Databricks Data + AI Summit 2026 最速レポート 最終日
セッションレポート(セマンティックキャッシュ)

目次
みなさんこんにちは!DATUM STUDIOの亀井です。
サンフランシスコで開催中のDatabricks Data + AI Summit 2026(DAIS 2026)最終日のレポートをお届けします。
本日は、AIエージェントの運用コストを抑えるための技術である「セマンティックキャッシュ」を扱ったセッション、「Cache Smarter, Not Harder: Building a Semantic Cache Gateway with Lakebase and MLflow」を紹介します。
登壇されたのは、Databricksのお二人(Specialist Solution ArchitectのAnanya Roy氏、Solution ArchitectのBrian Law氏)です。LLMのコストに関する、エージェントを本番運用するうえで避けて通れないテーマを、Databricks上での具体的な実装例と合わせて緩和策を示した内容でした。
エージェントは便利だが、コストが高くなる
セッションでは、エージェントは便利だが高くつくという話から始まりました。
エージェントの特徴として、次の3点が挙げられました。
- (1)High Velocity(毎分数百万回規模の呼び出しが発生しうる)
- (2)Hidden Costs(気づかないうちに高額になる)
- (3)Incremental LLM Spend(LLMへの呼び出し1回ごとにコストが積み上がる)

具体例として、社内向けチャットボットの試算が示されました。
10,000人の従業員が1日あたり10件の質問を送ると、それだけで1日10万回LLMを呼び出すことになります。
同じ意図、異なる言い回し
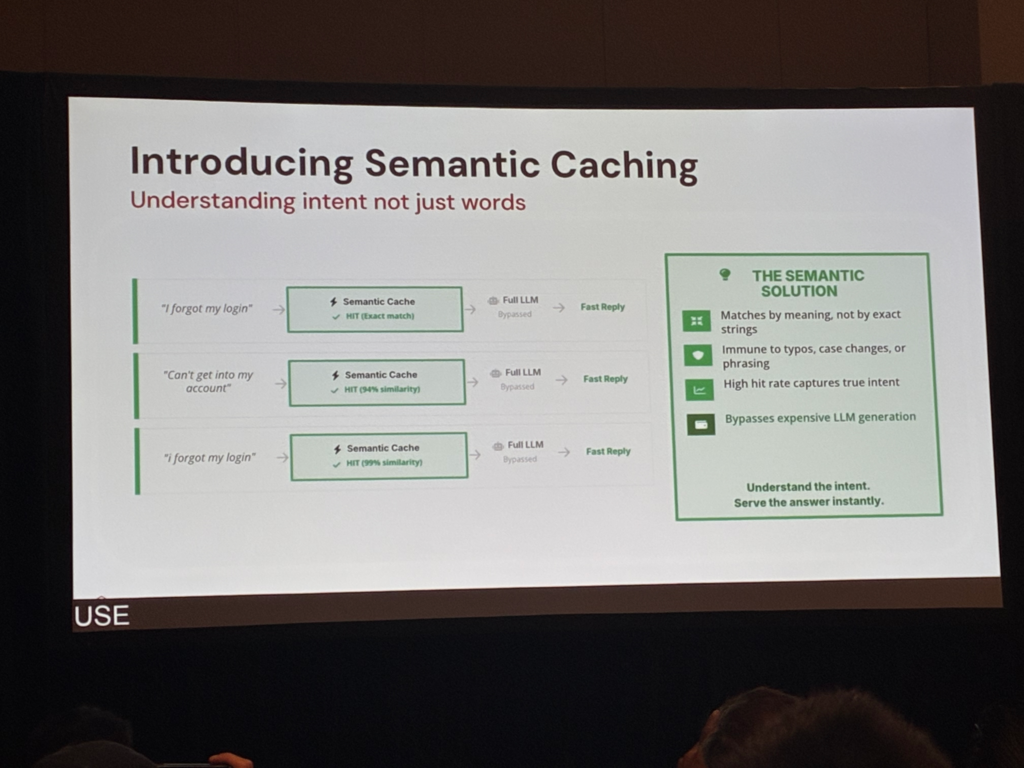
コストが膨らむ背景として、「ユーザーは同じことを尋ねるのに、毎回違う言葉を使う」という点が強調されました。
たとえば、同じパスワードリセットに関する質問でも、「I forgot my login」「Can’t get into my account」「Where do I reset my password?」のように、表現はさまざまです。
返品に関する質問や営業時間に関する質問でも同様で、文字列としては別物でも、その背後にある意図(intent)は同じです。

ここで、文字列の完全一致によるキャッシュ(exact match)だけでは取りこぼしが多く、ヒット率が上がらないという課題が提示されました。
完全一致は一部のケースでは有効であるものの、表記ゆれやタイプミスに弱く、キャッシュヒットの割合が低い状態が続く可能性があります。その結果、根本的な問題を解決しないまま追加のインフラコストを払うことになります。
セマンティックキャッシュという解決策
そこで有用なのがセマンティックキャッシュです。質問を文字列としてではなく「意味(埋め込みベクトル)」として扱い、過去の質問の中から意味的に近いものを探す、という仕組みです。
意味で照合するため、タイプミスや言い回しの違い、語順の変化に強くなります(多言語対応については、登壇者から「その領域については確証がない」という留保が添えられていました)。キャッシュにヒットすれば、LLMの推論ステップそのものをスキップできるため、コストとレイテンシをともに削減できます。
キャッシュを挟むことで、同じ意図の3つの質問「I forgot my login」「Can’t get into my account」「i forgot my login」がいずれもセマンティックキャッシュにヒットし(順に完全一致 / 94%類似 / 99%類似)、フルLLM推論をバイパスして高速に回答を返すことができます。
処理フローは、6ステップ
キャッシュを挟んだ場合のフローは、次の6ステップとして示されました。
- 1.Ask:ユーザーが質問する
- 2.Search:キャッシュを検索し、意味的に近い過去の質問を探す
- 3.Match:十分に近い一致があるかを判定する
- 4.Reuse(一致した場合):キャッシュ済みの回答をそのまま返し、推論をスキップする
- 5.Run full reasoning(一致しない場合):新しい質問とみなし、通常どおりLLMで回答を生成する
- 6.Write to cache:生成した「質問・回答・埋め込みベクトル」をキャッシュに保存し、次の類似質問に備える

スライドの上部に書かれている通り、まずキャッシュを検索し、十分に近いものがない時だけ推論するというフロー設計になっています。
新しい質問に対する推論は、一度きりのコストとして許容し、その結果を保存することで以降の類似質問は高速かつ低コストで返せるようになります。判定の閾(しきい)値次第で、どこまでを「似ている」とみなすかを調整できる、という説明もありました。
ここはチューニングポイントであり、実際に導入する際は具体的な質問例を用いた閾値調整と継続的な確認が必要になりそうです。
Databricks上でのアーキテクチャ
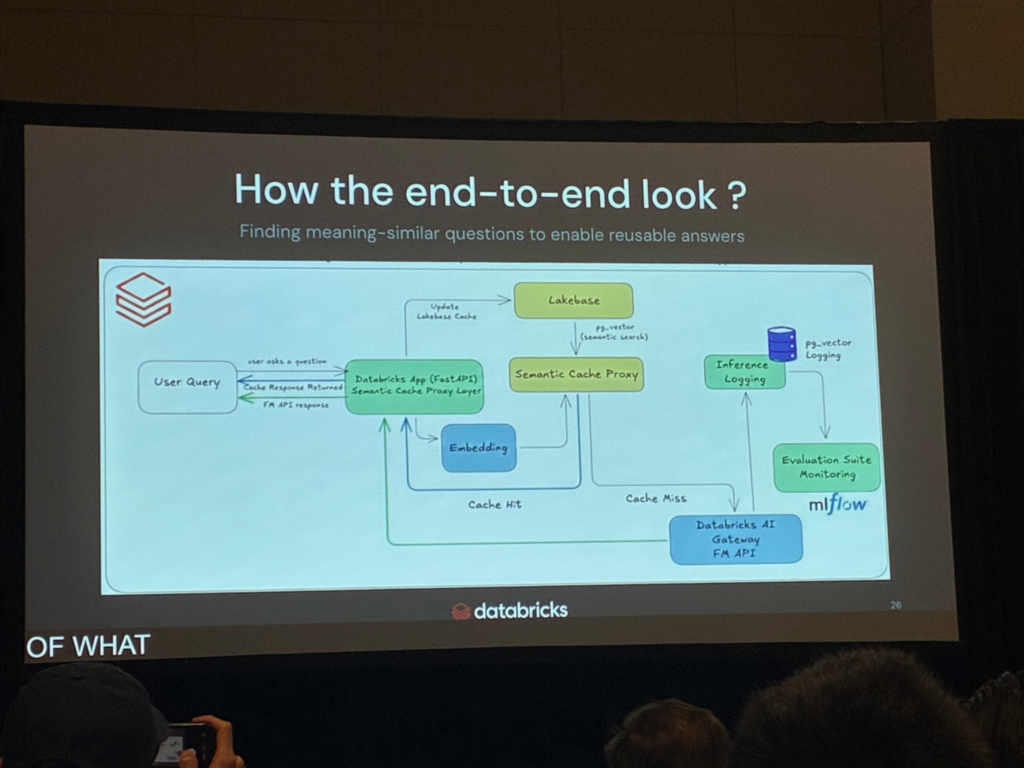
後半は、これをDatabricks上でどのように実装するかという、技術的な話に移りました。エンドツーエンドの構成は、概ね次のような流れです。
- ・ユーザーの質問を受けるのは、Databricks Apps上にFastAPIで構築したSemantic Cache Proxy Layer
- ・質問はEmbeddingでベクトル化され、Lakebaseに対してpgvectorによる意味検索(semantic search)を実行
- ・Cache Hitの場合、キャッシュ済みの回答をそのまま返す
- ・Cache Missの場合は、Databricks AI Gateway(Foundation Model API)を経由してLLMで回答を生成し、その結果をLakebaseのキャッシュに書き戻す
- ・これらの推論ログやキャッシュイベントはMLflow側に記録され、Evaluation Suiteによる評価・モニタリングにつなげる
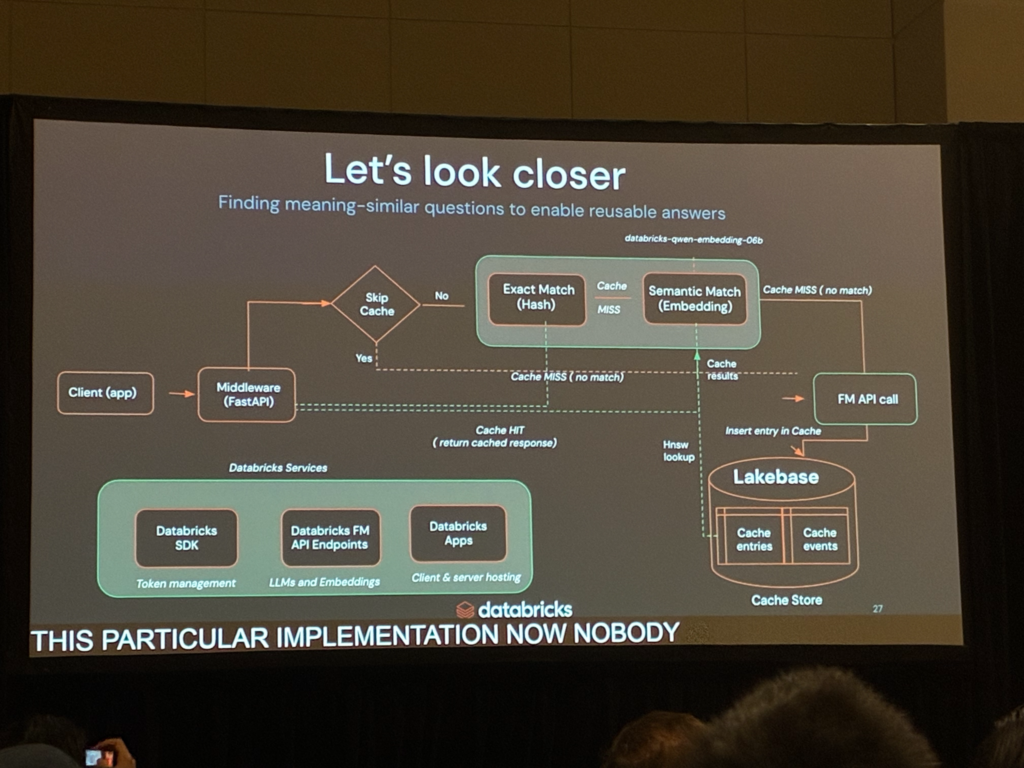
照合は二段構えで、まず完全一致(Exact Match / Hash)を見て、外れた場合に意味一致(Semantic Match / Embedding)へ進む形が示されていました(これはRAGを構成する際にも使われるテクニックであり、完全一致の方が安くて簡単なためであると考えられます)。
埋め込みモデルとしては、databricks-qwen-embedding-06bが使われていました。
なぜ、Lakebaseなのか
キャッシュの保存先としてLakebaseを選ぶ理由も示されました。Lakebaseは、pgvectorをネイティブにサポートするDatabricksマネージドのPostgreSQLで、構造化データとベクトル検索を1か所で扱える、という位置づけです。
発表で挙げられた利点は、次のとおりです。

- ・Native pgvector:
- 1024次元の埋め込みをネイティブのカラムとして保存でき、外部のベクトルDBが不要。使い慣れたSQLでクエリできる
- ・HNSW Index:
- 近似最近傍検索を15ミリ秒未満で実行でき、数百万件規模の埋め込みにスケールする(m=16, ef=200 などで精度を調整可能)
- ・Managed PostgreSQL:
- スケーリング・バックアップ・パッチ適用をDatabricksが担うため、インフラ管理の負担が小さい
- ・OAuth Integration:
- トークンベースのアクセスにより、静的なパスワードを持たずにDatabricks Appsと連携できる
- ・Unity Catalog:
- キャッシュデータに対して、ガバナンス・リネージ・監査を効かせられる
- ・Structural + Vector:
- メタデータ照会(TTL、owner_id、modelなど)とベクトル検索を同一トランザクションで扱え、ストア間のデータパイプラインが不要
向く用途・向かない用途
発表では、セマンティックキャッシュがすべてのユースケースに適するわけではない、という点も率直に語られていました。
向いているのは、繰り返しが多く汎用的なタスクです。具体的には、定型質問の多いカスタマーサポート / 社内ヘルプデスクのチャットボットや、パターンが繰り返し現れるエージェント型RAGワークフロー、ツールルーティングの判定、Text-to-SQL、意図分類などが挙げられました。
いずれも「同じ意図なら同じ回答でよい」「出力空間が小さい」といった性質を持つものです。
一方、向かないのは、データが頻繁に変わるパーソナライズされたエージェントや、リアルタイム性・最新の事実確認が必要なクエリ、一意な回答が求められる定量的な質問などです。
クリエイティブな文章生成(新規性そのものが目的)、ストリーミング応答(部分トークンはキャッシュできない)、高temperatureの意図的に非決定的な生成も、対象外とされていました。

登壇者は、判断の指針として「同じ質問を二度して、毎回違う答えを期待するなら、キャッシュしてはいけない(The Golden Rule)」という一言を紹介していました。
運用のベストプラクティス
最後に、本番運用に向けたチューニングと注意点が示されました。

照合の閾値(類似度)の調整については、目安として次の整理が示されました。
低すぎる(0.85未満)と「What is PTO?」と「What is the parking policy?」のように意図の異なる質問を取り違え、ヒット率は高まるが正確性を損ないます。逆に高すぎる(0.97超)と完全一致とほぼ変わらず、軽微なタイプミス程度しか拾えません。
発表では、0.90〜0.95あたりがバランスの取れた範囲とされ、まず0.92から始めてドメインに合わせて調整することが推奨されていました。
運用面のチェックリストとしては、ヒット率・節約できたトークン数・レイテンシのパーセンタイルを追い、cache_eventsテーブルのログをもとにヒット率低下にアラートを張る「モニタリング」、頻出質問を事前に流し込んでおき、ピーク前にキャッシュを温めておく「キャッシュウォーミング」、X-Cache-Owner-Idでテナントごとにキャッシュを分離する「マルチテナント分離」、データの鮮度に応じてTTLを設定する「TTL戦略」(例:HR文書は7日、株価などはキャッシュしない)などが挙げられました。
まとめ
本セッションは、多くのAIユーザーが抱えるエージェントのコスト問題に対する緩和策としてセマンティックキャッシュを紹介し、Databricks上での実装まで具体的に示した内容でした。
LakebaseのネイティブなpgvectorとMLflowによる評価・監視を組み合わせ、外部のベクトルDBを足さずに完結させる構成は、すでにDatabricksを使っている環境であれば現実的な選択肢になりそうだと感じました。
保存先のLakebaseについては、一瞬「コストに見合うのか」が気になりましたが、scale-to-zeroが効くのであれば、思っていたほど高くつかないかもしれません。このあたりは、実際のワークロードで確かめたいところです。
あわせて気になったのが、キャッシュヒットの精度です。社内独自の用語やその同義語の意味の一致判定が課題になる可能性があり、ベクトル化してインサートする前にタグやシノニムを付けておくといった前処理が必要になると思いました。発表でも触れられていた閾値の設定とあわせ、「キャッシュしてよい質問かどうか」の見極めと、閾値・TTLのチューニングが運用の肝になりそうです。
私自身も、AIエージェントの構築に携わっているため、ヒット率と正確性のトレードオフをどう設計するかは、帰国後に手を動かして確かめてみたいテーマです。
今までセマンティック検索は、Databricks AI Search(旧:Databricks Vector Search)が先行で担ってきた領域であり、pgvectorと比較して大規模なデータに対応できる部分に優位性がありました。ただ、今回のDAIS 2026で発表されたLakebase Searchの公式ドキュメントには「10億レコードまでのベクトルデータが格納できる」と記載されており、Databricks AI Searchと同じ規模で対応できるようになりました。セマンティック検索の領域もLakebase側に寄せていこうというDatabricks社の意図が見えました。
また、発表の最後で触れられていたキャッシュの分離レベルも、重要な設計ポイントです。
分離レベルが高すぎるとキャッシュのヒット率が下がり、低すぎると同一質問に対する回答が部署ごとに異なるケースでハルシネーションが発生するリスクが上がります。どこまでを共通のキャッシュとし、どこからをテナント特有のキャッシュとして分離するかなど、設計上考えることがたくさんあるため、導入する際は注意深く考える必要がありそうです。
これでDAIS 2026の現地レポートは最終回となります。4日間お読みいただき、ありがとうございました!
このページをシェアする: