dbt Coalesce 最速レポート2日目-セッション編-

DATUM STUDIOの兒玉です。dbt Coalesce 2日目のセッションに参加してきました!
同日のKeynote発表に関してはぜひこちらを参照ください。
目次
From BI to AI: Auto-generating semantic models
カタログツールとして知られるSelect Star社のセッションでは、セマンティックモデルの活用事例の一つとしてよく聞かれるようになった「自然言語によるデータ分析」について、「セマンティックモデルをどうやって備えるか?」について焦点を当てた講演でした。
講演では生成AIを「Dumbest smart kid(賢くて馬鹿な子供)」と表現しています。

知識を膨大に持っていても、「文脈」を読むことができないので、ただデータを生成AIに読ませただけでは正しい分析を得ることができません。
この「文脈」を与えるための仕組みがセマンティックモデルです。セマンティックモデルの特徴は以下のとおりです。

・モデルはエンティティ(例:顧客、商品、地域)とメトリクス(例:売上、支払い効率、リテンション)を明確に定義する。
・モデルにはビジネスルールや関係性も含まれるため、AIが「どの数値がどの文脈に属するか」を理解できる。
・一方で、生データや技術的なETL処理ロジックは混乱を招くため、除外すべき。
モデルの構築プロセスでは、以下のポイントを押さえることが重要だと考えています。
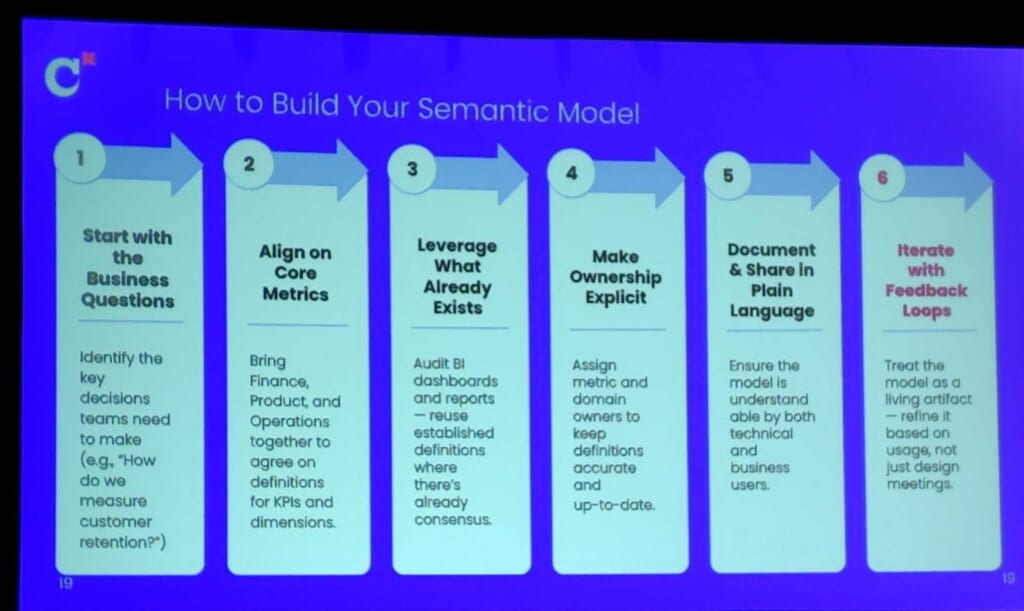
1.ビジネス上の問いから始める
チームが意思決定を行う上で必要な主要な質問を特定する。
例:「顧客維持率をどのように測定するのか?」
2.主要指標(コアメトリクス)を揃える
財務・プロダクト・オペレーションなどの関係部門を集め、KPIやディメンションの定義について合意を形成する。
3.既存の資産を活用する
既存のBIダッシュボードやレポートを監査し、既に合意が取れている定義を再利用する。
4.オーナーシップを明確にする
各メトリクスやドメインに責任者を割り当て、定義の正確性と最新性を維持する。
5.わかりやすい文章で書く
モデルを技術者だけでなくビジネスユーザーも理解できるよう、平易な言葉で文書化し、共有する。
6.継続的に改善する
モデルを「生きた成果物」として扱い、設計会議だけでなく実際の利用状況に基づいて洗練させていく。
そして、「3.既存の資産を活用する」点において、生成AIの利用が期待できるとSelect Star社は考えています。実際、Select Star社では、既存のBIダッシュボードやdbtモデルを解析し、そこに埋め込まれたビジネスロジックをリバースエンジニアリングすることで、セマンティックモデルを生成する機能を持っています。
プロセスの流れ:
1.既存のダッシュボードを分析
2.各指標の計算式・依存関係を抽出
3.エンティティ、メトリクス、関係性を整理
4.モデルファイルとして自動生成(例:YAMLなど)
5.Snowflakeやdbt、 Looker などのツールへ公開可能
セッション中のデモがありましたが、BIで利用されている指標をツールが自動で分析し、数分でセマンティックモデルを構築していました。
AI-ready in record time: How SWBC modernized its data stack with dbt
アメリカで金融商品・保険などのサービスを提供しているSWBC社のセッションです。同社のデータ活用のための取り組みに関する事例紹介でした。
SWBC社は、長年にわたり複雑なデータ環境を抱えていました。社内には多数のSQL Server環境と無数のExcelシートが点在し、部門ごとに異なる定義でデータが管理され、信頼できる唯一の情報源と呼べるものがない状態でした。
この状況を改善するため、SWBC社はデータをSnowflakeに集約し、dbtを活用してモデリング・テスト・ドキュメンテーションを統一管理する取り組みを開始しました。基盤の構成において特徴的だったのは、「Omni」です。
OmniはセルフサービスBIツールの一つです。
・Excelで作られた関数を自動でSQLに変換できる
・既存のBIダッシュボードを接続して再利用できる
これらのユニークな機能によって、SWBC社ではこれまでExcel職人が実現してきたデータ活用の世界をうまくBIへ接続・統合しながら、データ基盤の拡大を進められているとのことでした。
感想
パートナーセッションを除けばdbt Coaleseはまだ初日という位置づけですが、全体的な感想を正直に述べると、「昨年参加した時ほど目新しいセッションがなかった」という印象です。
これは講演内容に不満があったわけでは全くなく、むしろ「国内事例で聞くものとそこまで大きくは変わらない」という感覚です。昨年はアメリカの方が様々な面でデータ利活用は進んでいるのだと感じましたが、この一年で日本企業のデータエンジニアリング・データ活用は大きく進化したということなのかもしれません。
各セッションの感想としては、特にSelect Star社が提供する仕組みは興味深いです。確かにセマンティックモデルは、ほんの一部の指標だけが定義されていてもビジネスユーザーには使ってもらいにくく、あらかじめある程度のカバレッジを確保してから公開する必要があります。BIで定義されている指標をベースにして機械的にセマンティックモデルを作ってしまうというアプローチ自体はあると嬉しいはずです。
このページをシェアする: