DATA CLOUD SUMMIT 2024 最終日+まとめレポート

帰国後の投稿になってしまい申し訳ないです。DATUM STUDIOの稲岡です。
この記事では主に最終日のセッションやイベントを記載します。
セッション
What’s New: Streamlit in Snowflake
2022年のSUMMITでStreamlit In Snowflake(SIS)の構成が発表され、2年が経過し現在では多くのユーザーに使用されています。

またSISはワークフローのモニタリングやRAGアプリケーション、BIツールとして数多くの用途に使用されており、今回もいくつか以下のアップデートがありました。
2回目以降のアプリの起動時、初期画面のロード時間が短縮されました。
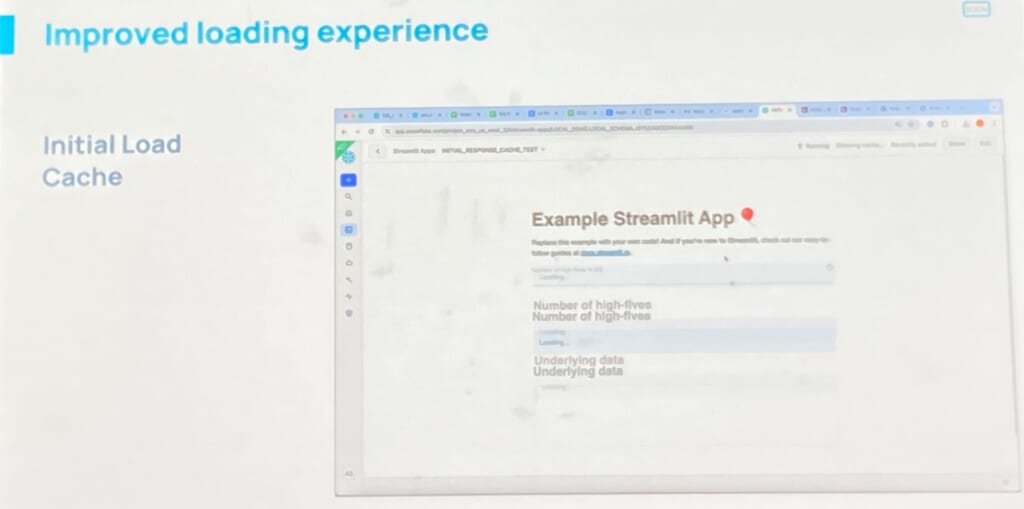
また、行アクセスポリシーも有効になるようです。

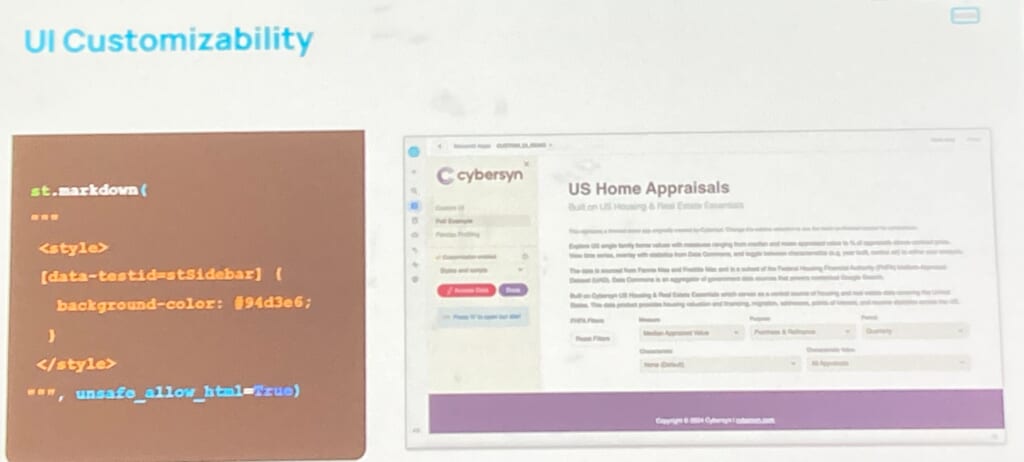
よりStreamlitをカスタマイズできるように、CSSの記述も可能になるようです。
最近、セキュリティや個人情報保護の関連で話題にあがることの多い差分プライバシーに関するセッションでした。
差分プライバシーの主な機能については以下のような説明がありました。
1つ目は、センシティブなデータについてノイズを付与し、個別の値の特定などの攻撃から守ること。
2つ目は、Privacy Budget、つまりセンシティブな情報を含むクエリを実行できる上限を定め、複数のクエリを用いた攻撃を防ぐことができるというものです。

その上、Snowflakeで提供する機能についても紹介されました。
すでにGAとなっているData Clean Roomにおける差分プライバシーのほかに、近日パブリックプレビューとなる差分プライバシーポリシーが紹介されました。差分プライバシーでは、従来の行アクセスポリシーのようなポリシー文をテーブル・カラムに付与することで、SQLベースのクエリにおいても結果にノイズを付与したり、集計済み結果のみだけ取得できるように制御できるというものです。
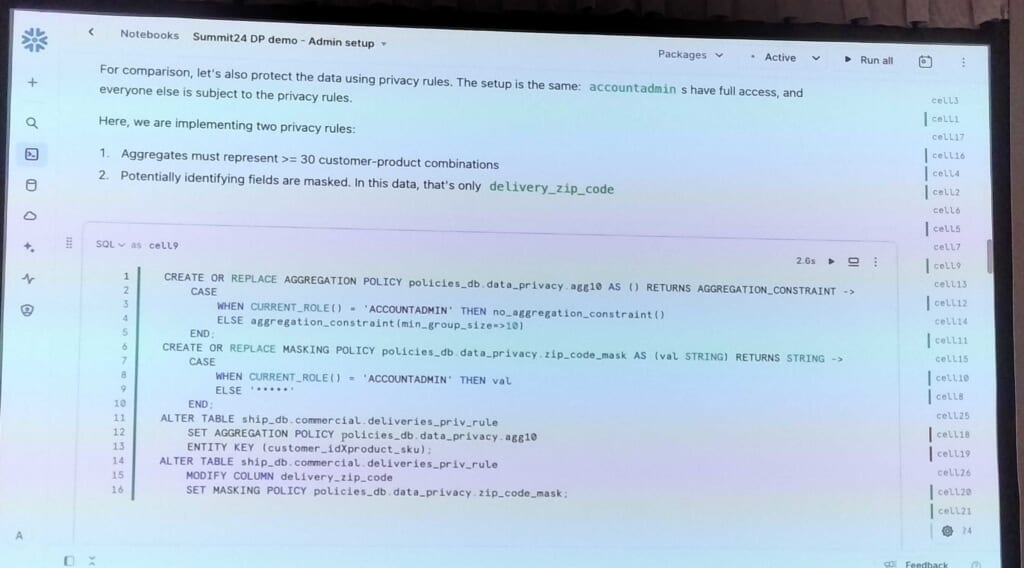
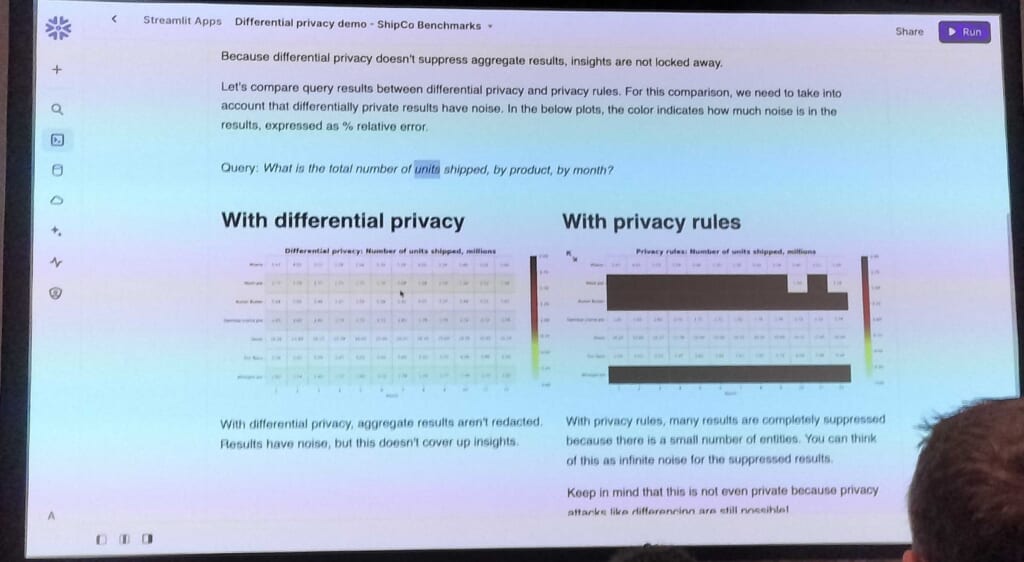
Notebookを用いてデモが行われ、ある閾値を用いてそれ以上の値は表示しないというルールベースで行うセキュリティよりも、差分プライバシーが有用であることも紹介されました。
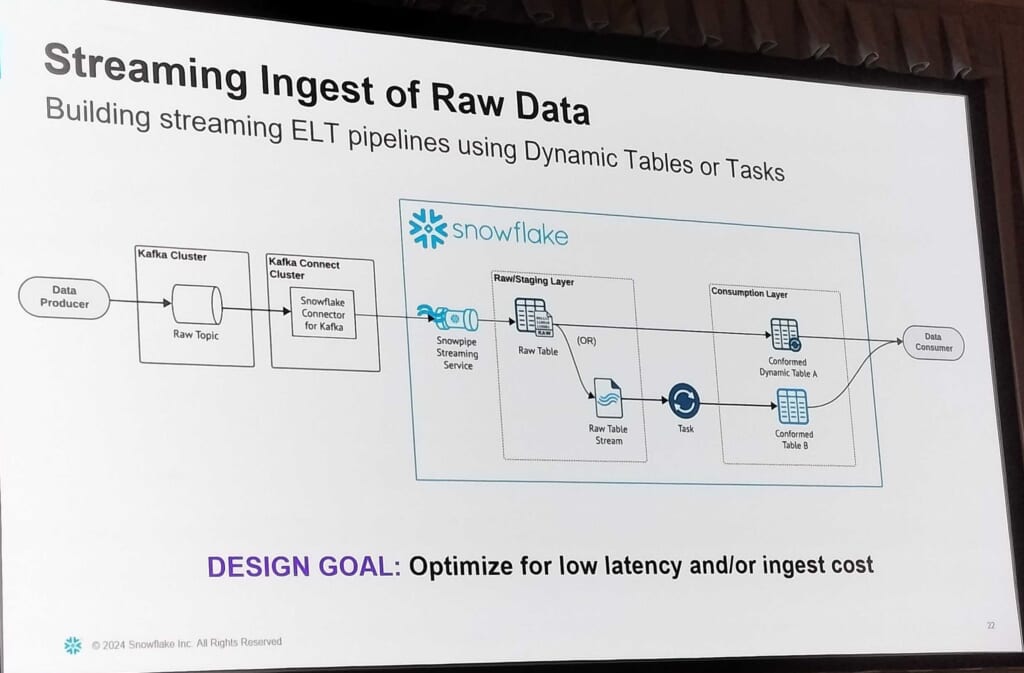
Snowflake Connector for Kafka: Configuration, Optimization, Monitoring and Error Handling, DE308
まずKafkaの紹介やユースケースが紹介され、その後、Snowpipe/Snowpipe Streamingを用いる際の比較、Kafkaの各パラメータのチューニング方法などが紹介されました。
またKafkaを用いるようなリアルタイム性を求める処理ではデータインジェスト後、DynamicテーブルやStreamを用いたtask処理でニアリアルタイムなETLがSnowflake内の機能で実現できることも紹介されました。
最後に新機能が2つ紹介されました。
1つ目は、Pull Conector for Kafka(現在Private Previw)でKafka Connectorを使用せず、直接BrokerにつなげることでConnecor部分のインフラのメンテナンスが不要になるという利点があります。

2つ目は、Snowpipe Streaming Rowset API(現在開発中)です。行単位でSnowflakeにデータをリアルタイムで投入するには、現在Snowpipe Streaming + Kafkaの構成が必要ですが、こちらの機能を用いることでKafkaのインフラ構築の手間が不要で、APIから容易に実行できるようになりそうです。

イベント
ブースツアー
複数のパートナー企業さんがブースを出展されていました。
日本人のスタッフさんがいる一部のブースを除いてほとんどのブースは英語でのやりとりが必要となりますが、データに関する製品ということで訪れたブースで扱う製品が何のツールかというところは、概ね理解できたと感じています。
またSnowflake Japan(KTさん)の主催で日本人を集めてのブースツアーも行われており、そちらにも参加しました。まだ訪れていないブースの概略をKTさんや他の日本企業参加された皆さんからも情報をいただき、非常にありがたいツアーでした。

ブースのプロダクト・コンテンツの所感としては、以下が多かった印象です。
- ・ノーコードのETLツール
- ・データカタログ
- ・セキュリティ関連のツール
また、SUMMITのKeynoteで多くとり取り上げられていた、Iceberg関連のツールやSPCS上での動き、マーケットプレイスから取得可能なMLや自然言語でのやり取りが可能なツールも多くありました。

(写真は朝の静けさのあるブースです。昼間はとても混雑していました。)
Japan Wrapup
本SUMMITの締めに、Japan Wrapupが開催されました。まず最初にPlatform Keynoteについて簡単な振り返りが行われました。多くのアナウンスが簡潔にまとめられており、非常にわかりやすくなっていました。

会の途中では、サプライズでSridhar氏・Benoit氏・Thierry氏に東條氏を加えたディスカッションが行われました。最後には参加者からのQAもありインタラクティブな場面となりました。

休憩を挟んで、弊社役員の菱沼を含むData Superheroによるディスカッションが行われ、様々なトピックについて語られました。

最後は参加者でグループを作成し、「今回のSUMMITの内容をどのようにビジネスにつなげていくか」についてディスカッションを行い、各チームが意見を出し合う形で進んでいきました。Wrapupを通じ、非常に賑やかな雰囲気で進行していきました。
Data Superheroes関連
このコーナーは稲岡に代わって、梶谷がお送りします。
この日、Data Superheroesはある目的のために招集されていました。
実は 6月5日夕方のSnowBash Partyでは、Data Superheroesのためにスペシャルなイベントが用意されていました。Snowflakeのエグゼクティブにお会いできるという非常に貴重なイベントで、CMOのDenise氏とSenior VP of MarketingのElise氏とお話することができました。しかし、Co-founderのBenoit氏とThierry氏、CEOのSridhar氏とは会うことができず…。会場が混雑しすぎて、移動できなかったのだそうです。そこでこの日に、あらためてお三方に会える機会をいただいた、というわけでした。(コミュニティマネージャーさんに感謝!)


全体写真だけでなく、日本の Data Superheroesとも個別の撮影をお願いしたいところでしたが、どうやら完全に時間切れ。1分1秒たりとも止まってはおられぬといった様子で、撮影後はすぐにどこかへ移動されてしまいました。異次元の忙しさですね…。
まとめ
今回のテーマがbuild the future together with AI and Appsであったこともあり、特にSnowflake Cortex(LLM)に関する発表が多かった印象です。RAGアプリケーションがStreamlitも用いて容易に構築できるようになったのは驚きでした。またデータガバナンスやオブザーバビリティに関するSnowflake Horizonや、Snowflake Trailの機能拡充の発表もありました。 元々外部のツールを入れる必要があった部分も、Snowflake内部で完結できることができ非常に便利ですね。データインジェストからETL、データカタログ、ガバナンス、可視化、AIアプリケーションまでSnowflakeで完結できるという世界が本当に達成されつつあります!
最後に、来年のSUMMITもサンフランシスコの同じ会場で6月2日~6月5日の日程で開催されることが発表されました。寒暖差が大きく、乾燥から喉の不調になった方も多い印象ですので、来年行かれる方はしかるべき対策をして臨みましょう!
このページをシェアする: