Snowflake Summit 2026 最速レポート Day3
CoCoでMLする話

目次
はじめに

DATUM STUDIO データエンジニアリング本部 本部長の菱沼です。Snowflake Summit 2026 3日目のセッション ML204 に参加しました。
「Accelerate and Automate: Mastering Snowflake ML with Snowflake CoCo」と題されたこのセッションは、機械学習エンジニア・データサイエンティスト向けに、CoCoを使ってSnowflake MLの開発から本番運用までを一気通貫で加速・自動化する手法を紹介するものでした。
登壇されたのは、SnowflakeのAI / ML領域を担当するGhazaleh Kazeminejad(Senior AI/ML Architect)さんとCaleb Baechtold(Sr Manager, AI / ML AFE)さんです。

アジェンダは4本立てでした:
- 1.Agentic ML with CoCo — Snowflake ML上でのML開発・運用の加速
- 2.Deploying Production Pipelines(デモ) — Notebook → ML Jobsへの変換
- 3.Managing Production Inference(デモ) — 新バージョンデプロイ・A/Bテスト・シャドウモード
- 4.Art of the Possible — CoCo & MLOpsのこれから
ML担当者の「時間の使い方」が変わる

ML担当者(機械学習エンジニアやデータサイエンティスト)が日々どこに時間を費やしているか、そしてそれがCoCoによってどう変わるか説明がありました。
“60% of time goes into data prep, not modeling or business problem solving”
ML担当者の実力が最も発揮されるべき「判断」に充てられる時間はわずか10%で、残りの90%は段取りと準備に消えています。
Agentic MLがMLワークの構造を変える
CoCoによるAgenticなアプローチによって、これが変化します。
| 作業領域 | 現在の姿 | Agentic Leverage 適用後 |
| Judgment => Steering & Strategy | 10% | 60% |
| Management & Configuration => Workflow Oversight | 30% | 30% |
| Data Wrangling & Prep => Approve | 60% | 10% |
“Focus on business problems, not pipelines and tooling”
データの前処理・環境構築・ボイラープレートコードはCoCoに委譲し、エンジニアはドメイン知識を活かした意思決定と、実験の方向付けに集中できるようになるわけです。
Snowflake CoCo:フルコンテキストで動くMLエージェント

ML業務でCoCoを使う場合に汎用的なコーディングエージェントよりも有利な点として、Snowflakeに統合されていることで、下記のような特徴が挙げられていました。
1. End-to-End ML Automation(エンドツーエンド自動化)
データ前処理・特徴量エンジニアリング・トレーニング・評価・デプロイまで、ML パイプライン全体をML最適化スキルで自動化します。
2. Iterative Reasoning(反復的な推論)
解に素早く到達する、スマートなサジェスチョンを提供します。
3. Multi-Agent Orchestration(マルチエージェントオーケストレーション)
高品質なワークフローを、高速に実行します。
4. Fully Functional Code(実際に動くコード)
セキュアなサンドボックス内でコードを実行し、後続ステップに検証済みのソリューションを渡します。
Snowflakeに備わっている機能を裏側で使い倒す点が、汎用的なコーディングエージェントと比較してやはり有利なんですね(ずるい)。
Snowflake MLプラットフォームとの統合
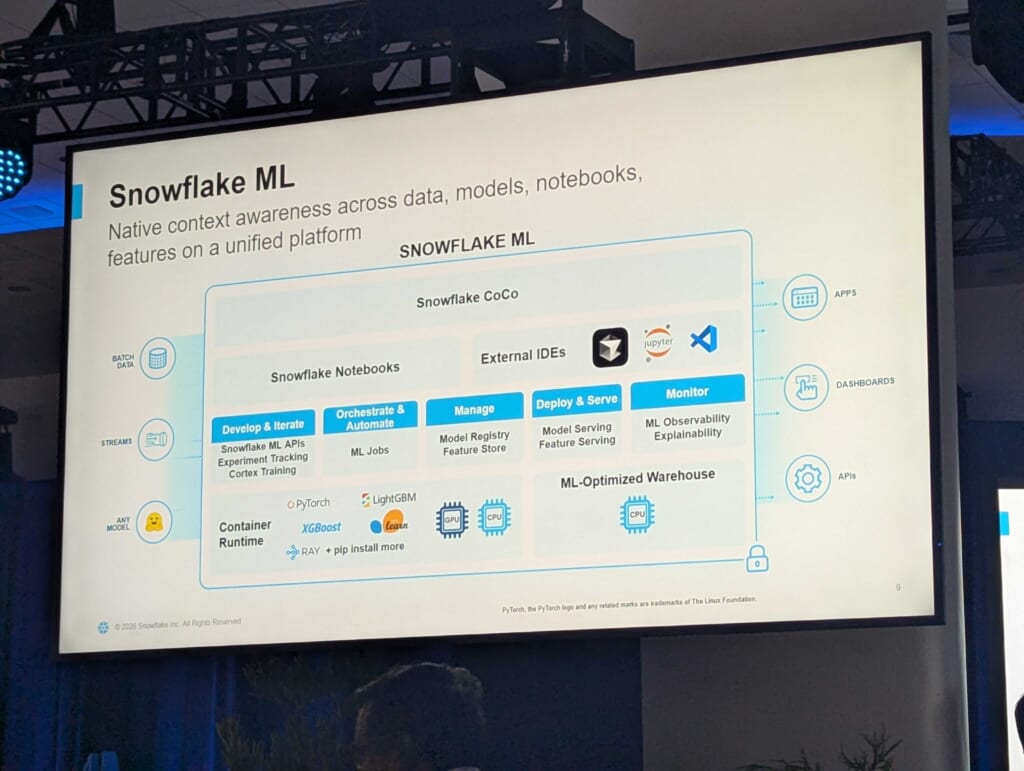
CoCoは Snowflake MLというより広いプラットフォームの上に乗っています。
Snowflake ML(統合プラットフォーム)
├── Snowflake CoCo(AIコーディングエージェント)
│
├── インターフェース
│ ├── Snowflake Notebooks
│ └── External IDEs(Jupyter / VS Code)
│
├── Develop & Iterate
│ ├── Snowflake ML APIs
│ ├── Experiment Tracking
│ └── Cortex Training
│
├── Orchestrate & Automate
│ └── ML Jobs
│
├── Manage
│ ├── Model Registry
│ └── Feature Store
│
├── Deploy & Serve
│ ├── Model Serving
│ └── Feature Serving
│
├── Monitor
│ ├── ML Observability
│ └── Explainability
│
└── Container Runtime
├── PyTorch / LightGBM / XGBoost / scikit-learn / RAY
└── pip Install more
CoCoはこのプラットフォーム上で、データ・モデル・ノートブック・特徴量全体のコンテキストをネイティブに把握した上で動作しています。
CoCo: machine-learning スキル — MLEのための専用スキルアーキテクチャ
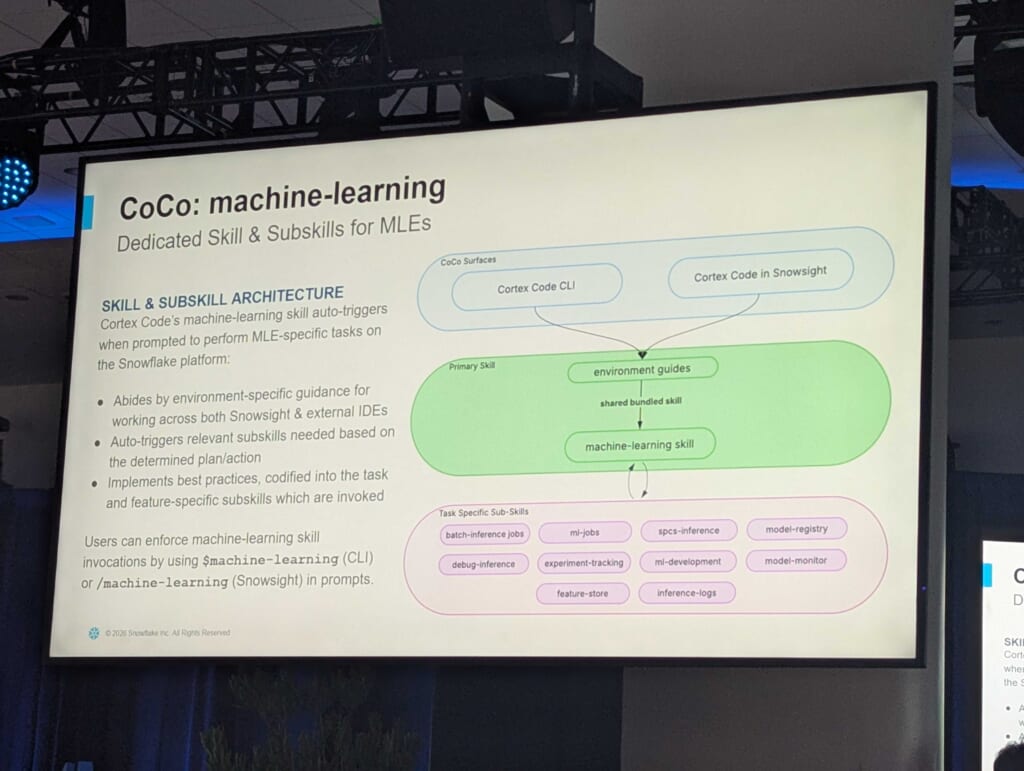
CoCoがML業務をこなせるのは、汎用スキルの上にmachine-learningスキルが備わっているからなんですね。
もちろんこれは、ブラックボックスではなく、一般的なスキルとして作られているので内容が気になったら読み解くことが出来ます。
もし、作業者自身がML業務用のスキルを所有している場合は比較してみても良いかも知れません。
アーキテクチャ:
CoCo Surfaces
├── Cortex Code CLI
└── Cortex Code in Snowsight
↓
Primary Skill
├── environment guides(Snowsight・外部IDEの環境ガイド)
│ ↓ shared bundled skill
└── machine-learning skill(MLEのためのベストプラクティスを内包)
↓
Task Specific Sub-Skills(タスク特化サブスキル)
├── batch-inference jobs ├── ml-jobs
├── spcs-inference ├── model-registry
├── debug-inference ├── experiment-tracking
├── ml-development ├── model-monitor
├── feature-store └── inference-logs
machine-learningスキルを呼び出す方法は、主に次の2つです。
- ・CLI: $machine-learning をプロンプトに含める
- ・Snowsight: /machine-learning をプロンプトに含める
是非、ご自身の環境で起動してみてください。
デモ(1):ノートブックから本番パイプラインへ

MLの現場でよくある課題の1つが「実験用ノートブックを本番環境に持っていけない」問題です。この問題がそのままデモのテーマとして紹介されました。
CoCoによる変換フロー:
Experimentation
Snowflake Notebook(Container Runtime)
↓ CoCo Converts
Refactor & Generate Pipeline Code
↓ submit_directory()
Production Pipeline
Task Graph(Scheduled DAG)→ ML Job(Compute Pool)→ Model Registry(Versioned)
CoCoへのプロンプト例と結果:
| ML実務者がやりたいこと | CoCoへの指示 | CoCoが生成するもの |
| ノートブックをモジュール型Pythonにリファクタ | “Convert this notebook into an ML Job with separate data_prep, train, and eval modules” | モジュール分割されたML Jobコード |
| コンピュート(GPU / CPU)の設定 | “Submit this as an ML Job on my GPU compute pool” | submit_directory() + compute pool config |
| メトリクス付きモデル登録 | “Log this model to the registry with accuracy and F1 metrics” | Registry.log_model() の呼び出し |
| スケジュール付きトレーニングDAG構築 | “Create a Task Graph that runs this training pipeline daily” | DAGTask定義 + dag.py |
| 実験トラッキングの追加 | “Track this training run as an experiment” | Snowflake Experiments の組み込み |
次の4つのベストプラクティスも紹介されていました。
- ・Start with a working notebook —
CoCoはランナブルなコードをリストラクチャする必要がある - ・Be specific in prompts —
欲しいモジュール名(data_prep, train, eval)を明示する - ・Let CoCo handle boilerplate —
compute pool config・stage uploads・DAG wiringはCoCoに任せる - ・Review before deploying —
compute poolのサイジングとスケジュールは必ずレビュー
デモ(2):安全なモデルロールアウト

新しいモデルバージョンを本番に安全に適用する際の手順をCoCoがどう支援するか、が2つ目のデモのテーマでした。
自分で構文を1から調べて実装作業するのは大変ですよね…。モデルのカナリアリリースとか…。
ロールアウトアーキテクチャ:
Model Registry
├── Model V1(Production)
└── Model V2(Candidate)
↓
Model Serving
├── Service V1(SPCS Endpoint)
└── Service V2(SPCS Endpoint)
↓
Snowflake Gateway
トラフィック分割: 90/10 → 50/50 → 0/100
↓
ML Observability
├── Drift + Performance Monitors
└── Version Comparison Dashboard
CoCoへのプロンプト例と生成されるコード:
| 操作 | プロンプト | CoCoが生成するもの |
| モデルをエンドポイントとしてデプロイ | “Deploy model v2 as a real-time serving endpoint” | mv.create_service() |
| カナリアトラフィック分割設定 | “Create a gateway splitting 90% to v1 and 10% to v2” | CREATE GATEWAY SQL |
| 両バージョンの監視設定 | “Set up observability monitors for both model versions” | CREATE MODEL MONITOR |
| ドリフト・精度の比較 | “Compare drift and accuracy between v1 and v2” | MODEL_MONITOR_DRIFT_METRIC() / MODEL_MONITOR_PERFORMANCE_METRIC() |
| トラフィック切り替え / ロールバック | “Shift all traffic to v2” / “Rollback to v1” | ALTER GATEWAY |
こちらのデモでもベストプラクティスが紹介されていました…。(きれいに動くようになるまで、試行錯誤されたんだろうなぁ。)
- ・Deploy both versions first — v1とv2を別々のサービスとしてデプロイしてから切り替える
- ・Use Gateway for safe rollout — 90/10から開始し、CoCoがSQLを生成
- ・Monitor before promoting — バージョン間のドリフトとパフォーマンスをCoCoに比較させる
- ・Iterate conversationally — “Shift to 50/50” → “Promote v2 to 100%” → “Drop v1 service” と会話で進める
プランニングモード:最大20倍の速度向上
汎用的なコーディングエージェント同様に、セッションで強調されていたのはPlanning Mode(プランニングモード)の活用です。このあたりはClaude Codeを日常的に使ってる人たちにとっては、当たり前っちゃ当たり前ですね。
通常モードではCoCoがいきなりコードを生成しますが、プランニングモードを有効にすると「まず計画を提示してから実行する」フローになります。
効果:
- ・計画を先に確認・修正できるため、手戻りが大幅に減少
- ・通常実行と比較して最大20倍の速度向上
使い方:
プロンプトの先頭や末尾に「プランを立ててから実行して」と指示することで有効になります。計画が表示されたら、気になる部分を修正してから実行に進みます。
これはデモ(1)の場面で実際に示されており、ジョブ構成の選択画面がその「計画確認ステップ」にあたります。
Agentic MLOps:CoCoによって、どう楽になるの?

セッションの締めくくりとして、CoCoがMLライフサイクル全体をどのように変えるかが整理されました。
フェーズ 1: Development & Iteration(開発・反復)
- ・自然言語で、NotebooksやIDEにコードを記述
- ・自動化されたEDA(探索的データ分析)と特徴量エンジニアリング
- ・ハイパーパラメータの推奨とチューニング
- ・コンテキストを理解したデバッグと最適化
フェーズ 2: Pipeline Automation(パイプライン自動化)
- ・研究用ノートブックのモジュールリファクタリング
- ・Task Graphs(DAG)の自動生成
- ・Compute Poolsへのシームレスなデプロイ
- ・Infrastructure-as-Code(IaC)の生成
フェーズ 3: Deployment & Serving(デプロイ・サービング)
- ・シャドウモードとA/Bテストの自動セットアップ
- ・トラフィック分割とカナリアデプロイ
- ・Model Registryによるバージョン管理
- ・リアルタイム・バッチ推論の最適化
フェーズ 4: Observability & Governance(可観測性・ガバナンス)
- ・ドリフト・パフォーマンスモニターの設定
- ・障害の自動根本原因分析
- ・データからモデルまでのリネージ追跡
- ・継続的なフィードバックと再トレーニングループ
セッションでは、ビジネス上の影響として次のように語られていました。
Business Impact:
CoCo empowers teams to focus on solving business problems rather than managing tooling and pipelines.
(CoCo はチームがツールやパイプラインの管理よりも、ビジネス上の問題解決に集中してもらえるようパワーを与える)
CoCo、めっちゃ良いですね。
まとめ:安全に進めるためのベストプラクティス
セッション全体を通じて繰り返し強調していたのは「AIエージェントを信頼しつつも、人間のレビューを外さない」という点です。
- 1.動くノートブックから始める —
リファクタリング前にコードが正常動作していることを確認する - 2.プロンプトを具体的かつ処方的に —
モジュール名・ファイル名・スキーマ名など、詳細を与えるほど精度が上がる - 3.プランニングモードを活用 —
コード生成前に計画を確認・修正することで、手戻りを防ぐ - 4.小サンプルで検証してから本番へ —
全データに適用する前に、小規模データセットでコードを動作確認する - 5.DML・ML変更は慎重にレビュー —
モデル変更やデータ操作言語の変更は、特にセンシティブ。CoCoが変更を加える前に必ず確認する - 6.コンピュートリソースを監視する —
割り当てられたコンピュートが、用途に対して過剰でないかモニタリングする
所感
このセッションで最も印象に残ったのは「ML実務者の時間配分を逆転させる」というビジョンの明確さです。
60%を占める前処理・環境構築をCoCoに委譲し、ドメイン知識が活きる判断とステアリングに60%を使えるようになるという構造変化は、単なる「効率化」ではなく、「仕事の質的転換」です。
Notebook → ML Job変換のデモは、特に実用的でした。手書きのシングルファイルノートブックを7モジュールのプロダクション対応パイプラインに変換する一連の流れを、自然言語の指示だけで進められる様子は、MLエンジニアにとって「これは使える」と感じる場面でした。
一方、セッション中も強調されていたとおり、DML変更やモデルデプロイなど影響範囲の大きい操作については、人間のレビューを必ず挟むという、ガードレールの文化を組織として定着させることが、Agentic MLを安全に運用するための前提条件になります。
最後のガードレール部分については、LLMの性能向上によって、徐々に改善されていく領域かとは思いつつ、今すぐ使うような先進的な組織では、人と文化の面で気を配っていく必要がありそうです。
このページをシェアする: