用した性能検証環境を構築する
所定のデータ量について、データマートとワークブックの複雑さをバランスさせる必要があります。
そのためには、以下の流れで試行錯誤を繰り返す必要があります。
1.データマートを設計する
2.ダッシュボードを作成する
3.データを作る
4.パフォーマンスを計測する
ただ、以下の通り、TableauServerでスロークエリを調べること自体かなり大変です。
1.大規模データの抽出には時間がかかる
2.Tableau Serverが出力するログは詳細が公開されていない。ログをgrep等で探すのは厳しい。
3.負荷テストツールであるTabJoltは同時実行性能の計測が目的。ワークブックそのものの性能を計測するのには不向き
4.「パフォーマンスの記録」機能はUI操作が前提。大規模データを入力して重くなっているダッシュボードを操作してワークブックを出力するのはツラい
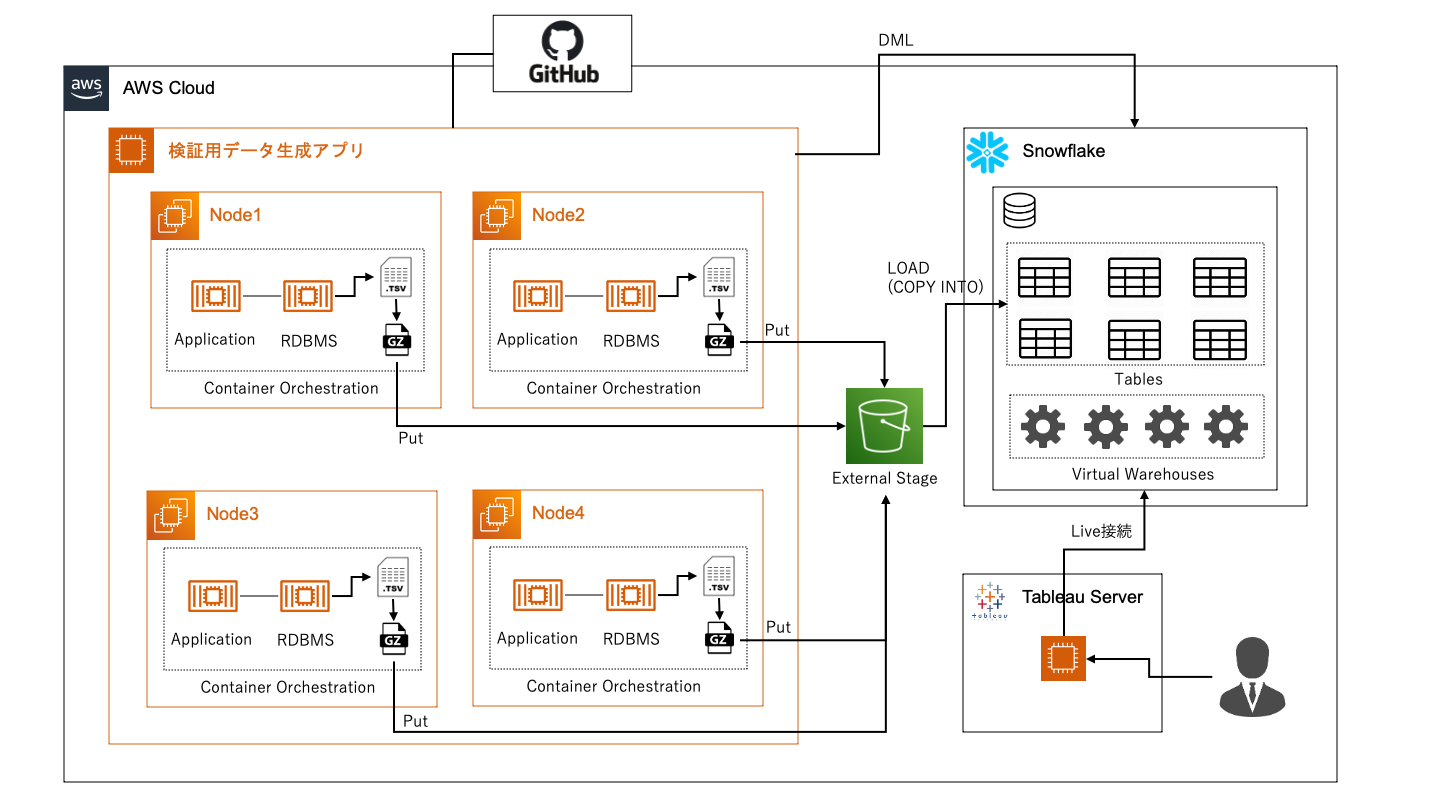
データソースとライブ接続し、データソース側でスロークエリを調べられると多くの問題が解決します。
今回、バックエンドのDBとしてSaaS DWHであるSnowflakeを使用しました。
効率的に試行錯誤を繰り返すため、下図のような環境を構築しました。
この環境について簡単に説明します。
検証用データ生成アプリ
現実には、パイプラインの入力が足りなかったり、ETLを簡単に変更できなかったり、
実運用の中でスキーマの変更を伴うデータ変更を繰り返すハードルが高い場合もあります。
プロダクションコードに触らず、あくまで検証のためのデータ生成アプリを作成すると便利でした。
試行錯誤しながら1日に何度もデータモデルを更新し施策の効果を検証できたりします。
数百万行のデータを作るとなると、それなりのコンピューティングリソースが必要です。
スケーラビリティを持たせた設計とし、必要に応じて多ノード展開できるようにしました。
ちょっとした修正や確認であればローカルのMacで動かせる、としておくと安くあがります。
例えばforループ一つとっても、書き方次第で大分性能が変わります。
1ノードの性能を上げておくとマルチノード展開したときの所要時間が短くなり、検証が捗ります。
Snowflakeの設定
仮組みとはいえ速く動けば検証が捗ります。BIのバックエンドとして一通りの設定を行いました。
1.ファイル数とデータ量調整でロード性能アップ
2.マルチクラスタウェアハウスで同時実行性能アップ
3.スケールアップでクエリ性能アップ
4.ビューアクセラレーションジョブをかけてクエリ結果キャッシュを維持
BIのバックエンドとした場合、クエリに多様性があるかと思います。
パーティショニングキーを設定したところで、より良いプルーニングが実行されない傾向がありました。
パフォーマンスの計測
Snowflakeのクエリ履歴には、クエリIDと紐づく情報としてクエリやクエリの所要時間が格納されます。
Tableauが公開していない情報となりますが、ダッシュボードのIDがクエリタグとして格納されます。
ダッシュボードIDごとにクエリ履歴を集めることで、操作と対応する所要時間を計測できます。
Tableau Server+Snowflake構成の本番運用について
24時間絶え間なくBIを触るという運用は少ないのではないでしょうか。
触る時間だけ稼働できるSnowflakeを本番運用できればかなり良さそうです。
大規模データ入力時のパフォーマンス、という観点で抽出との比較を行いました。
1.レコード数・データ量が小さい領域においては、抽出の方が速い
2.抽出が破綻する領域において、快適とは言えないものの、ある程度操作できる
3.抽出が破綻する領域において、Lサイズ/5台構成のように、それなりに高コスト
4.中間の領域において、どちらが速いかはケースバイケース。10秒は切れない。
5.TableauServer側で無視できない時間の消費が発生する
レコード数・データ量の増加に伴い、あるラインでSnowflakeのパフォーマンスが逆転します。
しかし、その領域ではいずれにせよ快適なパフォーマンスは得られないようです。
また、クエリ処理をSnowflakeに委譲したとしてもTableauServer側に無視できない負荷が残りました。
今後、OLTP統合(Unistore)によってBIのクエリ処理が改善するかもしれません。
さらに、TableauServer内のオーバーヘッドを解消できれば、より現実的となりそうです。
本記事で扱ったデータ量では不向きですが、データ量が小さければ
特にコストの観点でメリットがあることを付け加えます。
1.バックエンドをSaaSのSnowflakeとすることで保守運用のコストが下がる
2.Tableau Online+Snowflakeの構成とすることでTableauServer自体を省略できる
3.一般的なワークロードであればほぼチューニングフリーで性能を出せる
おわりに
大規模データの抽出を使ったダッシュボードが遅い理由と対策方法をまとめました。
また、重要な観点であるデータ量と仕様の複雑さに着目し、データモデルの設計パターンをまとめました。
ダッシュボードが遅い場合、これらに注目して解消を目指していただければと思います。
また、これから作成するのであれば、これらを考慮して設計・実装していただきたいと思います。
Snowflakeを使ったパフォーマンス検証環境についてご紹介しました。
最後に、大規模データ入力時にSnowflakeをバックエンドとして使用する構成の是非をまとめました。
Snowflakeについてお困りごとがあればDATUM STUDIOまでお問合せください。
このページをシェアする: