Cloud Run の最新アップデート-SSH踏み台とGPUの実用性を考察

目次

こんにちは、ちゅらデータのアラフィフエンジニア、倉富です。
現地に到着するまでが大変でした。日本時間の朝11時半に家を出て、ラスベガスのホテルに着いたのが現地時間の22時。24時間以上の移動となりました。
国内線は管制トラブルの影響で欠航やら遅延が発生し、そのあと乗り継ぎ便も現地で遅延。機内で仮眠は取ったものの、アラフィフの身体にはそれなりに堪えます。 Google Cloud Next 初日の朝のセッションでは、半分意識が飛んでいました。
そんな状態で参加した「What’s new in Cloud Run」のロードマップでは、10件以上の発表がありました。まずは全体像を簡単にご紹介します。
・Google AI Studio からのフルスタックアプリデプロイ(GA): AI Studio からCloud Run に直接デプロイできるように。プロトタイプをそのまま本番に出せる導線。
・Cloud Run MCPサーバー(GA): AIエージェントが Cloud Run を操作するためのMCPサーバー。エージェントに「デプロイしといて」と言える世界。
・Billing Caps(Coming Soon): 月額の利用上限を設定できるようになる。請求が跳ねる恐怖から救われる。
・Gemini Enterprise Agent Platform連携(Private Preview): Cloud Run リソースをエージェントとしてフラグすると、 Agent Platform に自動登録される。
・Cloud Run Instances(Private Preview): service/job/worker poolとは別の新プリミティブ。常駐型のバックグラウンドエージェント向け。
Cloud Run Sandboxes(Coming Soon): エフェメラルなマイクロVMでコードを使い捨て実行。AIエージェントが生成したコードを安全に走らせる用途。
・Service Bindings(Private Preview): サービス間通信でJWTを自動注入してくれる。Cloud Run同士の内部呼び出しが楽になる。
・Worker Pools(GA)とKramer:常時稼働型のWorker PoolsがGA。Kramerで、キューのバックログ件数みたいな外部メトリクスでオートスケールもできる。
・Custom Scaling Controls: インスタンス数の最小/最大を厳密に指定できるように。
詳しい説明は他のメンバーに任せるとして、ここから個人的に印象に残った2つのポイントについて書きます。SSHとGPU周りです。
Cloud Run Services へのSSHは踏み台サーバとして使えるか
Cloud Run Services へのSSHサポートがPreviewとして発表されました。コマンド一発でコンテナにアクセスできる機能です。

これまで Cloud Run のコンテナの内部を確認するには工夫が必要で、正直手間がかかっていました。それがネイティブにSSH接続できるようになります。さらに、裏側はIdentity-Aware Proxy(IAP)経由で、認可はIAMによって管理されます。つまり鍵の配布やローテーションは不要で、Google Cloud のアカウントそのものを認証情報として利用できます。デバッグのしやすさは大きく向上しそうです。
ここで気になったのが「踏み台サーバの代替として使えるのではないか」という点です。
これまで Google Cloud の環境で踏み台を構築する場合、GCE + IAP TCP forwardingという構成が一般的でした。Google Cloud のアカウントで認証でき、パブリックIPも不要で、Cloud Audit Logs に操作履歴も残るため、実用的な構成です。
一方で、コスト自体は踏み台用途であれば e2-micro 程度で十分とはいえ、「使いたいときに起動して、終わったら停止する」という運用が意外と手間がかかります。停止を忘れて課金が続いたり、起動し忘れて作業が止まったり、それを避けるために自動化スクリプトを書き始めるケースもあります。
Cloud Run Services で踏み台が構成できるとすれば、このあたりの手間はまるごと解消されます。scale-to-zeroなので必要なときだけ自動に起動し、使い終われば自動的に停止します。起動忘れや停止忘れもありません。コンテナなので侵害されたとしても次の起動時には状態がリセットされ、IAMによるメンバーごとの権限管理もそのまま活用できます。さらに、Direct VPC egress と組み合わせることで、VPC内の Cloud SQL や内部LBの配下のGCEまで経路を引ける可能性があります。psql、redis-cliといった踏み台に入れたいクライアントツールもコンテナイメージに含めておけばよいので、用途別の踏み台イメージを用意する運用もイメージしやすいです。
ただし、踏み台として成立させるうえで、個人的に最も気になっているのが、ポートフォワーディングです。実用的なユースケースでは、「手元のDBクライアントからSSHトンネル経由でCloud SQLに繋ぎたい」「ローカルのブラウザから内部アプリのUIを開きたい」といった、ポートフォワーディングを前提とするケースが多くなります。SSHでログインしてコマンドを実行するだけであれば、 Cloud Shell や Cloud Workstations でも代替可能です。
このSSH機能については、ポートフォワーディングが利用できるかどうかが現時点では明確ではありません。裏側がIAPであることを踏まえると、任意のTCPポートを通せる可能性はありますが、この点は標準機能として備わっていてほしいところです。
これが実現できれば、個人的にはかなり嬉しいです。GCE踏み台を常時起動しておかなくても、必要なときだけ Cloud Run Services をspin upして Cloud SQL にトンネルを張り、作業後は自動的に停止する。踏み台の理想形に近い運用になると感じています。Previewが一般公開された際は、まずポートフォワーディングが通るかを確認するところから検証したいです。
NVIDIA RTX Pro 6000 BlackwellとEphemeral Disk、起動時間は本当に改善されるのか
もうひとつ刺さったのはGPU周りです。NVIDIA RTX Pro 6000 Blackwellの正式サポートと、Ephemeral Disk(大容量のエフェメラルディスク)がアナウンスされました。あわせてJobsの遅延実行も発表されており、GPU関連のアップデートが多い回でした。
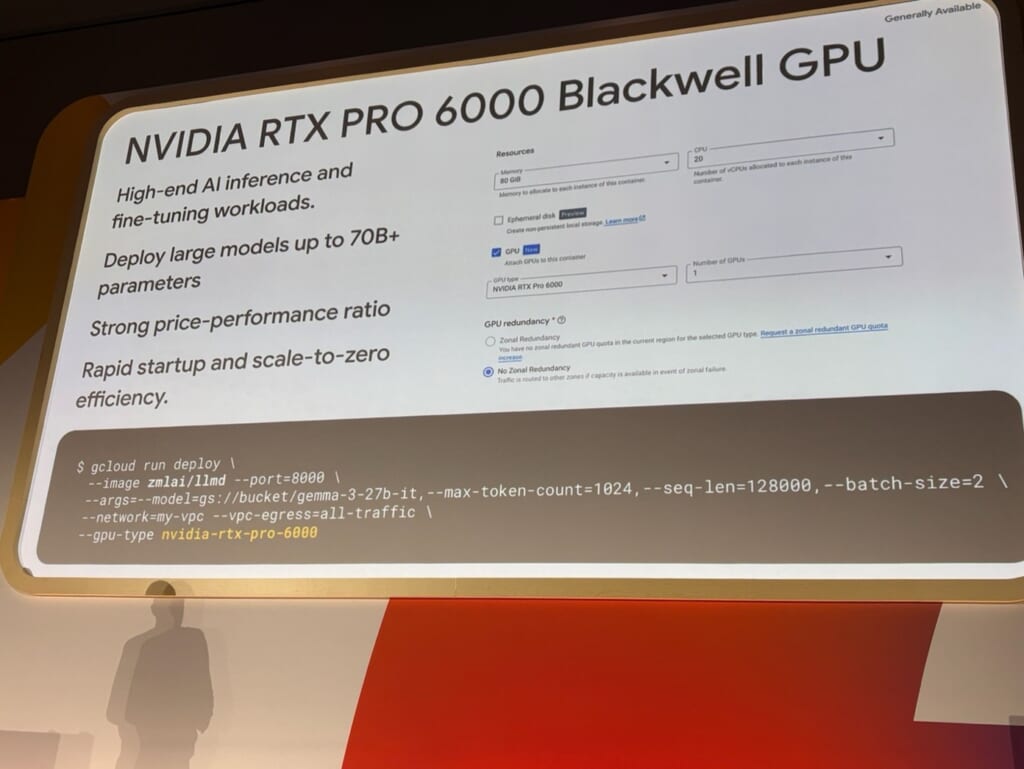
RTX Pro 6000 Blackwell自体は少し前から触れていましたが、モデルのロードで苦労しました。Cloud Run 上でモデルファイルをどうやって持ち込むかという点で、当時はGCSマウントかNFSマウントを利用していましたが、起動のたびにネットワーク経由でモデルを読み込む必要があり、起動時間が大きく伸びてしまっていました。数十GBクラスのモデルでは、起動してから推論できる状態になるまでに相応の待ち時間が発生します。
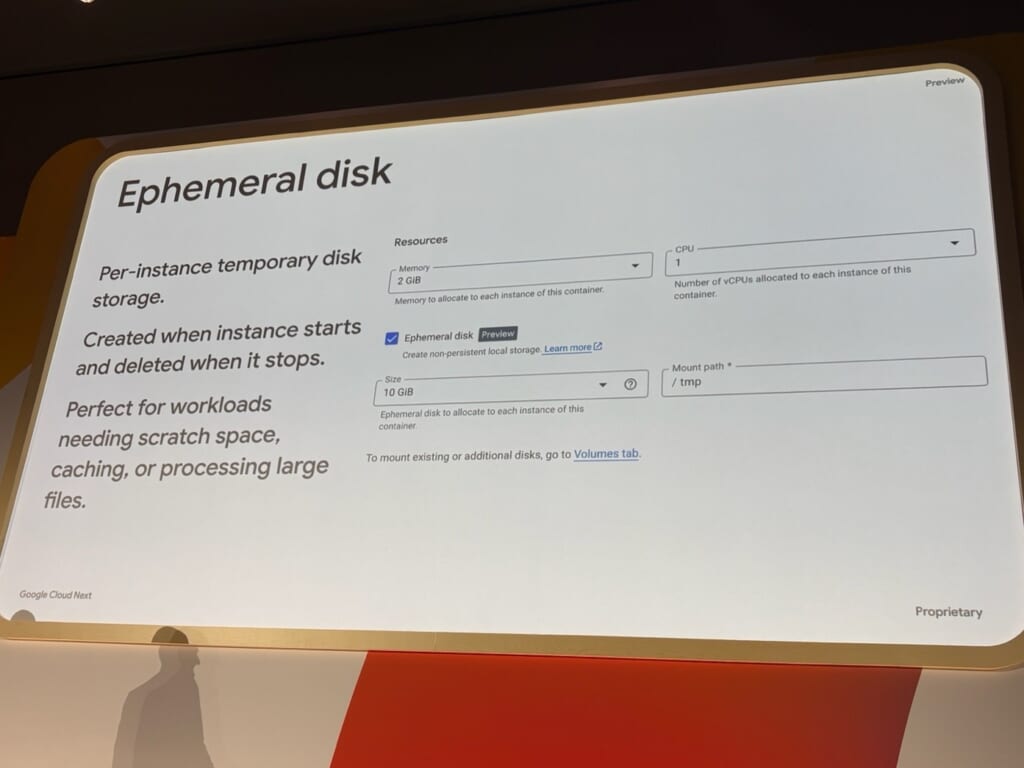
そこに今回Ephemeral Diskが追加されました。ギガバイト級の大容量ディスクをインスタンスに直接アタッチでき、「ローカルディスク」として利用できる範囲が広がります。少なくともファイルの読み書きはネットワーク越しではなくなります。
ここで気になるのが「起動5秒」という点です。公式ブログには「ドライバ込みで約5秒で起動」とありますが、これはGPUインスタンス自体が立ち上がる時間を指しているはずで、モデルファイルをEphemeral Diskに配置する工程まで含まれていないはずです。初回のモデル配置をどのように行うかは検討が必要で、コンテナイメージに含めるのか、起動後にダウンロードするのかといった選択になります。いずれにしても、コールドスタート時のロード時間は一定残ると考えられます。Anthropicの事例で「コールドスタート60秒以下」とされているため、その程度に収まると理想的です。
そして、もう一点気になるのが、 そもそもRTX Pro 6000 Blackwell、いつでも使えるんでしょうか?
公式ブログには「No reservations required」とあり、予約なしでオンデマンド利用が可能とされています。ただ現実的には、2026年4月時点で RTX Pro 6000 Blackwell が Cloud Run でオンデマンド提供されているのはus-central1とeurope-west4だけです。アジア圏はasia-south2とasia-southeast1が「limited availability」とされており、日本リージョンではまだ利用できません。
実際、GPU不足によりインスタンスが起動できないケースには一定の頻度で遭遇しており、リトライすれば利用できることもあれば、しばらく待っても確保できない場合もあります。
そんな中で「 Cloud Run ならNo reservations required」というのは、よく言えば Google Cloud の供給力への期待とも言えますが、Preview段階でユーザーが限られているため、リソースに余裕がある状態に見えているという可能性もあります。GA後にみんなが使い始めたらどうなるか、scale-to-zeroの裏で次の起動時にGPUプールに空きが無かった場合に何が起きるのか、このあたりは実際に使ってみないと見えてこない部分です。
「scale-to-zero × on-demand GPU」という響きはキラキラしていますが、実際にはリソースプールの空き状況に依存します。 Preview中の今と、GA後に利用が拡大した場合とで、体感が大きく変わる可能性はありそうです。
まとめ
ServicesへのSSHを踏み台として活用できるかという話と、GPU周りの起動時間とキャパシティの話、今回のアップデートで個人的に気になったのはこの2つでした。どちらも「発表を聞いた感想」でしかなくて、実際に触ってみないと結論は出せません。帰国後に検証を進めたいと思います。
24時間の移動の疲れがまだ抜けていませんが、初日から興味深いセッションを聞くことができました。残り2日間、体力が持つかだけが心配です。
※Google Cloud および Google Cloud 製品・サービス名称は Google LLC の商標です。
(本記事の内容は、2026年4月時点の情報に基づいています)
このページをシェアする: