初めてのSnowpark for Python from Jupyter Lab

こんにちは
DATUM STUDIO カスタマーアナリティクス部の長谷川です。
Snowflakeでは、分析家にとって非常に強力な機能「Snowpark for Python」が2022年11月に一般公開されていますね!その結果、Pythonを用いてSnowflake上のデータをSnowflake上で取り扱うことができ、クラウドの力を利用したハイパワーな分析が、セキュアな環境で行えるようになりました。
今回は、そんなSnowparkへローカルのJupyter Labから接続してみよう!という記事になります。
目次
1. 環境準備
まずは、ローカルでSnowflakeに接続できる環境を整備しましょう!
今回は、Snowflakeの公式ドキュメント通りに、minicondaからPython3.8が使える仮想環境を構築します。
( minicondaのインストールはこちら)
それでは早速、ターミナルを準備していただいて、下記の要領で環境構築を進めていきましょう。
# 仮想環境の構築 → アクティベート → 必要なパッケージのインストール
$ conda create --name snowpark -c https://repo.anaconda.com/pkgs/snowflake python=3.8
$ conda activate snowpark
$ conda install -c https://repo.anaconda.com/pkgs/snowflake snowflake-snowpark-python pandas
このとき、Apple M1 chipの場合は後々エラーが出てしまうので、下記のように書き直して実行してください。
(公式ドキュメントは こちら)
$ CONDA_SUBDIR=osx-64 conda create --name snowpark -c https://repo.anaconda.com/pkgs/snowflake python=3.8
$ conda activate snowpark
$ conda config --env --set subdir osx-64
$ conda install -c https://repo.anaconda.com/pkgs/snowflake snowflake-snowpark-python pandas
今回は、Jupyter Labからの接続を試すので、Jupyter Labもインストールします。また、後ほど使うscikit-learnも同時にインストールしておきます。
$ conda install jupyterlab
$ conda install -c intel scikit-learn
2. Jupyter LabからSnowflakeへ接続
それでは、早速 Jupyter Labを起動してみたいところですが、Jupyter LabからSnowflakeに接続するための前準備をしておきます。
まずはJupyter Labと接続させるディレクトリ「hoge」に以下のように snowflake_connection.json を用意しておきます。
hoge
├── test.ipynb
└── snowflake_connection.json
snowflake_connection.json の中身はこんな感じです。下記の<XXX>
をご自身のSnowflake環境に合わせて変更してご利用ください。
詳細は公式ドキュメントへ
{
"account":"<組織名>-<アカウント名>",
"user":"<ユーザー名>",
"password":"<パスワード>",
"role":"<ロール>", # optional
"warehouse":"<ウェアハウス名>", # optional
"database":"<データベース名>", # optional
"schema":"<スキーマ名>" # optional
}
accountについてはSnowsight上において、赤字で「アカウント名」とある部分をクリックすることで、下図のように<組織名>と<アカウント名> を調べることが出来ます。
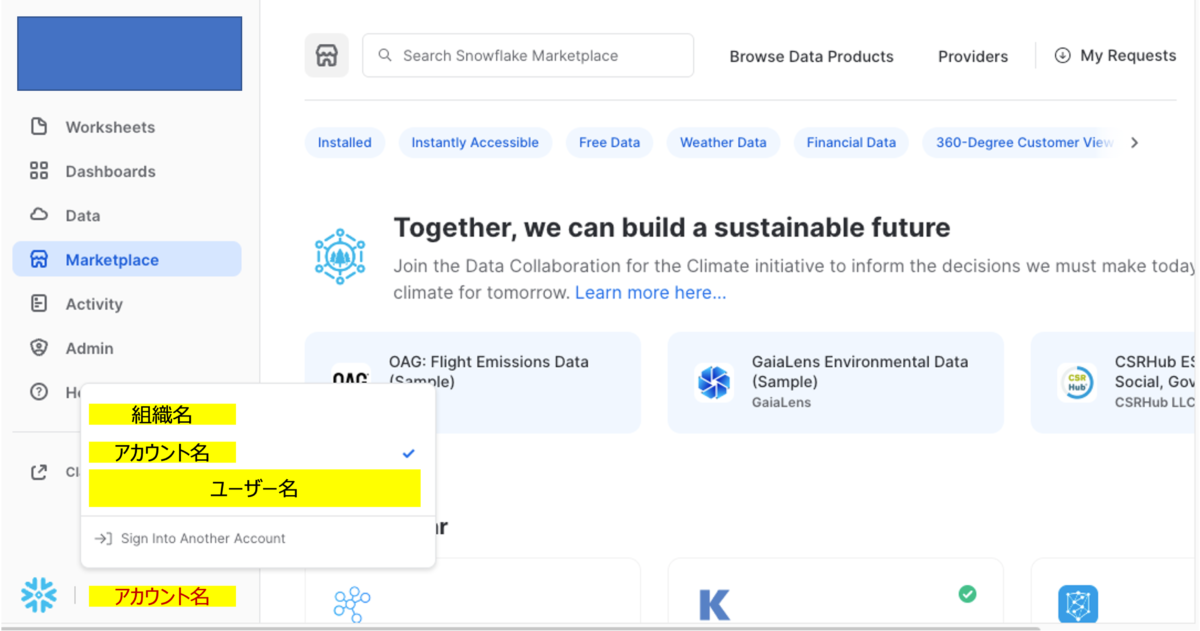
これで準備も終わりましたので、Jupyter Labを起動しましょう!
$ jupyter lab
よしよし!ここまで来れば分析家さんも慣れっこですね。ここからはtest.ipynbの内容となります。
早速、Snowflakeとの接続に必要なモジュールをnotebook上でインポートしていきましょう。
from snowflake.snowpark.session import Session
import json
必要なモジュールはこれだけなので、早速、セッションを作成していきましょう。
snowflake_connection_cfg = json.loads(open('./snowflake_connection.json').read())
session = Session.builder.configs(snowflake_connection_cfg).create()
はい!これでセッションも作成し、Snowflakeとの接続が完了しました!
簡単な接続テストとして、以下のコードによりDB一覧を取得してみましょう。
# check the connection with snowflake server by sql for showing databases
session.sql('show databases').collect()
3. Jupyter Labからのテーブル作成とデータのアップロード
せっかくセッションを確立したので、簡単な操作をしてみましょう。ここでは、Jupyter
LabからSnowflakeテーブルの作成と、データのアップロードを試してみたいと思います。
今回はデータとして、scikit-learnのirisデータを登録してみます。
# import module
import pandas as pd
from sklearn.datasets import load_iris
# get data and show
iris = load_iris()
df_local = pd.DataFrame(iris.data, columns=iris.feature_names)
df_local['species'] = [iris.target_names[i] for i in iris.target]
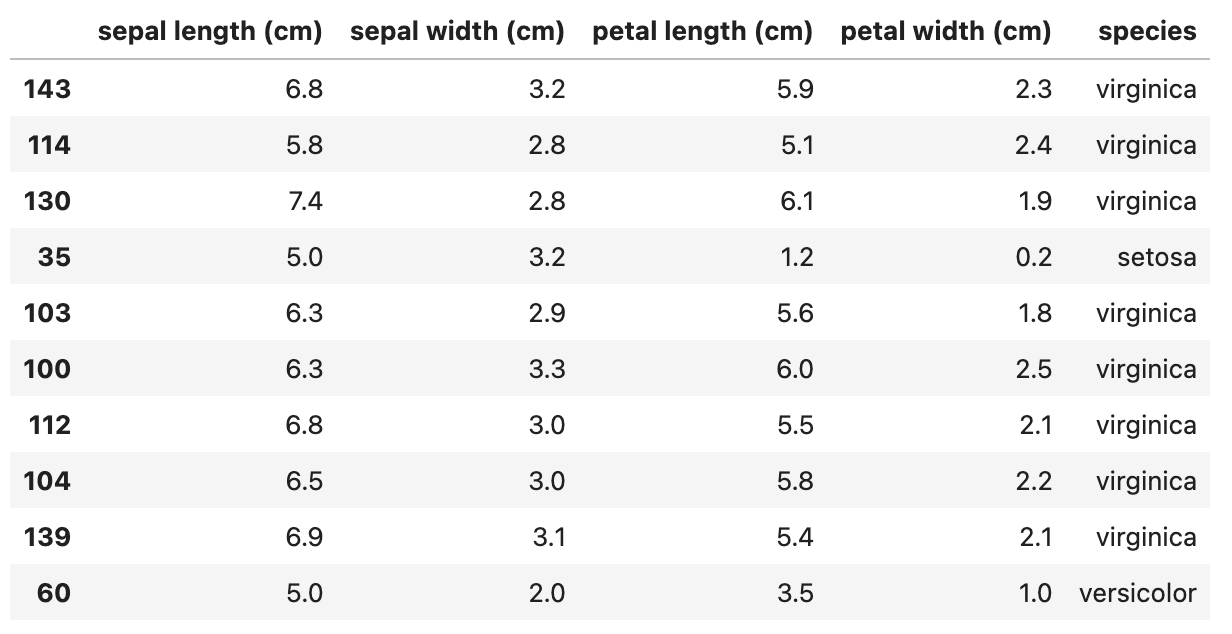
df_local.sample(10)
最後に、irisデータからランダムに10個のデータを表示しているので、こんな結果が得られると思います。
それでは、データベースの作成 → スキーマの作成 → テーブルの作成を順に行ってみたいと思います。
# Create a db
session.sql("create or replace database iris;").collect()
# Create a schema
session.sql("create or replace schema iris_data;").collect()
# Create a table
query = '''
create or replace table iris
(
sepal_length float,
sepal_width float,
petal_length float,
petal_width float,
specie string
)
;
'''
session.sql(query).collect()
これでテーブルの作成まで終わりましたので、ちゃんと作成されているのか、確認してみましょう。
session.sql("show tables in iris.iris_data;").collect()
結果の中に、下記のように情報が表示されていることと思います。
name=’IRIS’, database_name=’IRIS’, schema_name=’IRIS_DATA’, kind=’TABLE’
それでは、こちらのテーブルに先ほどのirisデータ(df_local)を登録していきたいと思います。
df_local.columns = [x.upper() for x in ["sepal_length", "sepal_width", "petal_length", "petal_width", "specie"]]
session.write_pandas(df_local, "IRIS")
こちらで、データの登録が完了しました。
SnowflakeのUIからもデータが登録されているかを確認してみると、
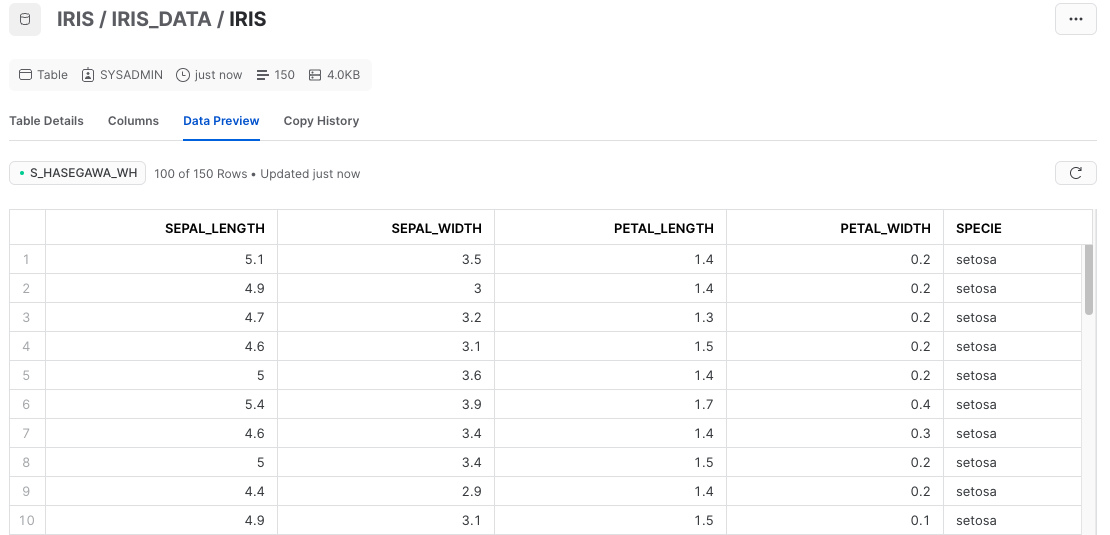
ちゃんと登録されていました!!!
ちなみに、write_pandasには下記2点の引っかかりPOINTがあるのでご注意を!
(先ほど作ったIRISテーブルのテーブル名・カラム名が大文字になっているからですね)
4. Jupyter Labからのデータのロード
それでは、最後にSnowflake上に存在するirisデータへ接続してみましょう。
df_snowpark = session.sql("select * from IRIS")
これで、df_snowparkにSnowflake上のirisデータが格納されました。
ローカルのdataframeとの違いとして、そもそもの型が違うのでそれを確認して今回は終わりにしましょう!
display(type(df_local))
display(type(df_snowpark))
それぞれ、下記のような結果が得られたと思います。
pandas.core.frame.DataFrameに関しては、特筆することもない普通のpandas
dataframeですね。一方で、snowflake.snowpark.dataframe.DataFrameはsnowflake専用の型となっています。
この型はSnowflake上でのdataframeを表す型となっています。
Snowflake上のdataframeをローカルのpandas dataframeにしたい場合は、以下のようにto_pandas()をすることで取得することができます。
df_topandas = df_snowpark.to_pandas()
display(type(df_topandas))
こうすることで、Snowflake上のデータをいつものpandasとして取り扱うことができるので、非常に便利ですね!
では最後に、必要でなければ作ったDBを削除しておきましょう!
df_snowpark = session.sql("drop database IRIS;").collect()
まとめ
今回は、snowparkへローカルのJupyter Labから接続することについて紹介しました。
現在は、snowparkを用いての機械学習トレーニングが出来るようにメモリサイズの大きいウェアハウスも用意されていますし、streamlit統合が開発されていたりと楽しみなことがいっぱいですね!
このページをシェアする: