Snowflake Summit 2026最速レポート 最終日
【セッション解説】KafkaをそのままSnowflakeへ 新サービス「Snowflake Datastream」を深掘る

目次
はじめに
こんにちは、DATUM STUDIOの鈴木です。
いよいよSnowflake Summit 2026の最終日となりました。
本日は、Introducing Snowflake Datastream(DE305)を聴講してきました。
テーマは、つい2日前のPlatform Keynoteで発表された新サービスSnowflake Datastreamについてです。
本セッションの内容は、Platform Keynoteで示された全体像から一歩踏み込み、アーキテクチャやインターフェイス、ライブデモまでを扱う深掘りの回でした。
登壇されたのは、Snowflake社のSai Maddali氏(Principal Product Manager)とTyler Jones氏(Principal Software Engineer)です。セッションの前半ではサービスの狙いについての説明、後半がアーキテクチャとデモの実演という構成でした。
Datastreamは簡単に言うと、Kafka互換のフルマネージドなストリーミングサービスです。KafkaクラスタやKafka Connect、コネクタを自前で持たずに、既存のKafkaクライアントをほぼそのままSnowflakeへ繋げます。現在は、Private Preview soon(数週間後に開始予定)という段階でした。セッションで特に印象に残った点について、順を追ってまとめます。
なぜ今、データの鮮度が重要なのか
セッションは「どんな場面でデータの鮮度が効くのか」という話から始まりました。クリックストリーム分析でのコンバージョン改善、リアルタイムの相関と異常スコアリングによるセキュリティ・脅威分析、予知保全によるIoTのダウンタイム削減、継続的な特徴量生成とオンライン推論によるパーソナライゼーション、いずれも「その瞬間に動けること」が価値になる領域です。
そして、エージェントAIがこの鮮度をよりいっそう必要としている、という整理が示されました。エージェントが信頼できる判断を下すには、ストリーミングでデータを新鮮に保つことと、セマンティックレイヤー(Semantic View)でビジネス上の意味を保つことの両方が必要である、という説明です。高速なデータストリームが、即時の判断とアクションを促し、フィードバックループが応答性を高めていく、という図でした。
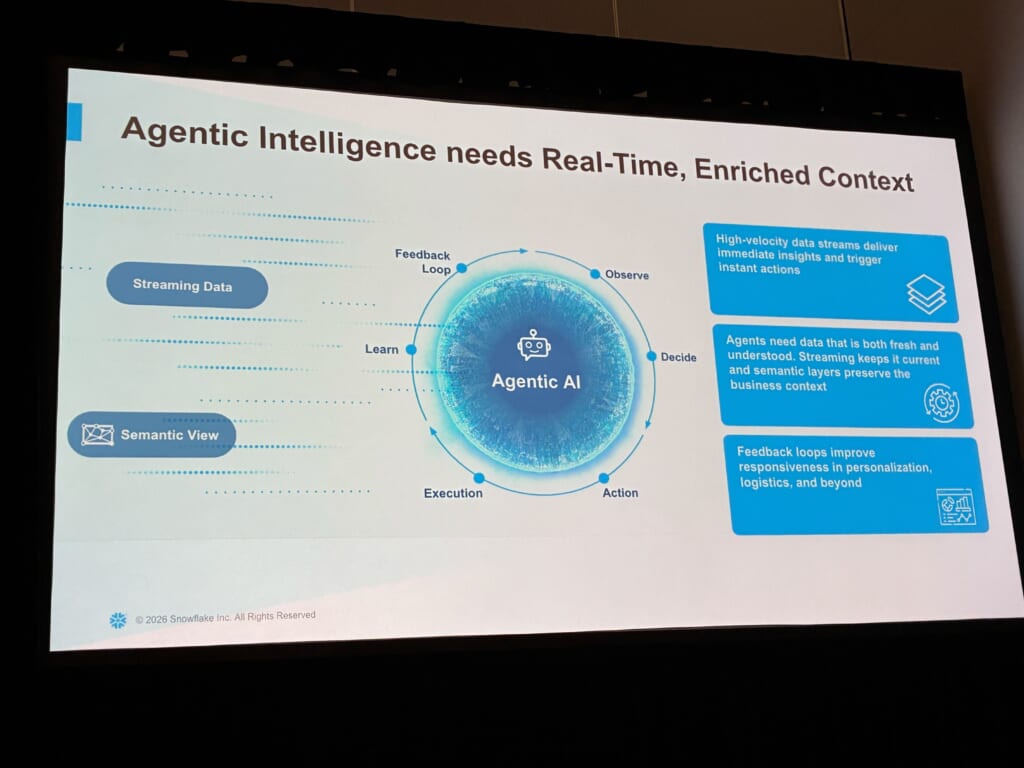
Kafkaは広く使われているが、障壁もある
次に言及されたのは、Kafkaです。
メトリクス・トレース・ログ・通知・アラートといったあらゆるシグナルがKafkaに集まり、運用監視やオブザーバビリティの背骨になっているとのことです。
ところが、そのKafkaからフレッシュなインサイトを得るには壁があるという話に続きます。挙げられたのは次の4つでした。
- 1.バッチETLからの作り直し
- 2.ウォーターマークやイベントウィンドウといったストリーム処理特有の学習コスト
- 3.分析と比べて高くつくコスト
- 4.Snowflakeのようなシンプルさがストリーミングにはない、という運用オーバーヘッド

Datastreamは中間の処理をまるごと省く
ここでDatastreamの提案です。
これまでKafkaでデータを分析基盤へ運ぶには、Producer → Kafkaクラスタ → Kafka Connect → コネクタ → テーブル、と何段も経由する必要がありました。登壇者によると、この段ごとに設定や障害点が増えることが運用の負担となり、「ストリーミングは分析より、4倍高い」と語る顧客もいたそうです。
Datastreamはこの中間部分を丸ごと無くし、Producer → Datastream → テーブル(Snowflake / Iceberg)へと処理することを実現します。
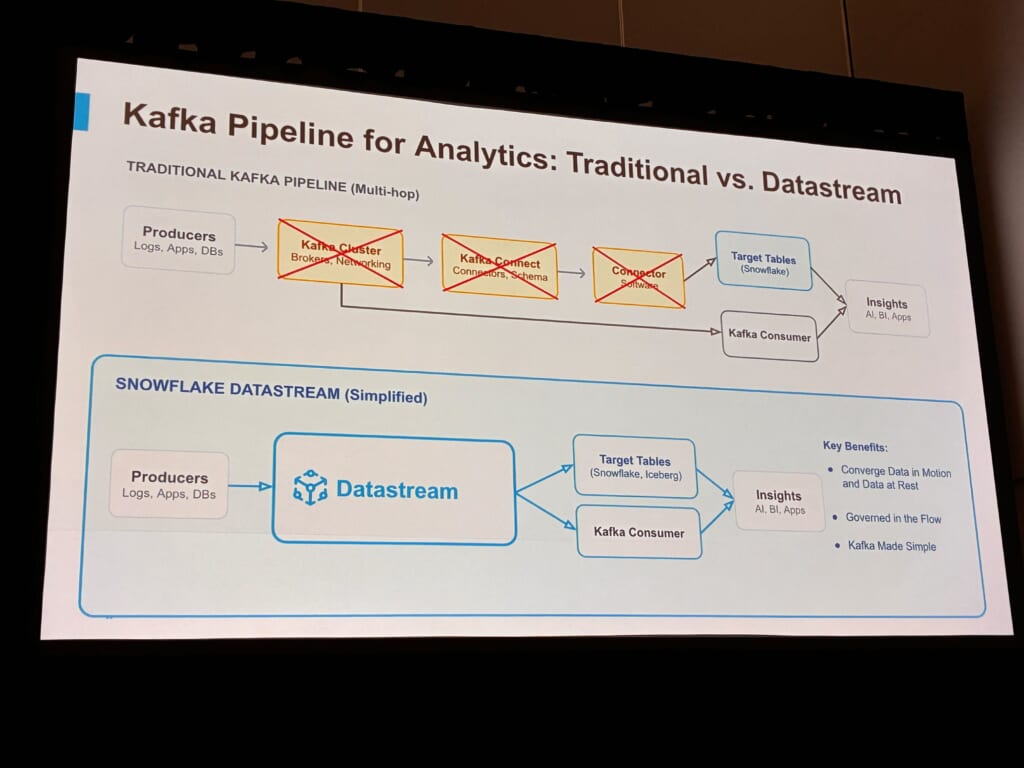
メリットとして示されていたのは、既存のKafkaとテーブルにそのまま繋げて作り直しが要らないこと、SELECT・JOIN・GROUP BYなど、使い慣れたSQLを数秒単位の鮮度を持つデータに対して書けること、クラスタのプロビジョニングやチューニングが不要で、TCO(Total Cost of Ownership)が下がること、そして、Snowflakeの他機能と同じ手軽さでストリーミングを扱えることでした。
「コネクタでもストリーム処理エンジンでもなく、トピックとテーブルを同じものとして扱うフルマネージドのサービス」という説明が、このサービスの位置づけをよく表していると感じました。
使い方は自然言語・SQL・Kafka APIから選べる
使い方として、同じ機能に3通りの操作方法が用意されている点が目を引きました。
1つ目は、自然言語です。
Snowflake CoCoに「Kafkaベースのリアルタイム・パイプラインを作って」と頼むと、トピック・テーブル・パイプまで組み立ててくれます。デモでは、APIエラーのトレースをSnowflakeに取り込みたいという相談に対し、CoCoがトピックを作り、ランディング用のテーブルを定義していく様子が示されていました。
2つ目は、SQLです。
snow datastream系のコマンドで、Datastream・topic・pipeを宣言的に作成できます。
-- Create a datastream snow datastream create <DATASTREAM_NAME> -- Create a topic snow datastream topic create <TOPIC_NAME> \ --datastream <DATASTREAM_NAME> \ --partition-count <PARTITION_COUNT> -- Create a pipe snow datastream pipe create <PIPE_NAME> \ --datastream <DATASTREAM_NAME> \ --topic <TOPIC_NAME> \ --table <TARGET_TABLE_NAME>
3つ目は、Kafka APIです。
既存アプリは、接続先(bootstrap server)をDatastreamのエンドポイントに向けるだけで、あとはそのまま動きます。
# Python - change one line
producer = KafkaProducer(
bootstrap_servers='<SNOWFLAKE_KAFKA_ENDPOINT>'
)
# Everything else stays the same
producer.send('<TOPIC_NAME>', value=event_payload)
「同じトピックに対して、1つのプラットフォームを3通りの使い方で」とまとめられていました。Kafkaに詳しくない人は自然言語で、パイプラインを組む人はSQLで、既存資産はAPIで、というように、自然言語からSQL、Kafka APIまで対応する幅広さが、Datastreamの特徴です。
「クラスタ」ではなく「データ」から始める
繰り返し語られたのが、出発点を「クラスタ」ではなく「トピック(データ)」に置くという考え方です。
従来はクラスタから始め、パーティションやレプリケーション、リバランスを意識し、スケールはクラスタのリサイズで行うというものでした。
Datastreamでは、トピック(カタログ上の資産)から始め、データ・鮮度・パイプラインで考え、スケールは「ブローカーグループの割り当て」で行います。ウェアハウスを増やす感覚に近い、という説明でした。

具体的には、1つのDatastreamシステムの下に、用途別のブローカーグループをぶら下げます。
不正検知用は高スループットで常時稼働、分析パイプライン用は定常でコスト最適化、使わないものは停止(データは残したまま)。ソースはKafkaアプリ(コード変更なし)、Java / Python / Node.jsのアプリ、PostgreSQL / MySQLでのCDC(Change Data Capture)、マイクロサービス、エージェント、テーブルと、幅広く想定されています。
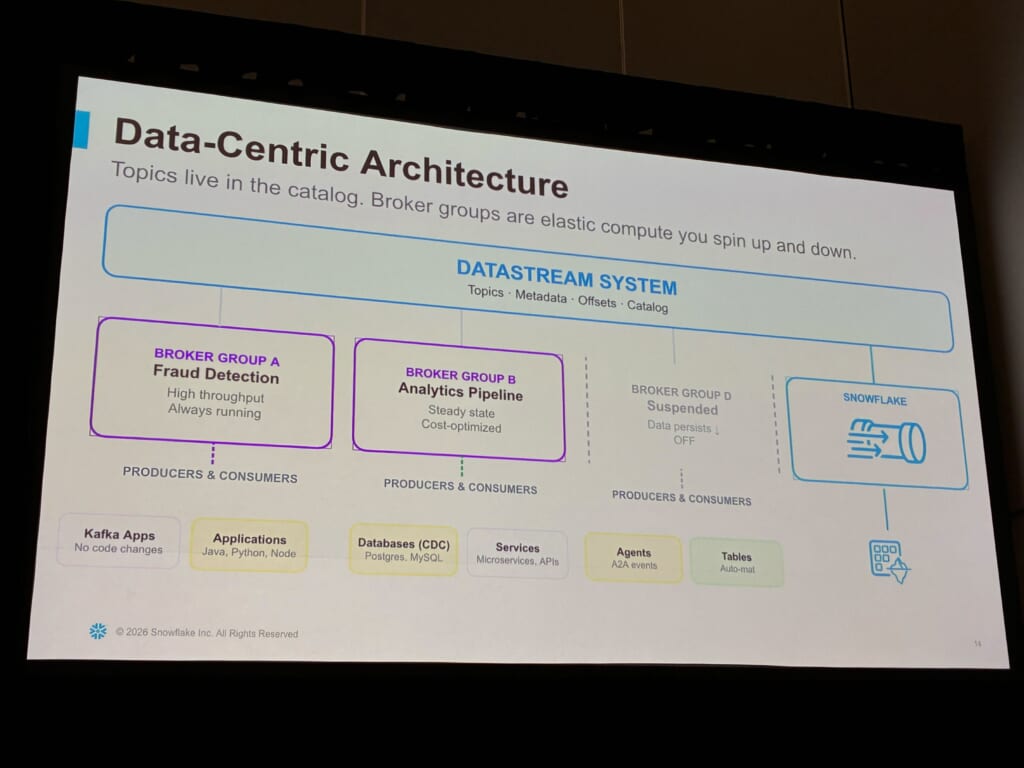
トピックもテーブルも1つのカタログで
DatastreamのトピックはHorizon Catalogに統合され、KafkaトピックとSnowflakeテーブルを、同じカタログで扱えるようになりました。

「このトピックはどこに着地する?」をカタログ内で追跡したり、「パイプラインは新鮮?」をトピックのスループットとテーブルの鮮度を確認したり、「誰がこのストリームを触れる?」をトピックのACLとテーブルの権限で一元的に確認できます。
コネクタや外部ツールが不要で、動くデータと止まっているデータをまとめて扱える点が、メリットとして強調されていました。
ブローカーはStandaloneとManagedの2種類
アーキテクチャも紹介されました。
顧客側のブローカーには、自分の環境で動かすStandaloneとSnowflakeが顧客VPC内で運用するManagedの2種類があります。
Kafkaクライアントはこれらにproduce / consumeし、データはSnowflake側の分析・ストリーミング用ストレージに永続化されます。そこからはSnowpipeで取り込み、ウェアハウスでDMLやDynamic Tables、Streams + Tasks、クエリといった既存の手段で扱えます。
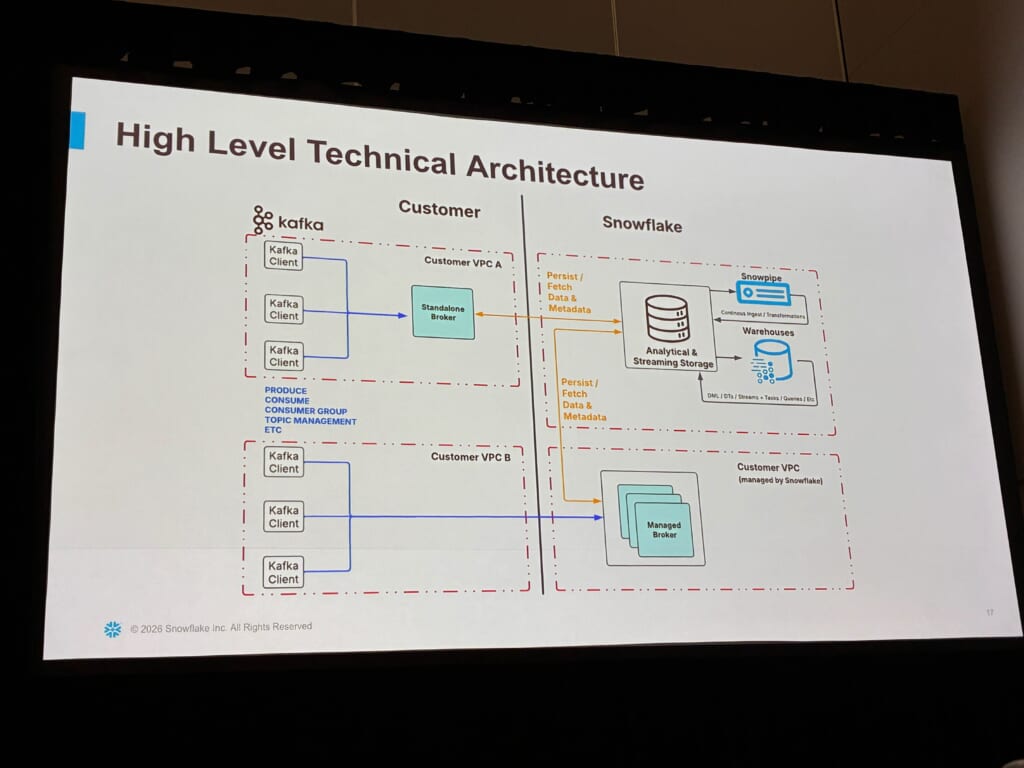
セッション中に補足されていた点として、このブローカーはSnowflakeが独自に開発したもので標準のApache Kafkaそのものではないこと、クラウドストレージに一旦書き込む設計のため、produce / consumeの遅延は100〜200ms程度になることが挙げられていました。超低遅延より、分析基盤の隣に置いて統合することを優先した設計だそうです。
使えるようになるまでもう少し
セッションの最後には、Datastreamの特徴を5点にまとめたスライドが示されました。
- 1.Native and Fully Managed
Snowflakeに最初から組み込まれていて、サーバーの構築・運用・スケーリングはすべてSnowflake任せ。利用する側はインフラの面倒を見なくてよい。 - 2.Kafka Wire Compatible
Wire(プロトコル)レベルで互換なので、既存のKafkaアプリから見ると、コードを書き換えず接続先を変えるだけで繋がる。 - 3.Data-centric Streaming
「サーバーを何台立てるか」ではなく、「どんなデータ(トピック)を扱うか」から考える設計。 - 4.Converged
別々だった「流れるデータ(ストリーム)」と「溜まるデータ(テーブル)」を1つのSnowflakeにまとめ、ガバナンスが単純になる。 - 5.Governed in the Flow
データが流れ込んでくるその瞬間から、アクセス制御やマスキングといったガバナンスが効いている。
さらに締めくくりとして、次の2点が強調されていました。
1点目は「Private Previewが間もなく開始」すること。
2点目は、提供の出発点として、まずはSnowflakeへデータを取り込む方向(topic-to-table、KafkaのtopicをそのままSnowflakeのテーブルとして扱う) という点です。
なお、「リアルタイムのアプリを構築したい場合は、デザインパートナーへどうぞ」と呼びかけられて、本セッションが締めくくられました。
まとめと、今後の続報で注目したい点
「Kafka運用の負担の多くは、クラスタという物理基盤を抱え続けることに由来している」という整理でした。
それを停止・再開できる弾力的な仕組みに置き換え、トピックをデータ資産として(テーブルと同じカタログで)扱う設計は、シンプルで応用が利きそうです。既存のKafkaクライアントを1行で接続できる互換性も導入のハードルを大きく下げると感じました。
そして何より、自然言語(Snowflake CoCo)という入口があることで、Kafka未経験者でも「まず触ってみる」が成立しそうなのが印象的でした。
一方で、本記事の執筆時点では、まだ分からない論点もあります。
- ・100〜200msという遅延がどこまでの用途をカバーするのか
- ・料金体系
- ・GAの時期
- ・ストリームデータを取り込むという意味で、似ているDatastream / Snowpipe Streamingの細かい使い分け
このあたりは続報を待ちたいところです。
Private Previewが始まったら、まずは小さなユースケースの範囲から実際に試してみる価値がありそうです。たとえば、CoCoに頼んでtopic-to-tableのミニマル構成を作るところからかな、と感じています。
このページをシェアする: