1000万件のINSERTを映画1本分ぐらい時間節約できた話
目次
こんにちは、データ事業部でインターンをしている菅野です。
先日、1000万件のデータをPostgreSQL DBにインサートしようとして150分かかりました。データ分析でよく使うPostgreSQLもデータ挿入にけっこう時間がかかるなあ。大変だなあと思っていました。
ところが、方法を変えたら7分しかかからず、20倍くらい差が出るのを知らないと時間を無駄にしちゃう。。。ということで記事を書いてシェアしたいと思います。
結論から言うと、一行ずつインサートするとめっちゃ遅くCOPYコマンドを使うとめっちゃ早くなりました。
計測方法
計測用データ件数は10万件、100万件、1000万件の3種です。計測用のファイルから、一度に挿入する行数(100件、1000件、1万件、10万件の4種ごとに実行)を一時ファイルに保存、読み出し、インサートします(文末備考参照)。
上記処理をループさせ、Pythonのpsycopg2ライブラリを通して、DBにデータを入れていきます。
なお、計測のたびにテーブルを作り直しています。
試したINSERT
一行インサート
記事を書く前は一行インサート以外、正直知りませんでした、、汗
INSERT INTO table VALUE(1,"value_1")
INSERT INTO table VALUE(2,"value_2")バルクインサート
バルクインサートは一つのクエリ文で複数のデータをインサートする関数です。
INSERT INTO table VALUE(1,"value_1"), (2,"value_2")COPY コマンド (PostgreSQL特有)
COPYコマンドとは ファイルとテーブルの間でデータをコピーするコマンドです。By PostgreSQL 9.3.2文書
COPY table FROM 'sample.csv' WITH CSV計測
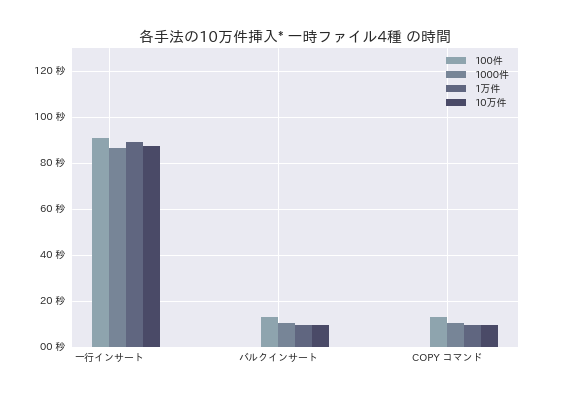
まずは、10万件のファイルを挿入してみました。x軸に3種の手法、y軸に時間となっています。
この時点で一行インサートはすごく時間がかかっています。。
次に、100万件のデータのインサートに挑戦します。一行インサートは、 正直めんどくさいので、 差が明らかなので計測していません。
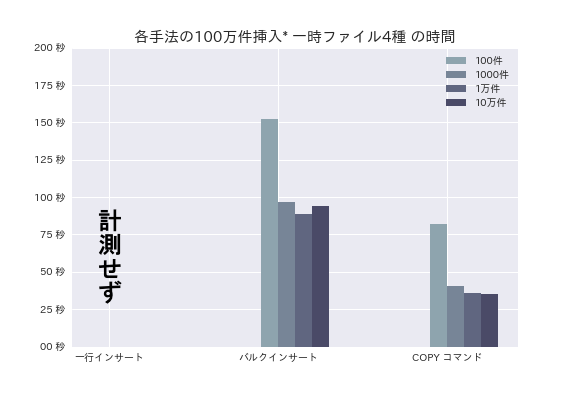
ちょこっと差が出てきました。COPY コマンドが50秒くらい早いです。
最後に、1000万件のインサートです。
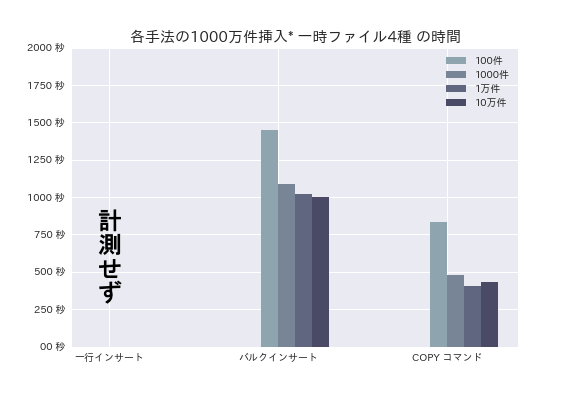
バルクインサートで30分ほど、COPY コマンドで7分ほどかかります。結果のグラフには表示していませんが、最初に書いた通り、一行インサートにだいたい150分ほどかかりました(文末の備考に記述していますが、計測方法が異なります)。
全体的な傾向として、一度に挿入する行が少なすぎると時間がかかることがわかりました。
結論
大量のデータならCOPYコマンドで圧倒的にはやいので使ってみましょう。
以上が本記事のメインの内容です。 以下の付録に、Pythonでのコード例と他に得られた知見を載せておきます。
付録
スペック
| 項目 | スペック |
|---|---|
| 実行日時 | 2017/10/19 |
| プロセッサ | 1.3 GHz Intel Core i51M |
| メモリ | 8 GB 1600 MHz DDR3 |
| Python version | 3.6 |
| Postgres version | 10.0 |
| ファイルサイズ | 10,100万,1000万の順に10MB ,107MB ,1GB。 |
実装
データベース接続方法
import psycopg2
connection = psycopg2.connect(
"host={} port={} dbname={} user={} password={}".format(
{ホスト名}, {ポート番号}, {データベース名}, {ユーザ名}, {パスワード}
))
cur = connection.cursor()
# 各インサート処理一行インサート
query = "INSERT INTO sample_table VALUES (1, 'via_python');"
cur.execute(query)
query = "INSERT INTO sample_table VALUES (2, 'via_python');"
cur.execute(query)
connection.commit()バルクインサート
execute_values関数を使用します。バルクインサートをexecute_valuesを使わずにインサートすると、SQL文に、挿入するデータの値分だけプレースホルダー(%s)を用意しないといけないので面倒臭いです。速度はCOPYとほぼ同じになります。
executemany関数ではだめです。バルクインサートっぽいexecutemany関数がpsycopg2には存在しますが、バルクインサートではありません。ドキュメントにもあるように、速くインサートできるコマンドではなく、一行インサートと同じぐらい遅いです。By Psycopg 2.7.4.dev0 documentation
from psycopg2 import extras
query = "INSERT INTO sample_table VALUES %s"
raw_list = [[1, 'via_python'],[2, 'via_python']]
tuples_list =[tuple(ls) for ls in raw_list]
extras.execute_values(cur, query, tuples_list)
connection.commit()COPY コマンド (PostgreSQL特有)
with open("ファイル名", 'r') as f:
cursor.copy_from(f, "書き込むテーブル名",
sep='区切り文字', null='null判定の文字', columns="コラム名")
f.close()
connection.commit()備考
一時ファイルを使わないバルクインサートについて
一度に挿入する行のために一時ファイルに保存しましたが、リストに格納しつつ実行すると遅くなります。
冒頭の150分かかったクエリについて
150分かかったインサートはJupyter notebook上で、1000万件ファイルからpandasのDataFrameへ100件抽出、そのDataFrameを一行ずつインサートしました。ちょっと時間計測ぐらいの軽い気持ちで実行したらめっちゃ時間かかりました。
このページをシェアする: