データウェアハウスの新気鋭 Snowflakeのご紹介-性能検証レポート-

最近業界で話題のDWH「Snowflake」について、ご紹介していきたいと思います。
今回は、Snowflakeの機能と特徴についてご説明するとともに、簡単な性能検証を実施いたしました。
目次
Snowflakeとは
- 2012年に創業されたSnowflake社が提供するクラウド向けのDWH製品であり、実行環境をAWS, GCP, Azureから選択することができます。
- Snowflake社は、2018年にはアメリカでユニコーン企業入りを果たした。
- グローバルで大きな評価を受けており、導入クライアントは3,400社を超えている。
※Gartner社, FORRESTER社におけるデータウェアハウスサービス評価においてどちらもリーダー枠に位置
- 2019年には日本法人が設立され、今後の我が国における事業展開に注目が集まっている。
2012年創業から、現在に至り、グローバルで大きな評価を受けており、今後に期待がもてそうなDWHサービスです。
Snowflakeの特徴
特徴としては、以下の通りとなります。
●計算リソースとストレージを分離した柔軟なアーキテクチャーになっている。
→ 計算リソースだけを増強させる事がとても簡単にできます。 ※詳細は後述します。
●サーバーの利用料は起動している秒単位での課金制
→ 利用する時だけ起動させるなどとして、利用量のコスト節約が可能です。
●サーバー負荷状況に応じて、動的スケールアップする機能
→ サーバの立ち上がりが早く、負荷に応じてクラスターが起動するので処理のキューが溜まって処理が遅延する事がおこりにくいです。
●他組織へのデータ共有を簡単にできる機能を保有
→ Snowflakeアカウント経由で、即時にデータ共有する事が可能です。
サポートしているファイル形式
- ●CSV(TSV)
- ●JSON
- ●Avro
- ●ORC
- ●Parquet
など、様々なファイル形式のデータをロードできます。 詳しくはSnowflakeの公式ドキュメントを参照してください。
コストについて
コストは以下の3つの費用の合計で計算されます。
- ●ストレージ費用
- ●仮想ウェアハウス(計算リソース)費用
- ●データ転送費用
なお、最新の情報はSnowflakeの公式サイトからご確認ください。
ストレージ費用
格納しているデータの容量(TB)に応じて課金されます。 1TBあたりの金額はクラウド、リージョンごとに異なります。
仮想ウェアハウス(計算リソース)費用
仮想ウェアハウスの起動時間に応じて、クレジットという単位で課金されます。仮想ウェアハウスを削除しなくても、停止している間は課金されません。
1クレジットあたりの金額はクラウド、リージョンと、契約プランごとに異なります。
(参考)AWS東京リージョンにおけるクレジットあたりの料金 
(https://www.snowflake.com/pricing/ より引用)
また、仮想ウェアハウスのサイズによって、1時間あたりの消費クレジットが異なります。
(参考)仮想ウェアハウスのサイズごとの消費クレジット数 
(https://www.snowflake.com/pricing/pricing-guide/ より引用)
データ転送費用
クラウド間、またはリージョン間で転送するデータの容量(TB)に応じて課金されます。 1TBあたりの金額は転送元、転送先のクラウドとリージョンごとに異なります。
同時実行に対するリソースの最適化
前述の[Snowflakeの長所」でも述べた通り、リアルタイムに処理性能・同時実行性能を変更可能かつ自動的にスケールアウト・ダウンが可能なため、利用頻度やユーザー数に合わせてアーキテクチャーを拡張可能かつコスト最適化が可能です。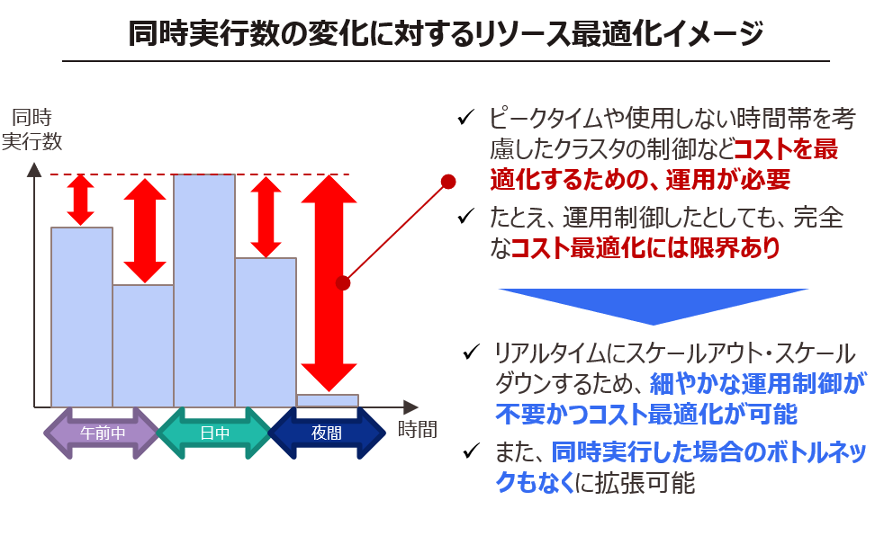
操作について
操作は主にWeb UIか、SnowSQL(CLIクライアント)から行います。 各種コネクタやドライバが用意されているため、Pythonなどのプログラミング言語からの接続も可能ですが、今回は割愛させていただきます。
Web UI
以下の3つのパネルに分かれています。
- ●左:データベース : データベース、スキーマ、テーブルなどのメタデータ
- ●右上:クエリエディタ:SQLにてクエリを記述 ※ANSI SQL対応
- ●右下:結果: クエリ結果
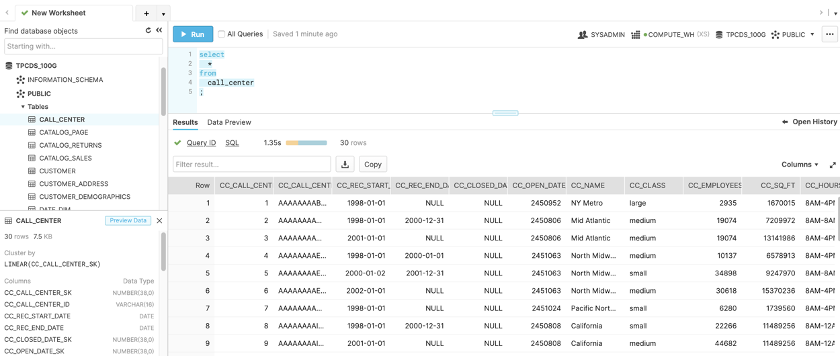
左の[データベース]パネルでテーブル名やカラム名などを確認しつつ、右上の[クエリエディタ]でSQLを書き、実行結果を右下の[結果]パネルで確認するような使い方が可能です。
シンプルな構成になっているため、何らかのDBを触ったことがある方であれば直感的に操作できると思います。
SnowSQL (CLI)
コマンドラインでクエリを実行することができます。
まず、インストールを行います。Homebrew導入済みのMacOSであれば以下のコマンドでインストールできます。
$ brew cask install snowflake-snowsql
次のコマンドを実行し、バージョンが返ってくればインストール完了です。
$ snowsql -v Version: 1.2.5
以下のコマンドを実行します。
アカウント名はそれぞれのアカウントに発行されているSnowflakeのURLの.snowflakecomputingの前の部分です。たとえば、https://ab12345.ap-northeast-1.aws.snowflakecomputing.comであれば、ab12345.ap-northeast-1.awsとなります。
ユーザ名はWeb UIにログインするときに入力しているものです。
$ snowflake -a <アカウント名> -u <ユーザ名> -w <仮想ウェアハウス名>
パスワードを求められるので、入力すると接続完了です。
* SnowSQL * v1.2.5 Type SQL statements or !help username#COMPUTE_WH@(no database).(no schema)>
実際にクエリを実行してみます。
username#COMPUTE_WH@(no database).(no schema)>use tpcds_1g; +----------------------------------+ | status | |----------------------------------| | Statement executed successfully. | +----------------------------------+ 1 Row(s) produced. Time Elapsed: 0.976s
username#COMPUTE_WH@TPCDS_1G.PUBLIC>select distinct ca_state from customer_address limit 10; +----------+ | CA_STATE | |----------| | AZ | | NM | | PA | | CO | | MO | | WA | | NULL | | TN | | AL | | AK | +----------+ 10 Row(s) produced. Time Elapsed: 0.984s
このように、PostgreSQLなどのRDBMSを触ったことがある方であれば違和感なく使用できるかと思います。
Snowflakeの性能検証
データのロード性能
TPC-DS※1で1TBのデータセットを生成して、同一リージョン内のS3からSnowflakeへのステージングを行い、実際にテーブルにロードしてみたところ、ロードにかかった時間は260分ほどでした。
※1 TPC-DS: TPCによって定義された、大規模データによる意思決定支援のためのデータベースの性能を測定するベンチマークデータセット(小売・流通業の疑似データ)
Snowflakeはデータをロードする際、自動的にgzip形式で圧縮する仕組みとなっています。今回は生のCSVデータをロードしたため、圧縮に時間がかかってしまったようです。一方で、圧縮により容量が1/3程度になるため、ストレージ費用を削減することができます。
検索性能
TPC-DSのデータセットに対してそれぞれ3種類のSQLを実行してみました。
- ●使用SQL: TPC-DSの53番、59番、94番のクエリ ※2 [クエリ内容]を参照
- ●仮想ウェアハウスのスペック: Medium
- ●データセットの容量: 100GB, 1TB
- ●それぞれのクエリを3回ずつ実行
(同一のクエリを複数回実行するため、リザルトキャッシュ機能はオフ)
※2 [クエリ内容]
- No 53:製造ID、四半期毎の、特定商品の売上合計と、製造ID毎の平均金額を算出するクエリ
- No 59:店舗、週、曜日ごとの、売上の前年度比を計算するクエリ
- No 94:ジョージア州の顧客がpri社のWebサイトから行った注文数、運送費の合計、利益の合計を計算するクエリ。ただし、その注文における商品がすべて同じ倉庫から出荷されているもの、1つでも商品が返品されているものは除く
実行結果
100GB
| クエリ | 1回目 | 2回目 | 3回目 |
| 53 | 18.119秒 | 0.920秒 | 0.796秒 |
| 59 | 4.495秒 | 3.448秒 | 3.750秒 |
| 94 | 3.561秒 | 0.844秒 | 0.791秒 |
1TB
| クエリ | 1回目 | 2回目 | 3回目 |
| 53 | 23.279秒 | 2.637秒 | 1.417秒 |
| 59 | 28.962秒 | 26.902秒 | 26.736秒 |
| 94 | 13.062秒 | 2.879秒 | 2.110秒 |
大きいデータセットへのクエリでも一瞬で結果が返ってくる、とは言えないものの、十分実用可能な速度が出ており、コストパフォーマンスは抜群です。
また、リザルトキャッシュ機能はオフにしていますが、2回目以降の実行はメモリ上に残ったデータが活用されるため、1回目より短い時間で実行できるようです。
スケール性能(マルチクラスター機能)
複数人でクエリを実行した場合、どうしても速度が遅くなってしまう問題があります。
しかし、Snowflakeでは、マルチクラスター機能によって実行待ちのクエリが多くなった場合に自動でスケールアウトさせることが可能です。
また、実行待ちのクエリがなくなった場合は様子を見て自動でスケールインするため、コスト対策もばっちりです。
※ マルチクラスター機能はEnterprise以上のプランでのみ使用可能です。
ここでは、さきほどのTPC-DSの1TBのデータセットと59番のクエリを用いて、まず以下の条件で同時接続の実験をしてみました。
- ●マルチクラスター機能: オフ
-
- -最小クラスター数: 1
- -最大クラスター数: 1
- ●クエリ実行回数: 100
-
- -1秒間隔で100回を連続実行
結果は以下のようになりました。
| 全体実行時間 | 最大実行時間 | 平均実行時間 |
| 47分18秒 | 45分39秒 | 24分42秒 |
各項目の意味は以下のとおりです。
- ●全体実行時間
-
- -1回目のクエリを開始してから最後のクエリが完了するまでの時間
- ●最大実行時間
-
- -一番時間がかかったクエリの実行時間
- ●平均実行時間
-
- -それぞれのクエリ1回あたりの平均実行時間
ここで、実行時の仮想ウェアハウスの様子をWebUIで確認してみると、下図のようにキューに入って実行待ちとなってしまっているクエリが非常に多くなっていることがわかります(青色の部分が実行中のクエリ、オレンジ色の部分が実行待ちのクエリです)。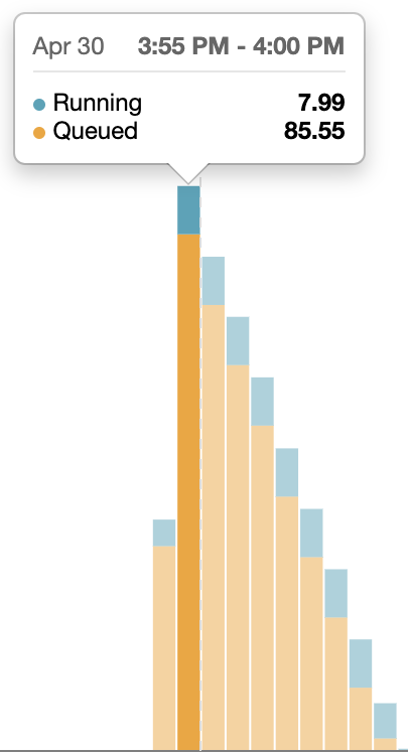
つまり、クエリの実行自体に時間がかかっているのではなく、計算リソースが足りず実行待ちとなっている時間がボトルネックになっているので、クラスター数を増やすことで改善が期待できます。
そこで、マルチクラスター機能をオンに変更して再実行してみます。さきほどの条件のうち、最大クラスター数を1から10に変更します。
すると、結果は以下のようになりました。
| 全体実行時間 | 最大実行時間 | 平均実行時間 |
| 7分28秒 | 6分0秒 | 4分48秒 |
なんと、全体実行時間を1/6以下にまで短縮することができました。
こちらについても実行時の仮想ウェアハウスの様子を確認してみると、実行待ちのクエリが非常に少なくなっていることがわかります。
マルチクラスター機能によりクラスター数が自動的に増えたので、処理できるクエリの数も増えたようです。キューの状況を確認して即座にスケールアウトされるので、無駄な待ち時間を減らすことができました。また、クエリ実行終了後は自動的にクラスター数が減っていく様子も確認できました。
まとめ
いかがでしたでしょうか。
Snowflakeは低コストから始めることができるので非常に導入しやすく、また、後々のデータ規模拡大にも対応できる柔軟なアーキテクチャを持っているようです。
他にも速度の出るDWH製品はありますが、Snowflakeも十分な性能が出ており、費用対効果を考えると優れた選択肢の1つになりそうです。
特に、ビッグデータの分析、機械学習などを常時回し続けるような大規模基盤ではなく、10名以下程度の中規模分析チームで導入する場合や、時間帯によって使用する計算リソースの量が大きく異なるような場合には、コスト面のメリットがとても大きいのではないでしょうか。
【セミナー開催のお知らせ】
6/23,30 に「データサイエンスとテクノロジーで「長生きする売れるゲーム」を作ろう!Supported by Microsoft vol2,3」を開催いたします
ゲーム業界に長年携わってきたデータサイエンティストによる、AI・機械学習を活用したゲーム業界のデータ分析を解説いたします。
6月23日(火)開催_vol.2 : 「ノンプログラミングで行う大規模プレイヤーログ超高速解析」
6月30日(火)開催_vol.3 :「GUI操作で作るAI簡単行動解析と「楽しいゲーム」作りへのアクション」
このページをシェアする: