gensimのWord2Vecによる元素記事に含まれる単語の数値ベクトル化

本技術記事の目的
こんにちは。DATUM STUDIOの岩城です。今回の技術ブログではWikipediaの元素に関する記事をWord2Vecによって学習し、得られた分散表現から単語ベクトル同士が意味的な類似性を示すか確認します。前回の技術ブログ(1)では、自然言語処理の材料開発への応用を目指し、元素に関する記事からDoc2Vecを用いて元素の特徴量抽出に挑戦しました。計算結果を低次元変換して可視化すると、元素の記事に対応するベクトルが意味のありそうな配置を示す例を見出せました。このようにDoc2Vecは任意の文章を数値ベクトル化し文章同士の類似性を評価可能です。対してこれから利用するWord2VecはDoc2Vecと非常によく似た技術で単語の数値ベクトル化を通して単語同士の意味的な比較を行うことができます。題材とする単語は私の独断と偏見が多いに含まれますが、元素の記事をWord2Vecに学習させた結果が単語ベクトルとしてどう反映されるか観察してみましょう。
計算方法
計算はPythonで実装し下記のようなファイルの配置としました。
┣ main.py
┣ extract_atoms_data.csv
┣ ATOM.db
┣ w2vm.pickle
┣ libs/
┃ ┣ wakati.py
┃ ┣ traindb.py
┃ ┗ modelw2v.py
┗ figs/
┗ output.png
extract_atoms_data.csvはWikipediaの元素に関する記事を抽出してcsvファイルにまとめもので、元素番号(NUMBER), 元素記号(SYMBOL), 元素名(NAME), 記事内容(TEXT)が含まれます。main.pyによる処理の流れは、
1. csvデータ読み込み
2. 記事の「わかちがき」とDB登録
3. Word2Vecによる単語分散表現を得るためのモデル学習
4. 対象単語に類似度の高かった単語と類似度を抽出
5. 結果をグラフ化して保存
です。libsディレクトリのスクリプトは自作モジュールで、自分への忘備録という意味を込めて公開すると、
wakati.py(わかちがき処理用)
# -------------------------------
# モジュールインポート部分
# -------------------------------
import os
import time
import tqdm
import numpy as np
import pandas as pd
import MeCab
# ---------------------------------
# クラス定義や関数定義の部分
# ---------------------------------
# 単語リストを半角空白で結合された1行テキストに変換する関数
def list2line(words_list):
line = ""
for word in words_list:
line += word
line += " "
return line[:-1]
# 分かち書き用のクラス定義
class Wakati:
# コンストラクタの定義
def __init__(self, text):
self.text = text
self.tokens = None
self.targets = ["名詞", "動詞", "形容詞"]
self.stopwords = ["する", "もの", "れる", "ない", "られる", "こと", "ある", "ため", "これ", "いる", "なる", "よる", "よう"]
# 分かち書きを行うメソッド
def tokenize(self):
words = self.get_words()
self.tokens = self.get_stopped_words(words)
return self.tokens
# テキストの形態素解析結果をDataFrameで返す関数
def get_dfw(self):
t = MeCab.Tagger("Owakati")
t.parse("")
node = t.parseToNode(self.text)
surfaces = []
stems = []
poss = []
while node:
surface = node.surface
feature = node.feature.split(",")
stem = feature[6]
pos = feature[0]
surfaces.append(surface)
stems.append(stem)
poss.append(pos)
node = node.next
df = pd.DataFrame()
df["SURFACE"] = surfaces[1:-1]
df["STEM"] = stems[1:-1]
df["POS"] = poss[1:-1]
return df
# 形態素解析から対象となる品詞の単語リストを返す関数
def get_words(self):
df = self.get_dfw()
words = []
for row in df.iterrows():
for target_pos in self.targets:
if row[1]["POS"] == target_pos:
if row[1]["STEM"] != "*":
words.append(row[1]["STEM"])
return words
# 単語リストにストップワードを適用した結果を返す関数
def get_stopped_words(self, words):
stopped_words = [word for word in words if word not in self.stopwords]
return stopped_wordstraindb.py(DB処理用)
# ------------------------
# Module import
# ------------------------
import os
import time
import tqdm
import sqlite3
import pandas as pd
from libs.wakati import Wakati
# ------------------------
# Class definition
# ------------------------
class TrainDB:
"""学習用データに関するSQLiteDBのためのクラス."""
def __init__(self, dbpath="./ATOM.db", tablename="ATOMDATA"):
"""コンストラクタ."""
self.dbpath = dbpath
self.tablename = tablename
def is_db(self):
"""DBが存在しなければ新たに作成する."""
if os.path.exists(self.dbpath) is False:
conn = sqlite3.connect(self.dbpath)
conn.commit()
conn.close()
def is_table(self):
"""TABLEが存在しなければ新たに作成する."""
conn = sqlite3.connect(self.dbpath)
cursor = conn.cursor()
sql = "select * from sqlite_master"
cursor.execute(sql)
conn.commit()
contents = cursor.fetchall()
tables = [content[1] for content in contents]
conn.close()
if not self.tablename in tables:
conn = sqlite3.connect(self.dbpath)
cursor = conn.cursor()
sql = "create table {}(".format(self.tablename)
sql += "number real,"
sql += "symbol text,"
sql += "name text,"
sql += "text text,"
sql += "token text)"
cursor.execute(sql)
conn.commit()
conn.close()
def writerow(self, rowdata):
"""1行分のテキストをDBへ書き込む."""
conn = sqlite3.connect(self.dbpath)
cursor = conn.cursor()
embedding = "?," * len(rowdata)
embedding = embedding[:-1]
sql = "insert into {} values({})".format(self.tablename, embedding)
cursor.execute(sql, rowdata)
conn.commit()
conn.close()
def listdata2linetext(self, listdata):
"""単語リストを半角空白で結合したテキストへ変換する."""
linetext = ""
for word in listdata:
linetext += word
linetext += " "
return linetext[:-1]
def initialize(self):
"""DBの初期化設定を行う."""
self.is_db()
self.is_table()
def make(self, csvpath="../extract_atoms_data.csv"):
"""csvファイルからデータを読み込み、分かち書きを行った上、結果をDBに書き込む."""
# DB初期化
self.initialize()
# csvファイル読み込み
df = pd.read_csv(csvpath, encoding="utf8")
# 分かち書き
tokens = [self.listdata2linetext(Wakati(textdata).tokenize()) for textdata in tqdm.tqdm(df["TEXT"])]
# 列追加
df["token"] = tokens
for i, row in tqdm.tqdm(df.iterrows()):
self.writerow(row)
def read(self):
"""SQliteDBからデータを読み込みDataFrameで返す."""
conn = sqlite3.connect(self.dbpath)
sql = "select * from {}".format(self.tablename)
df = pd.io.sql.read_sql_query(sql, conn)
conn.close()
return dfmodelw2v.py(Word2Vec処理用)
# ------------------------
# Module import
# ------------------------
import os
import time
import tqdm
import pickle
import pandas as pd
from gensim.models.word2vec import Word2Vec
# ------------------------
# Class definition
# ------------------------
class ModelWord2Vec:
"""Word2Vecによる単語分散表現を得るためのクラス."""
def __init__(self):
"""コンストラクタ."""
pass
def get_sentences(self, tokens):
"""DBの分かち書きされたtokenデータから学習用データに整形して返す.
tokens = [
"token_11 token_12 ... token_1m",
"token_21 token_22 ... token_2m",
...,
"token_n1 token_n2 ... token_nm"
]
sentences = [
[token_11, token_12, ..., token_1m],
[token_21, token_22, ..., token_2m],
...,
[token_n1, token_n2, ..., token_nm]
]
"""
sentences = [token.split(" ") for token in tokens]
return sentences
def train(self, params, tokens):
"""Word2Vecのモデルを作成してクラスに必要な属性を格納する.
params = {
"size":,
"window":,
"min_count":,
"iter":,
}
"""
sentences = self.get_sentences(tokens)
model = Word2Vec(
sentences,
size=params["size"],
window=params["window"],
min_count=params["min_count"],
iter=params["iter"]
)
self.params = params
self.sentences = sentences
self.model = model
def save(self, modelpath):
"""学習したモデルを保存する."""
with open(modelpath, "wb") as f:
pickle.dump(self, f)
print("Trained model is saved as {}".format(modelpath))
def load(self, modelpath):
"""保存した学習済みモデルを含むオブジェクトを読み込む."""
with open(modelpath, "rb") as f:
obj = pickle.load(f)
self.params = obj.params
self.sentences = obj.sentences
self.model = obj.modelです。3. Word2Vecによる単語分散表現を得るためのモデル学習ではモデルに関して設定すべきパラメータがいくつか存在します。基本的にはgensim.models.word2vecライブラリの説明(2)にあるデフォルト設定で上手くいくことが多いですが、今回は学習データ量の少なさを考慮し計算回数を多めに変更しました(iter=5 —> iter=25)。4. 対象単語に類似度の高い単語とスコアを抽出 は、Word2Vecの model.most_similar()メソッドを利用しています。メソッドで計算される類似度は単語ベクトル同士のコサイン類似度が採用されているようです。ちなみに対象単語の分散表現である数値化された単語ベクトルは model.wv[targetword]を適用して取り出せます。最後に1. ~ 5.の一連の流れを実行するmain.pyは
main.py(一連の処理を行う)
# ------------------------
# Module import
# ------------------------
import os
import time
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from libs.traindb import TrainDB
from libs.modelw2v import ModelWord2Vec
# ------------------------
# Function definition
# ------------------------
def makedb(csvpath, dbpath, tablename):
"""Word2Vec計算用のDBを作成する."""
tdb = TrainDB(dbpath, tablename)
tdb.make(csvpath)
def trainsave(modelpath, dbpath, tablename, params):
"""Word2Vecによる学習を行い、モデルを含むオブジェクトを保存する."""
tdb = TrainDB(dbpath, tablename)
df = tdb.read()
tokens = df["token"]
mw2v = ModelWord2Vec()
mw2v.train(params, tokens)
mw2v.save(modelpath)
def loadobj(modelpath):
"""学習済みモデルを含むオブジェクトを読み込み、返す."""
mw2v = ModelWord2Vec()
obj = mw2v.load(modelpath)
return obj
def get_df_topn(modelpath, targetword, topn):
"""Word2Vecのモデルより指定した単語と最も類似度の高い上位n単語をDataFrameに整理して返す."""
mw2v = ModelWord2Vec()
mw2v.load(modelpath)
components = mw2v.model.most_similar(targetword, topn=topn)
df = pd.DataFrame()
df["rank"] = [i + 1 for i in range(len(components))]
df["word"] = [component[0] for component in components]
df["score"] = [component[1] for component in components]
return df
def make_figure(outdir, modelpath, targetword, topn):
"""類似度順データの棒グラフを作成・保存する."""
if os.path.exists(outdir) is False:
os.mkdir(outdir)
df = get_df_topn(modelpath, targetword, topn)
df = df.sort_values(by="rank", ascending=False)
plt.figure()
plt.barh(df["rank"], df["score"], color="blue", alpha=0.6)
plt.yticks(df["rank"], df["word"])
plt.title("Top {} word for {}".format(topn, targetword))
plt.xlabel("Score")
plt.ylabel("Word")
filename = "{}_topn_{}.png".format(targetword, topn)
outpath = outdir + filename
plt.savefig(outpath, bbox_inches="tight")
plt.close()
# ------------------------
# Constant setting
# ------------------------
CSVPATH = "./extract_atoms_data.csv"
DBPATH = "ATOM.db"
TABLENAME = "ATOMDATA"
OUTDIR = "./figs/"
# ------------------------
# Main processing
# ------------------------
if __name__=="__main__":
modelpath = "./w2vm.pickle"
# DB作成とWord2Vecモデルの学習
#params = {
# "size":200,
# "window":5,
# "min_count":1,
# "iter":25
#}
#makedb(CSVPATH, DBPATH, TABLENAME)
#trainsave(modelpath, DBPATH, TABLENAME, params)
# 類似度上位の結果を取得し保存する
topn = 20
targetword = "ガリウム"
make_figure(OUTDIR, modelpath, targetword, topn)となります。最終出力は対象単語に類似度が高い単語とスコアを棒グラフ化したもので、png画像がfigsディレクトリに保存されます。
対象単語と類似度が高かった上位20単語の例
今回は対象単語として自分の古きドメイン知識を活かせる「半導体」、「ガリウム」、「ヒ化ガリウム」を取り上げてみました。Wikipediaの元素記事を元にWord2Vecで構成した単語ベクトルが本当に意味のある妥当な類似性を示したか、対象単語ごとに確認します。
対象単語 = 「半導体」の例
対象単語 = 「半導体」の単語ベクトルと類似度が高かった上位20単語およびそのスコアは下図のようになりました。
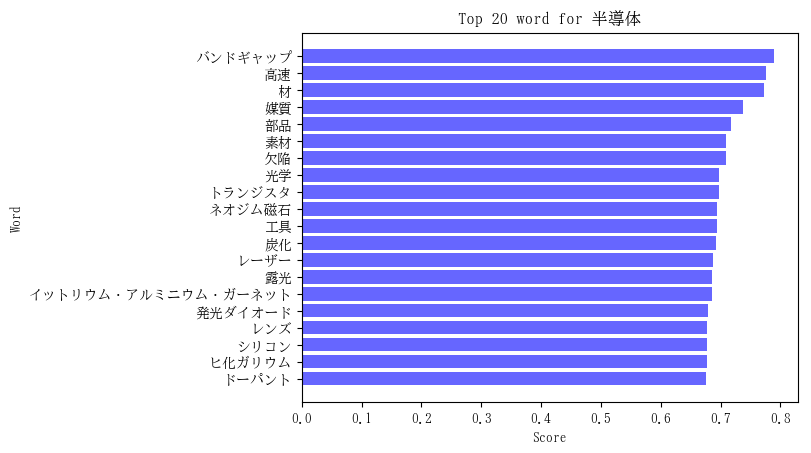
特筆すべき関連単語を列挙すると、
- バンドギャップ(1位):半導体物性で最も重要な材料のエネルギー構造に関わる言葉です。
- 欠陥(7位):半導体材料の質に関係します。
- トランジスタ(9位):半導体デバイスの例です。
- レーザー(13位):半導体レーザーとして身近なところで利用されています。
- 発光ダイオード(16位):いわゆるLEDです。これも半導体が利用されています。
- シリコン(18位):現代テクノロジーを基盤を支える半導体です。
- ヒ化ガリウム(19位):化合物半導体の代表例です。
- ドーパント(20位):添加される不純物です。半導体の物性に大きく影響します。
となります。一般的な関連単語(媒質、部品、素材 …)などを含めると、上位20のほとんどが半導体に関係性の強いもので
した。学習データ量が少なくユニークな単語は高々12018語ですが、トップ20の大部分を違和感ない結果で占められたと言えるでしょう。
対象単語 = 「ガリウム」の例
対象単語 = 「ガリウム」の単語ベクトルと類似度が高かった上位20単語およびそのスコアは下図のようになりました。
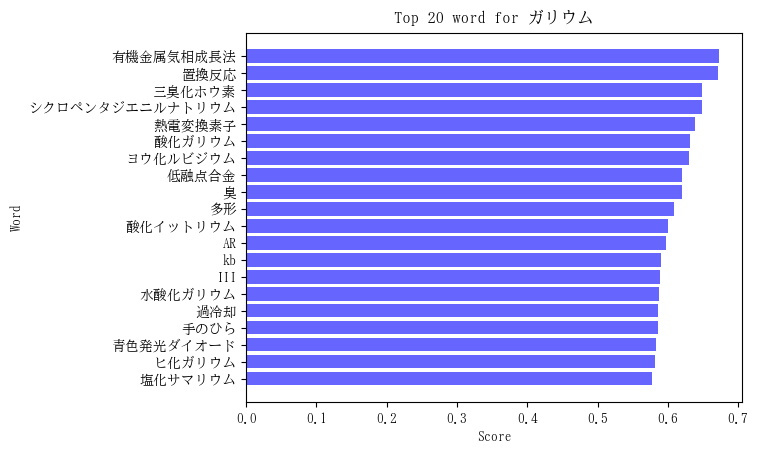
同様に自分の思い入れの強い単語を列挙すると、
- 有機金属気相成長法(1位):半導体結晶成長方法の一つです。
- 青色発光ダイオード(18位):窒化ガリウム(GaN)が材料です。原料にガリウムが含まれます。
- ヒ化ガリウム(19位):ヒ素とガリウムの化合物(GaAs)です。
です。一般的に耳慣れない言葉ですが、1位の「有機金属気相成長法」(Metal Organic Chemical Vapor Deposition)
は化合物半導体である窒化ガリウムやヒ化ガリウムの有力な結晶成長法です。基板に原料ガスを吹き付けて薄膜結晶を成長させます。対象単語「ガリウム」に対して多数ある単語の中からこれほど専門的なものが関連度1位になるとは思ってもみませんでした。自分の想像以上の結果を目の当たりにするとAI(機械学習)への愛着が増します。自分は半導体分野への知識に偏っているので、上位20に含まれた他の単語に言及できませんが、別のドメイン知識を有する人が見ればまた違った解釈もできるでしょう。
対象単語 = 「ヒ化ガリウム」の例
対象単語 = 「ヒ化ガリウム」の単語ベクトルと類似度が高かった上位20単語およびそのスコアは下図のようになりました。
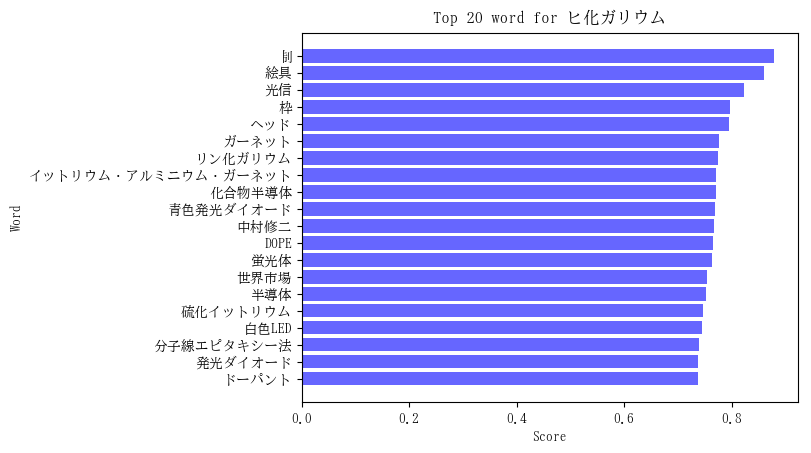
恣意的に特筆すべき関連語を列挙すると、
- リン化ガリウム(7位):GaPでヒ化ガリウム(GaAs)の仲間です。
- 化合物半導体(9位):ヒ化ガリウムは化合物半導体です。
- 青色発光ダイオード(10位):ヒ化ガリウムと仲間の窒化ガリウム(GaN)が材料です。
- 中村修二(11位):青色発光ダイオード開発に従事されたノーベル物理学賞受賞者です。
- DOPE(12位):不純物を添加することです。半導体の物性に極めて重要です。
- 蛍光体(13位):発光ダイオードの発光特性を変化させるために用いられます。
- 半導体(15位):ヒ化ガリウムは半導体です。
- 分子線エピタキシー法(18位):有機金属気相成法とは別の半導体結晶成長方法です。
- 発光ダイオード(19位):ヒ化ガリウムも発光ダイオードに使用されます。
- ドーパント(20位):半導体に添加される不純物のことです。
となります。「青色発光ダイオード」と「中村修二」は窒化ガリウム(GaN)に関連した単語なので、対象単語の「ヒ化ガリウム」と直接関連するわけではありませんが、関連知識として重要な位置付けであることに変わりありません。ちなみに窒化ガリウム(Gallium Nitride)のGaNと深層学習(Deep Learning)で頻出のGAN(Generative Adversarial Network)とは別物です。
言語の意味としての粒度は「半導体」>「ガリウム」>「ヒ化ガリウム」でしょうが、上記例に示した通り、どの対象単語についても適切な関連語が上位に提示され、学習された言語空間が意味のある単語ベクトルで構成されていると推測されます。
まとめ
Word2Vecを用いてWikipediaの元素に関するテキストデータを学習させ、数値化した単語ベクトルを構築しました。自分のドメイン知識のある単語を選択し、対象単語と関連の高い単語を列挙すると納得がいく結果が得られました。これによりWord2Doc2Vecを通じた分散表現が妥当な意味空間を形成していると類推されます。個人的には Neural Networkアルゴリズムに基づくWord2VecやDoc2Vecなどの自然言語処理技術をマテリアルズ・インフォマティクス(materials informatics)へ展開すれば、興味深い新たな知見が得られるだろうと期待しています。
参考URL
このページをシェアする: