連載:Azure HDInsightでR Serverを利用する(環境構築編)
目次
はじめに
みなさん、こんにちは! DATUM STUDIOの宇佐見です。
普段の業務ではRを使って様々な分析をしております。 最近ではPythonでの業務も増えており、Rすまないという思いが若干あります。 そこで今回はAzure HDInsightのR Serverを利用してみようと思います。
環境構築編、パフォーマンス測定編と2回に分けてR Serverを取り上げていきます。 環境構築編の今回はHDInsightの起動とサンプルコードの実行になります。
Azure HDInsightとは
クラウド環境であるAzureからHadoop, Sparkのクラスターを作成するサービスとなります。 クラスターの起動はAzureのダッシュボード上から容易に行うことができ、 データ量に応じてスケールアウト、スケールアップも可能です。 データへのアクセスはHiveやSparkなどから行い、Jupyter Notebookも利用することができます。
AWSではEMR、GCPではCloud Dataprocにあたるサービスとなります。
R Serverとは
R ServerはMicrosoftが提供しているシェアウェアです。 RStudioのServer版やShinyのようにRをServerとする技術ではありません。 Server上での利用が前提となるRの拡張版です。
もとはRevolution R社が開発したRevolution R EnterpriseがR Serverのベースとなります。 2016年にMicrosoftがRevolution R社を買収し、Revolution R EnterpriseはR Serverへ名前が変更されます。
R ServerはオープンソースであるRを拡張したもので、メモリに乗り切らないデータを扱うことや、 マルチスレッド、並列実行などを可能にします。 並列実行用にカスタマイズされた関数も用意されており、意識することなく並列実行が可能です。
Azure HDInsight R Serverとは
ではAzure HDInsight R Serverはどこがいいのか?という話になります。
まずはワンストップでHadoopのクラスターとR Serverの利用ができることです。 EMRやCloud Dataproc上でR Serverの利用はライセンスや各クラスターの設定などで非常に困難なことが予想されます。 自らHadoopのクラスターを作成してR Serverを動かすことはできます。 しかしHadoopのクラスターを自前で管理するのは非常にコストがかかります。 Azure HDInsight R Serverを利用すれば容易に扱うことができるようになります。
続いて従来のRではできなかった並列実行が容易にできることが挙げられます。 演算処理をHadoopのMapReduceやSparkのクラスターで行うことにより、 意識せずにその恩恵に預かることができます。 Rの皮をかぶったHadoop,Sparkを扱っているようなものです。
今までは高価なオンプレ環境で利用されることの多かったR Serverとは縁がないと私は思っていました。 しかしAzure HDInsight R Serverのおかげで非常に身近に利用することができるようになりました。
欠点としては最小の構成でも1時間あたり300円以上かかってしまうことです。
Azure HDInsight R Serverの利用方法
前提
Azureのサブスクリプションを保持していることが前提条件となります。 またあらかじめリソースグループ、ストレージアカウントと設定しておくことが望ましいです。
Azure HDInsight R Serverの起動
左のメニューから「新規」をクリックし、「Data + Analytics」、「HDInsight」を選択します。
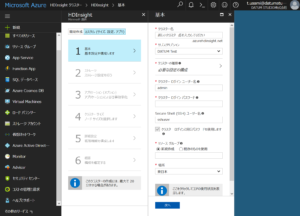
上部にあるトグルを「簡易作成」から「カスタム」に変更します。 (簡易作成のままだとworkerノード数やノードのスペックを変更することができません)
まずは基本となる設定を埋めていきます。 注意事項としてRStudioのサーバ版を通してR Serverの操作を行うため、 公開鍵を登録してのログインではなく、パスワードを用いてのログインとなります。
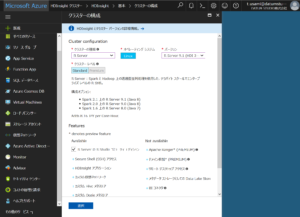
クラスタの種類の項目を選択すると、HDInsightをどのような形式で起動するか選択することができます。 クラスターの種類で「R Server」を選択します。 それ以外はデフォルトのままで大丈夫です。
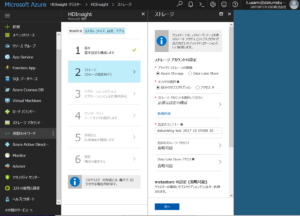
続いてストレージの項目ですが、前もって作成しておいたストレージアカウントを選択するだけで大丈夫です。 アプリケーションの項目も同様です。
クラスターサイズの項目ではワーカーのノード数を決定し、各種ノードのスペックを決めます。 ワーカーのノード数、スペックを増やすとHDInsight全体のHadoopの性能が上がります。 ワーカーのノード数は起動後でも変更することが可能です。 エッジノードについてはRStudioのサーバ版が動くサーバになるため、 データの前処理などをある程度行う場合はスペックが必要となります。
ヘッドノード、zookeeperノードについてはワーカーノードに効率よくデータを分配するためのノードになります。 デフォルトのままの設定で大丈夫です。
R Serverを利用する場合は各ノードの全コア数ごとにR Serverライセンス料が追加で発生します。
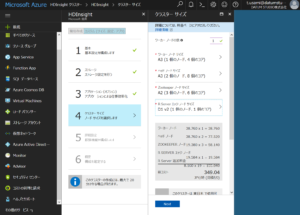
詳細設定については特に設定する必要はありません。
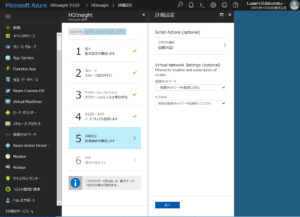
これだけの情報でAzure HDInsight R Serverを起動することができます。 ただし起動には20分以上かかることもあるので注意が必要です。 以下は起動後のダッシュボードのスクリーンショットになります

RStudioの利用
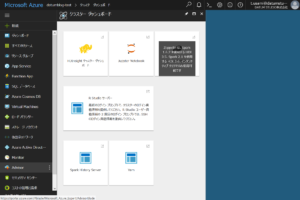
ダッシュボードの「R Server ダッシュボード」、「RStudio ダッシュボード」をクリックするとノードエッジにあるRStudioにアクセスすることができます。
はじめの認証ではクラスター管理者のユーザID(デフォルトではadmin)でログインします。 次の認証ではクラスター管理者のユーザID(デフォルトではsshuser)でログインします。
この画面からR Serverの操作を行います。
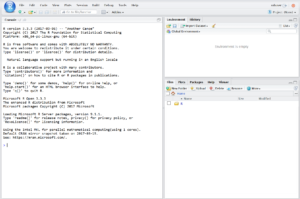
サンプルコードを実行する
ここにあるサンプルコードを実行していきます。 しかしサンプルコードをそのままコピペするだけでは正常に実行されず、データの読み込み部分でエラーとなります。
エラー箇所の修正
ファイルの取得部分を以下のように書き換える必要があります。
download.file(file.path(remoteDir, "airOT201201.csv"), file.path(source, "airOT201201.csv"), method = "wget") download.file(file.path(remoteDir, "airOT201202.csv"), file.path(source, "airOT201202.csv"), method = "wget") download.file(file.path(remoteDir, "airOT201203.csv"), file.path(source, "airOT201203.csv"), method = "wget") download.file(file.path(remoteDir, "airOT201204.csv"), file.path(source, "airOT201204.csv"), method = "wget") download.file(file.path(remoteDir, "airOT201205.csv"), file.path(source, "airOT201205.csv"), method = "wget") download.file(file.path(remoteDir, "airOT201206.csv"), file.path(source, "airOT201206.csv"), method = "wget") download.file(file.path(remoteDir, "airOT201207.csv"), file.path(source, "airOT201207.csv"), method = "wget") download.file(file.path(remoteDir, "airOT201208.csv"), file.path(source, "airOT201208.csv"), method = "wget") download.file(file.path(remoteDir, "airOT201209.csv"), file.path(source, "airOT201209.csv"), method = "wget") download.file(file.path(remoteDir, "airOT201210.csv"), file.path(source, "airOT201210.csv"), method = "wget") download.file(file.path(remoteDir, "airOT201211.csv"), file.path(source, "airOT201211.csv"), method = "wget") download.file(file.path(remoteDir, "airOT201212.csv"), file.path(source, "airOT201212.csv"), method = "wget")
データの取得先はリダイレクトがかかる仕様になっています(2017/12/15現在)。 UNIXライクなOSではdownload.fileの実行時にはcurlが呼ばれます。 curlではオプションを指定しないと、リダイレクト先のファイルを取得することができないため、 wgetを利用するように修正します。
普段ならばこれらのエラーはデータフレームの作成時(データの読み込み時)に分かるため、大きな問題にはなりません。 しかしR Serverの実行環境では従来のようにデータフレームを作成せずHDFSファイルを直接操作するため、読み込み時のエラーが非常に検知しづらいことが問題の1つに挙げられます。
おわりに
このようにAzure HDInsightを利用すれば簡単にR Serverを利用することができます。 次回は起動したR Serverを利用してパフォーマンスの測定を行っていきます。
参考資料
このページをシェアする: