Snowflakeを活用した自動クラスタリングの使い所と効果検証について

目次
はじめに
どうもこんにちは、DATUM STUDIOの濱口です。
みなさんは自動クラスタリングという手法を用いたことがありますか。
自動クラスタリングはテーブルへのクエリ処理時間を短縮する方法の1つとして存在しますが、どの場面で使え、どのように設定し、どう評価すれば良いのか、と悩む部分が多くあると思います。そこで、この記事では下記3点を備忘録として残します。クエリの処理時間を短縮する手段として自動クラスタリングを選択される場合に参考となれば幸いです。
まとめ
1.TableScanの処理時間が全体のほとんどを占めている(目安として90%を超えている場合)
2.マイクロパーティションの量がとても多い(目安として10,000を超えている場合)
3.WHERE句やJOIN句でフィルターを掛けている
(前談) マイクロパーティションとは
本編前に興味のある方は読んでいただけると幸いです。
自分理解ですが、マイクロパーティションのイメージは大きなデータを大量のCSVで小分けにして管理するイメージです。
micro-partitions ## 全体 50KB x 1M ≒ 5 GB
├── micro-partition-0000001.csv ## 50KB
├── micro-partition-0000002.csv ## 50KB
├── micro-partition-0000003.csv ## 50KB
├── micro-partition-0000004.csv ## 50KB
・・・
└── micro-partition-1000000.csv ## 50KB
大きなデータを小分けにして保管する利点はいらないデータをスキップ(≒プルーニング)できることです。(詳細な内容は
公式Docsをご確認いただけると幸いです。)
例えば、日付カラムに2020-01-01
から2023-01-01までムラなくレコードがあると仮定し、WHERE句で2020-03-01から2020-06-01までのレコードをSELECTすると分割なしと分割あり(マイクロパーティションされている)で処理が大きく異なります。
ケース1:分割なしの場合
ケース2:分割あり(マイクロパーティションされている)の場合
Snowflakeでは下記のメタデータを保存しているのでデータが綺麗に並んでいれば素早く位置を特定できます(参考)
自動クラスタリングを使う場面について
自動クラスタリングは下記の表に示す条件を満たす場合、クエリの処理速度改善に繋がると考えています。
条件
条件の理由
TableScanの処理時間が全体のほとんどを占めている(90%を超えているのが理想)
自動クラスタリングはTableScanの処理時間を改善することが目的のため
(プルーニングされていないことが原因ではない場合、自動クラスタリングでは解決できない。例えば、JOINの処理時間やSELECTの結果を表示するIOに時間がかかっている場合等)
マイクロパーティションの量がとても多い(10,000を超えているのが理想)
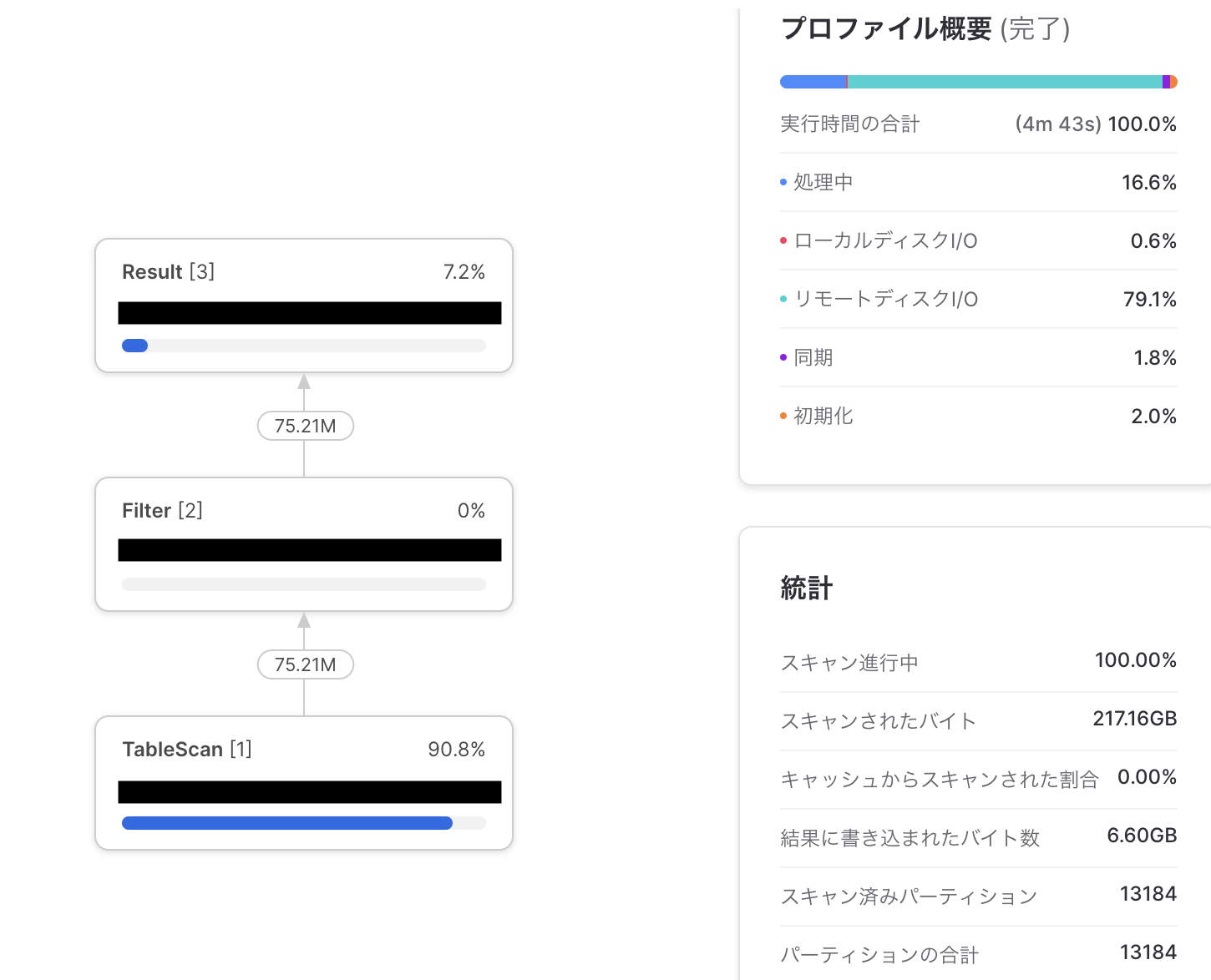
図1に載せているクエリプロファイルが理想に近い例です。マイクロパーティションの量が少ないと、自動クラスタリングを実施しても処理時間の変化量が小さく自動クラスタリングのコストに見合わないため
(マイクロパーティションの量は感覚ですが、10,000を超えてくるテーブルでは効果を実感しやすいと思います。)
WHERE句やJOIN句でフィルターを掛けている
自動クラスタリングはフィルター(絞り込み)の条件が一致する部分のみスキャンしてクエリの処理時間を短縮するため
(フィルターの条件がない場合、テーブル全体をスキャンするため効果はないと考えられます。)
図1:マイクロパーティションの量がとても多い例
自動クラスタリングで設定するクラスタリングキーについて
基本的には
Snowflakeのクラスタリングキー検討方針を参考に下記2つの条件に当てはまるクエリを探します。
公式内にあるクラスタリングキーの選定で十分な数の個別の値や十分に少数の個別の値と記述がありますが、私はマイクロパーティションが10,000あたり、1/50(200) ~
1/10(1,000)を目安に分けられそうなカラムを選定していました。
注意点としては、WHERE句やJOIN句でフィルターを掛けているカラムをクラスタリングキーに選択しましょう。前章にある通りフィルターの条件に関係のないカラムを自動クラスタリングに設定してもクエリは早くなりません。。(1敗)
自動クラスタリングの効果検証について
ここでは自動クラスタリングの効果検証をするために必要な評価方法や手順について書き残します。
注意点として検証するテーブルにおける元々のマイクロパーティション数が多すぎる場合、CREATE TRANSIENT
TABLE等を利用して小さめのテーブルを作成し、事前に自動クラスタリングのコストを大まかに見積もった方が良いと思います。。いきなりテーブル全体に適用すると請求されるクレジットをドキドキしながらリソースモニターと睨めっこすることになるため(1敗)
評価方法
マイクロパーティションにおけるプルーニング割合とクエリの処理時間を評価方法し、自動クラスタリング前後で比較を実施します。
マイクロパーティションにおけるプルーニング割合の算出方法
プルーニング割合は下記の式で算出し、値の範囲は 0.0 <= [プルーニング割合]
<=100であり100に近づくほど効率のよいプルーニングができています。
[プルーニング割合](%) = (1.0 – [スキャンされたマイクロパーティション数] / [合計マイクロパーティション数]) x 100 (%)
スキャンされたマイクロパーティション数(Partitions scanned), 合計マイクロパーティション数(Partitions
total)はアクティビティ→クエリ履歴→任意のクエリ選択→クエリプロファイルから確認できます。(旧UIの場合、SnowflakeのクエリID→Profileから確認できます。)
手順
手順3.で対象クエリを複数回実行するのは、1回のみだと自動クラスタリングがまだ途中である場合、複数回実行する方が正確な時間を測れると思います。(1敗)
クラスタリングキー設定クエリ[1]
USE ROLE SYSADMIN; -- 適切なロールがある場合はそちらを選択してください
ALTER TABLE .<スキーマ名>.<テーブル名> CLUSTER BY (“カラム1”);
-- cluster_byカラムに LINEAR(“カラム1”) が存在すればOK
SHOW TABLE LIKE <テーブル名> IN .<スキーマ名>;
検証結果・考察
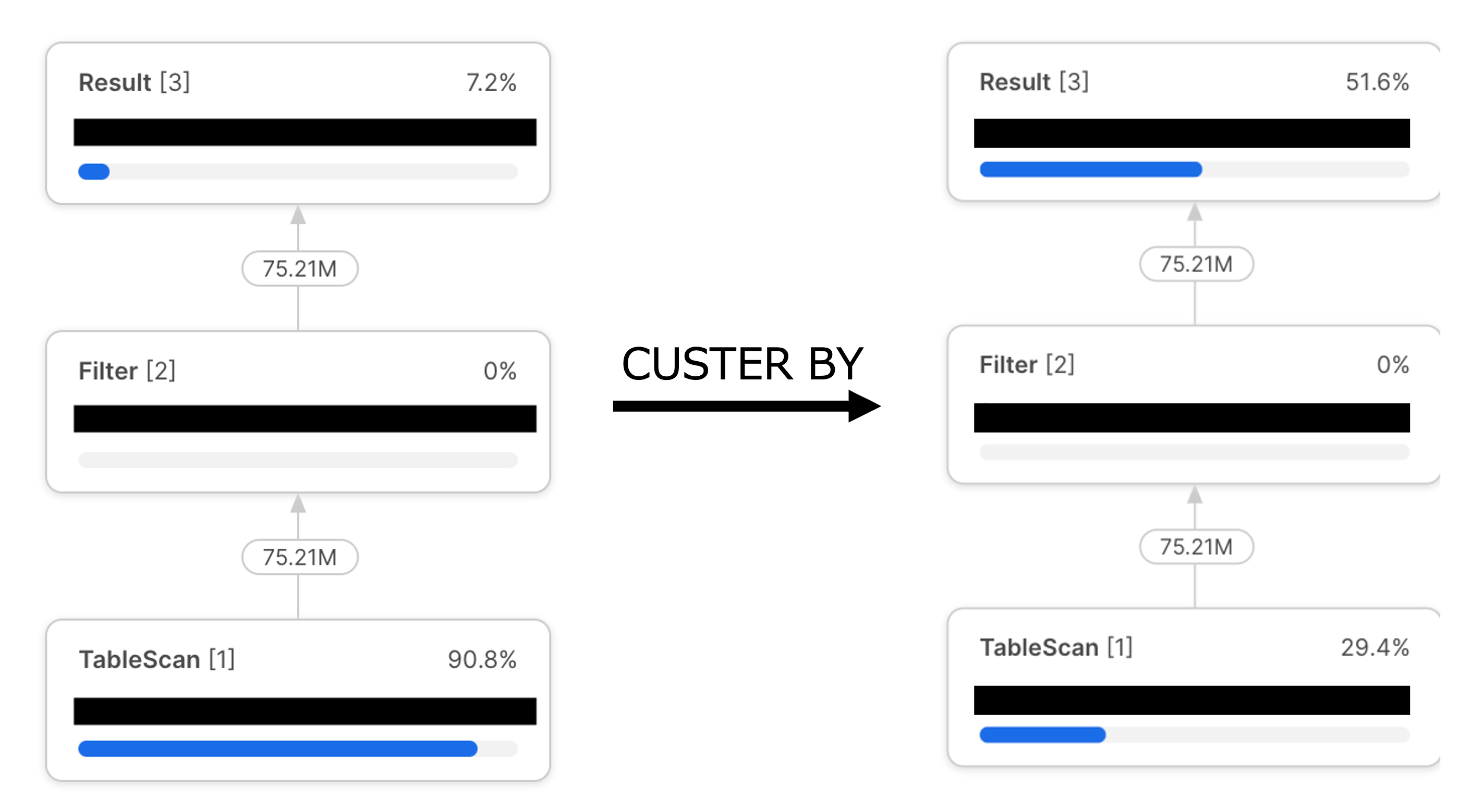
ここでは、ダミーの結果で埋めますが、(A)と(B)の変化量を表1にしてまとめると効果があったのか確認しやすいと考えてます。また、全体の処理時間に関する変化も図2のようにメモしておくと比較することができます。また、この結果を例に考察すると、自動クラスタリングによりTableScanは改善できたと考えられます。ですが、Resultの表示に時間がかかっているため、自動クラスタリングとは別の要因が絡んでいると考えられます。
表1:(A)と(B)の変化量
プルーニング割合
クエリの処理時間
クラスタリングキー設定前 (A)
0.0 (%)
{1.0-(10,000/10,000)}x100100 (秒)
クラスタリングキー設定後 (B)
70.0 (%)
{1.0-(3,000/10,000)}x10030 (秒)
各評価の変化量 |(A) – (B)|
70.0 (%) 向上
70 (秒) 短縮
図2:全体の処理時間に関する変化
おわりに
最後まで見ていただきありがとうございます。 クエリの処理時間を短縮しようと考えた際に自動クラスタリングという選択肢が出てきたらこちらの記事を参考にしていただけるととても嬉しいです。また、本文中に出てきた3つの敗北ポイントですが、これらを事前に見ておくことで無駄なクレジットを消費せずに自動クラスタリングの検証・導入ができると思います。
参考文献
このページをシェアする: