DATA CLOUD SUMMIT 2024 最速レポート(2日目①)

こんにちは!DATUM STUDIOの稲岡です!
Platform Keynoteのあと、多くのwhat’s new(新機能の解説)のセッションがありました。この記事ではその様子をお送りします!
目次
セキュリティ・監視
What’s New: Observability in Snowflake
今回Snowflake TrailというObservabilityに関する機能が発表されました。
ここでのObservabilityは、パイプライン・アプリ・データの3つの部分の品質や可用性を確認・担保することを指しています。

既存のログやEvent table(現在プライベートプレビュー)を通じて、Snowsight上でtaskの構造やエラー時の発生箇所、ダイナミックテーブルの更新状況、アプリのCPU使用率などを確認できるようです。
Snowsightで確認するため、外部のエージェントを入れる必要もデータを外に持ち出すこともなく、セキュリティ面でも安心な機能です。

今後、Snowflake Trailには使い慣れている監視ツールを連携させることもできる様子です。

What’s New: Snowflake Horizon for Data Teams
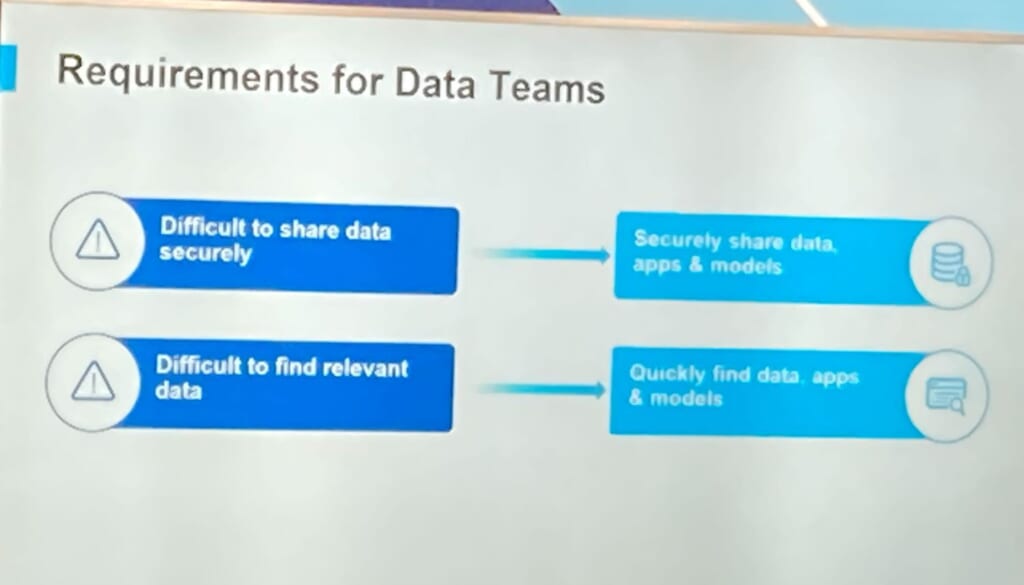
まず冒頭で、データチームに求められる要件のうち代表的な課題が2点挙げられました。
①データを共有する際のセキュリティ要件
②関連データを発見する困難さ
上記の課題についてもSnowflakeであれば解決することができます。
KeynoteでもあったようにHorizonは下記5つの観点で構成されています。
①COMPLIANCE
②SECURITY
③PRIVACY
④ACCESS
⑤INTEROPERABILITY
このうち、PRIVACY・ACCESS・INTEROPERABILITYの3つの機能を使用することで、「データを共有する際のセキュリティ要件」および「関連データを発見する困難さ」の課題を解消することができます。

PRIVACYに関しては代表的な3つの技術が紹介されました。
1つ目は、Entity-level Privacy with Aggregation Policies です。これは個々のデータエンティティ(例: 個人や特定の顧客情報など)のプライバシーを保護しつつ、データの集計と分析を行うことができます。
2つ目は、集計関数のみを許可し、さらにセンシティブなデータに対してノイズを加えることで個人の特定を回避する Differential Private Privacy について説明がありました。
最後にSynthetic Data Generation についても触れられており、対象データと似たような分布や相関、結合キーのダミーデータを作成します。
これらのプライバシー強化のための技術をコラボレーションやアプリ・マーケットプレイスに適応することで、よりセキュアな設計を行うことができます。

ACCESSに関しては、Organizational Listing・Internal Marketplace・Universal Serch・Share AI models に関する機能の説明が行われました。これらの登場により、データの検索性が大きく向上すると思われます。
最後のINTEROPERABILITYについては、キーノートでも触れられていましたがSnowflake HorizonとPolaris Catalogの統合により、どのエンジンで作成されたIceberg REST APIであっても、SnowflakeでIcebergテーブルを発見し共有することができるようになりました。

これらの要素がデータチームの業務を楽にしてくれることを期待しています。
ML・AI
What’s New: Snowflake ML
Snowpark MLのAPIが昨年末にGAとなったほか、5月にはSnowflake Model RegistoryがGAとなりました。学習済みモデルのSnowflakeのスキーマオブジェクトとして保存・バージョン管理ができるようになっており、進化を続けています。
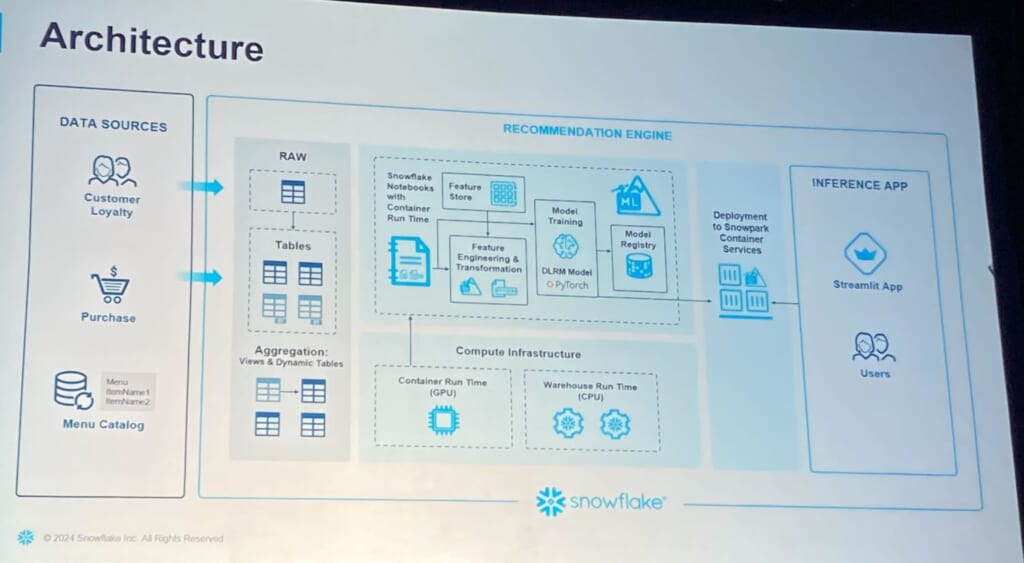
SUMMITにおいてNotebookがパブリックプレビューとなったことから、NotebookでContaier 上のリソース(GPU)を用いて深層学習を実行し、モデルレジストリに記録、Streamlitで作成した画面から推論結果やMLモデルの評価指標(AUCなど)も確認するというデモが紹介されました。
What’s New: Building AI Chat Experiences with RAG in Snowflake Cortex
この領域は最近でもCortext のLLM関数がGAになったり、ベクトル型やベクトル間の類似度を図る関数などがPreviewになったりと機能追加が目覚ましい領域です。ステージ上のPDFを読み込み、文字をチャンク化しベクトル化します。つまりRAGを構成した上で、Streamlitで作成したアプリからプロンプトを渡し、検索・回答を得るというチュートリアルも公開されていました。
セッションではまずCortexの3つの領域①モデル②chat③studioが紹介されました。
①LLMモデルについてはパートナー関係である各社のモデルの他、Snowflakeが開発したArcticも利用可能で、ある評価指標においては他のモデルよりも優れているとの結果も紹介されました。
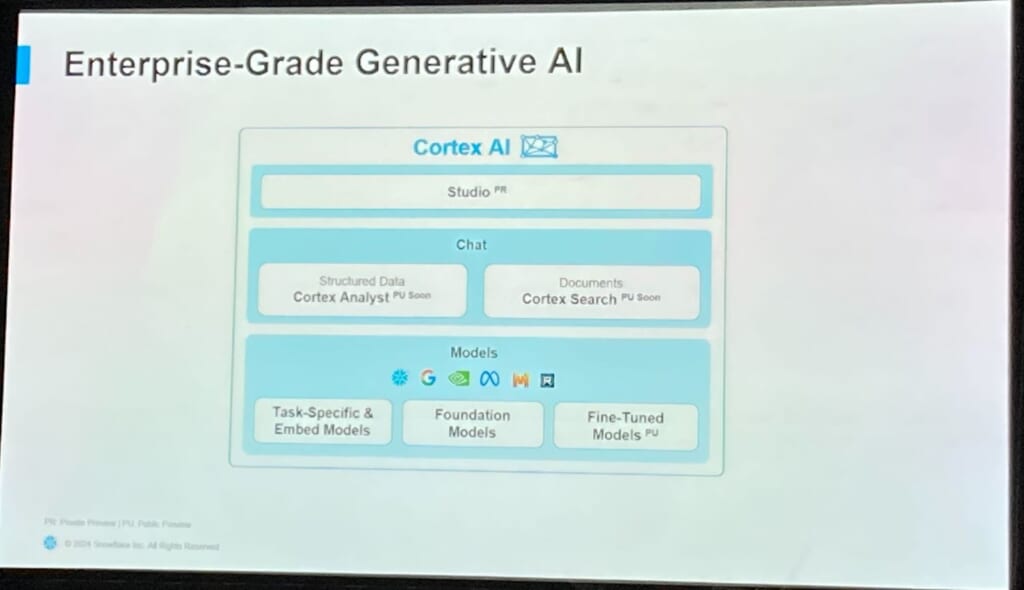
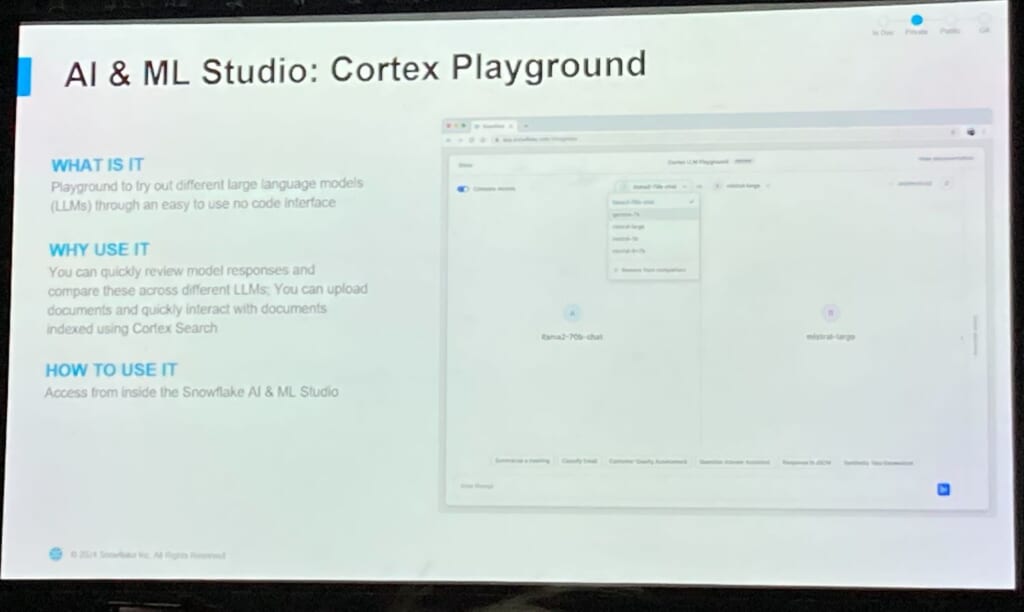
②chatの部分については、近日パブリックプレビューになるCortex Search(非構造化データ)とCortex Analyst(構造化データ)が紹介されました。特にCortex SeachについてはUIからの簡単なGUI操作のみでステージ上に配置したPDFファイルを読み込み、Snowflake上にベクトル型データを保存できることが示され、その後Cortex Play GroudというUIから質問を投げると、回答の他に元のPDF資料の該当部分までも抜き出すことができます。これらの機能により容易に実際の応答を見ながら、複数のLLMモデルの性能比較ができそうです。
また既存のモデルに新たなデータを学習させ、専門的な領域への応答を強化するFine Tuningについても、一部のLLMモデルに適用可能な機能がPublic Previewとなったことが紹介されました。
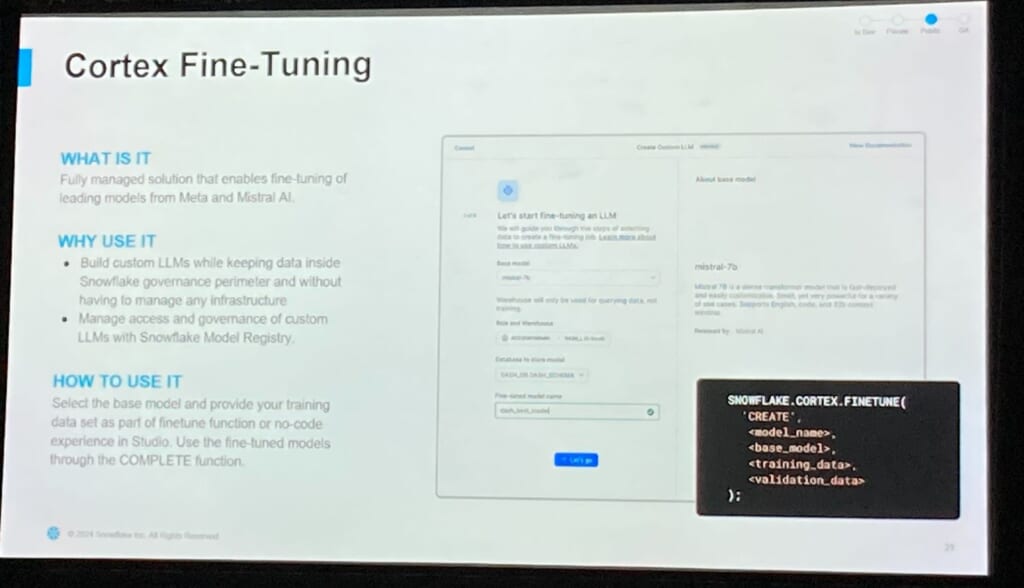
ドキュメント:https://docs.snowflake.com/en/user-guide/snowflake-cortex/cortex-finetuning
このページをシェアする: