Doc2Vecを用いたテキストデータからの元素の特徴量抽出
本技術ブログの目的
こんにちは。DATUM STUDIOの岩城です。本技術ブログではWikipediaの元素に関するテキストデータ1)から元素特徴量の抽出を試みます。近年、材料開発の分野でもデータ利用が盛んで(materials informatics)2)、日本でも国立研究開発法人物質・材料研究機構(NIMS)の情報統合型物質・材料開発イニシアティブ(MI2I)3)が有名なようです。材料開発における特徴量と言えば素材となる元素の観測された物理量や化学量及び理論値などですが、ここではテキスト由来の情報を自然言語処理の分散表現によって利用可能な状態に出来ないか挑戦してみます。
分散表現とは
テキストやその構成要素である単語は、そのままでは数値計算出来ません。そこでテキストや単語を計算可能な数値ベクトルに変換する、分散表現が必要となります。単語の分散表現には周辺単語の並びを学習し単語の意味ベクトルを生成するWord2Vec4)という手法がよく用いられます。今回はテキストの分散表現を得るためにWord2Vecの親戚であるDoc2Vec5)を適用しました。Word2VecやDoc2Vecの仕組みについては他の専門書に委ねます。
Doc2Vecによる分散表現の計算
Doc2Vecによる分散表現取得の処理の流れは
(1) 各元素テキストの「わかちがき」
(2) TaggedDocumentを用いたDoc2Vec学習用データ準備
(3) Doc2Vecの学習モデル計算
上記の通りです。(1)~(3)の処理に係るPythonコード例を下記に記します。(1)の「わかちがき」に関しては私の前回のblog6)で用いたものを自作モジュールとして転用しました。(2)の工程はコード中のget_d2v_documents()関数に対応しており、TaggedDocumentにデータを適用させています。TaggedDocumentを使用する上での注意点は、tagsを文字列でなく
tags = [“tag word”]
とリストにすべき点とwordsが「わかちがき」された単語リストとして
words = [“word_1”, “word_2”, …]
の形式となる点です。Doc2vecの学習はget_d2v_model()関数で計算していますが、いくつかのパラメータが存在します。分散表現で数値ベクトル化する際の次元数はsizeにより指定可能でここでは200次元に設定しました。min_count, iterは単語の最小出現頻度、計算回数を意味します。これらのパラメータは計算結果に多大な影響を及ぼすため、十分な検討が必要そうです。
# --------------------------------------
# Module import
# --------------------------------------
import tqdm
import numpy as np
import pandas as pd
from gensim.models.doc2vec import Doc2Vec
from gensim.models.doc2vec import TaggedDocument
from libs.wakati import Wakati # 自作モジュール
# -----------------------------------------
# Function definition
# -----------------------------------------
def get_df(path):
"""csvファイルからDataFrameを取得する."""
return pd.read_csv(path, encoding="utf-8")
def get_token_list(text_list):
"""テキストリストから分かち書きされた単語リストを取得する."""
token_list = [Wakati(text).tokenize() for text in tqdm.tqdm(text_list)]
return token_list
def get_d2v_documents(tag_list, token_list):
"""Doc2Vec学習用データを生成する."""
documents = []
for tag, token in zip(tag_list, token_list):
documents.append(TaggedDocument(tags=[tag], words=token))
return documents
def get_d2v_model(documents):
"""Doc2Vecで学習したモデルを取得する."""
model = Doc2Vec(
documents=documents,
size=200,
min_count=1,
iter=5
)
return model
def get_df_docvecs(path):
"""各元素の200次元の分散表現(ベクトル)をDataFrameで取得する."""
df = get_df(path)
tag_list = list(df["SYMBOL"])
text_list = list(df["TEXT"])
token_list = get_token_list(text_list)
documents = get_d2v_documents(tag_list, token_list)
model = get_d2v_model(documents)
df_docvecs = pd.DataFrame()
for tag in tag_list:
df_docvecs[tag] = model.docvecs[tag]
df_docvecs = df_docvecs.T
return df_docvecs
# ----------------------------------------
# Main processing
# ----------------------------------------
if __name__=="__main__":
path = "extract_atoms_data.csv"
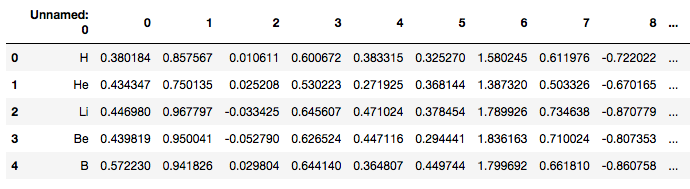
df_docvecs = get_df_docvecs(path)元素記事の分散表現の結果
各元素の記事と前節の処理で得られたの分散表現の結果を下表に記します。例えば水素(H)に着目すると、「水素 水素(すいそ、、、)は、原子番号1,原子量1.00….」というテキストが
「0.389184 0.857567 …..」という数値ベクトルに変換できたことがわかります。元素を示す特徴がテキストではなく表のような数値ベクトルであれば、内積計算などを通じて定量的な評価を行えます。仮に水素(H)とヘリウム(He)の類似性を知りたければ、分散表現で計算されたベクトル同士のコサイン距離を求めて類似度の指標を得るといった具合です。ちなみにDoc2Vecのモデルにはテキスト同士の類似度を計算する、most_similar() などのメソッドが用意されています。
<Wikipediaから抽出した元素のテキスト>

<元素テキストのDoc2Vecによる分散表現>
自然科学における元素を表す特徴量は、[元素番号、原子量、電気陰性度….]などが挙げられます。元素の特徴量にテキスト情報をそのまま付与することは不可能ですが、上表のような数値ベクトル要素は物理・化学量と同じように取り扱えます。自然言語処理(Natural Language Processing:NLP)の対象となるテキストは確かに曖昧性を含蓄しますが、集合知から得られた潜在的な特徴を発掘する意図として、Doc2Vecによる分散表現を特徴量に加味する試みがあっても良いでしょう。
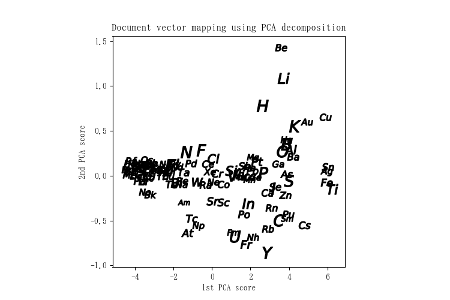
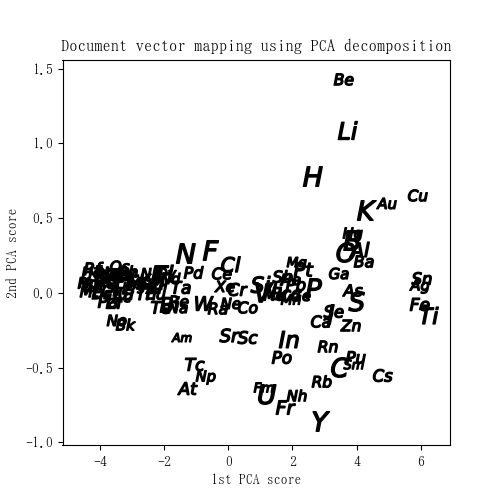
元素記事の分散表現をもとにした元素マップ
最後にDoc2Vecの分散表現で得られた数値ベクトルを可視化して元素マップを作成します。処理としては、200次元のベクトルをPCAによって次元圧縮し、第一、第二主成分を散布図にする流れで、下図がその結果となります。元素の規則性に着目して整理されたお馴染みの周期表と大分違った様子となりました。100以上の元素を同じグラフ上にプロットしたため、重なって見難い部分もありますが、工学的に重要そうな金属元素(Au, Ag, Cu, Fe, Tiなど)が右側に固まって位置したことは興味深いと思われます。この元素マップはあくまでWikipediaの記事データに基づいた結果であり、異なる記事データを用いれば新たな発見があるかもしれません。
まとめ
Doc2Vecの分散表現を通じてWikipediaの元素の記事を数値ベクトル化しました。得られた元素の数値ベクトルからPCA次元圧縮計算で元素マップ作成にも取り組みました。本ブログ記事のような手続きを経ることで、元素のテキスト情報も観測量などと同等な特徴量として利用できるでしょう。Materials Informatics に自然言語処理(NLP)が何かの形で役立てられれば幸いです。
[参考URL]
1) http://taka-say.hateblo.jp/entry/2016/05/20/221817
2) https://www.mizuho-ir.co.jp/publication/report/2018/mhir15_mi_01.html
3) http://www.nims.go.jp/MII-I/
4) https://radimrehurek.com/gensim/models/word2vec.html
5) https://radimrehurek.com/gensim/models/doc2vec.html
このページをシェアする: