Snowflake Summit 2026 参加レポート Day1
【セッション解説】 韓国食品会社で行われている
個人の経験やノウハウを活かしたSnowflake Intelligenceでの自律的なデータ分析事例

はじめに
こんにちは。DATUM STUDIOの山口です。
現在、サンフランシスコにて開催されている、Snowflake Summit2026に参加しております!
昨日は、Snowflake Data Superhero&Streamlit Creatorsのネットワーキングイベントに、Streamlit Creatorとして出席しました。
普段、大変お世話になっているStreamlit Creatorsのコミュニティマネージャーの方や、海外のData Superheroと直接お話しできる貴重な機会で、とても良い経験をさせていただきました。
Snowflake Summitのために3年ほど英語の勉強を継続してきたので、一人で何名かの方に英語で話しかけるチャレンジをしました。


本日は、Snowflake Summit 2026で聴講したセッション「The Blueprint for Building SCM Intelligence for Perishable Business on Snowflake」についてのレポートをお届けします。
私は現在、小売業のお客さまと一緒にお仕事をさせていただいているのですが、プロジェクトで活用できるヒントが得られないかと思い、このセッションを選びました。
登壇されたのは、韓国の食品メーカーSCM(サプライチェーン・マネジメント)チームに在籍し、コンサルタントとして15年以上の経験を持つ方でした。
「AIとデータを使ってSCMの現場をどう変えるか」という、実務に根ざしたテーマで、Snowflakeを活用した「知識誘導型AIエージェント」の設計思想と、具体的な導入事例が語られました。
SCMが抱える構造的な課題
登壇者の会社は韓国発のグローバル食品メーカーで、海外に複数の工場・営業拠点を持っています。
その分コストが高く、マージンが限られているとのことでした。
SCM領域の課題として挙げられていたのは、主に次の3点です。
- 1.需要予測が外れると在庫に直結し、食品特有の賞味期限管理が収益を圧迫する
- 2.在庫の値下げが必要になると、売上・利益の両面に悪影響が出る
- 3.SCM専門の人材が採用しづらく、グローバル展開のためのトレーニングコストも高い
実際、2年かけてグローバル対応のシステム導入とチームの再教育を行ったにもかかわらず、担当者が離職するたびに「ゼロからやり直し」になってしまうという、苦い経験も語られていました。

AIに正しく動いてもらうためのデータ設計
知識誘導型エージェントを語る前に、登壇者が強調していたのが「AIが使うデータの設計」です。
- ・異なる粒度のデータを混在させない(粒度が揃っていないデータは、AIを混乱させる)
- ・KPIや業務指標は、あらかじめビューやダイナミックテーブルとして定義しておく
- ・AIに巨大なSQLを生成させない(SQLが大きくなるほど、ミスが増える)
KPIや在庫日数などのビジネス指標を、Snowflakeのビューとして事前に定義しておくことで、AIはデータを「読んで分析する」役割に集中できます。
知識をエージェントに組み込む方法
このセッションで最も印象的だったのが、「知識誘導型エージェント(Knowledge-Guided Agent)」の設計思想です。
従来型のAIエージェント(登壇者は「応答機」と表現していました)では、担当者が以前からSQLやBIで行っていた質問をAIに置き換えるだけになりがちです。ツールが変わっても、分析の質は変わりません。
そこで登壇者が取り組んだのが、業務ノウハウをエージェントに組み込むことでした。具体的なプロセスは次のとおりです。
- ・15年以上のコンサルティング経験をもとに、現地従業員へのインタビューを実施
- ・「何をどの順で分析するか」「業務用語の定義と関係性」「用語の分類体系」を文書として整理する
- ・その知識をSnowflakeに格納し、Cortex Search(RAG)を通じて、Cortex Agentから参照できるようにする
こうして構築された知識が「どこを分析するか」「次に何を分析するか」をエージェントに判断させる仕組みになっており、ナレッジガイドによってエージェントが、様々なビジネス状況に柔軟に対応できるようになります。
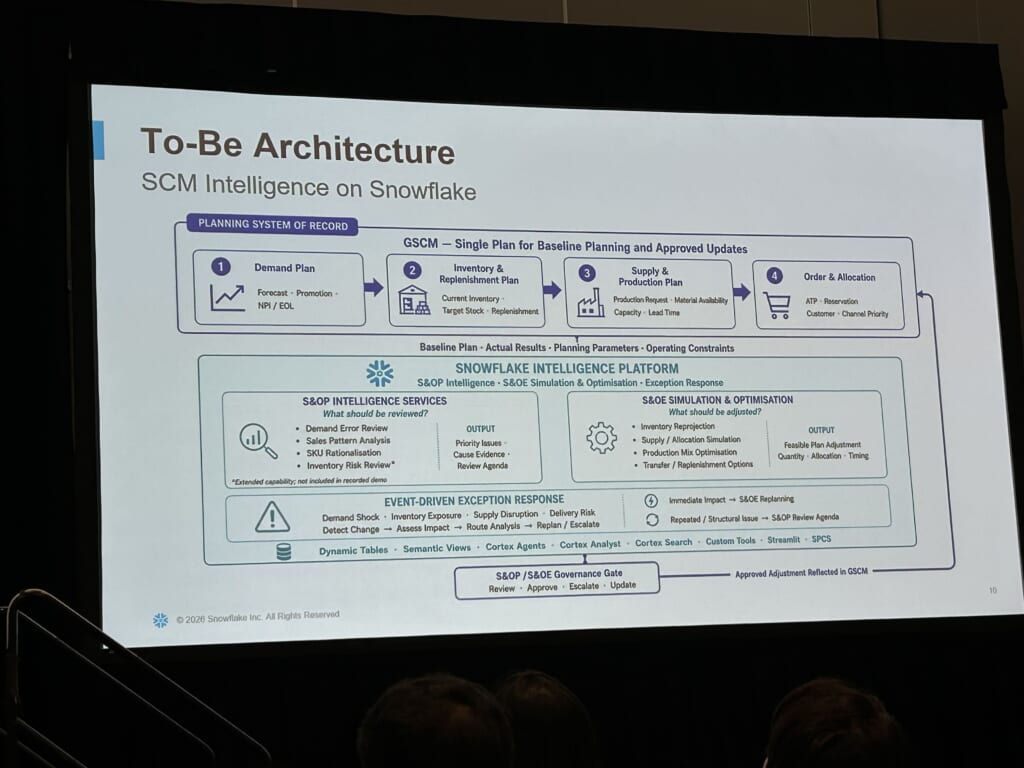

実務での活用事例
このアーキテクチャをベースにした活用事例が、2つ紹介されました。
1:SKU合理化分析
利益低下シグナルの検知 → コスト構造の分解 → 売上パターン分析 → 在庫確認 → P&Lシミュレーションという一連の分析を、複数のエージェントが連携して自動実行します。
P&L分析の専門家がいなかったチームメンバーが、エージェントから自律的に学びながらSKU担当として独り立ちした、という話が印象的でした。
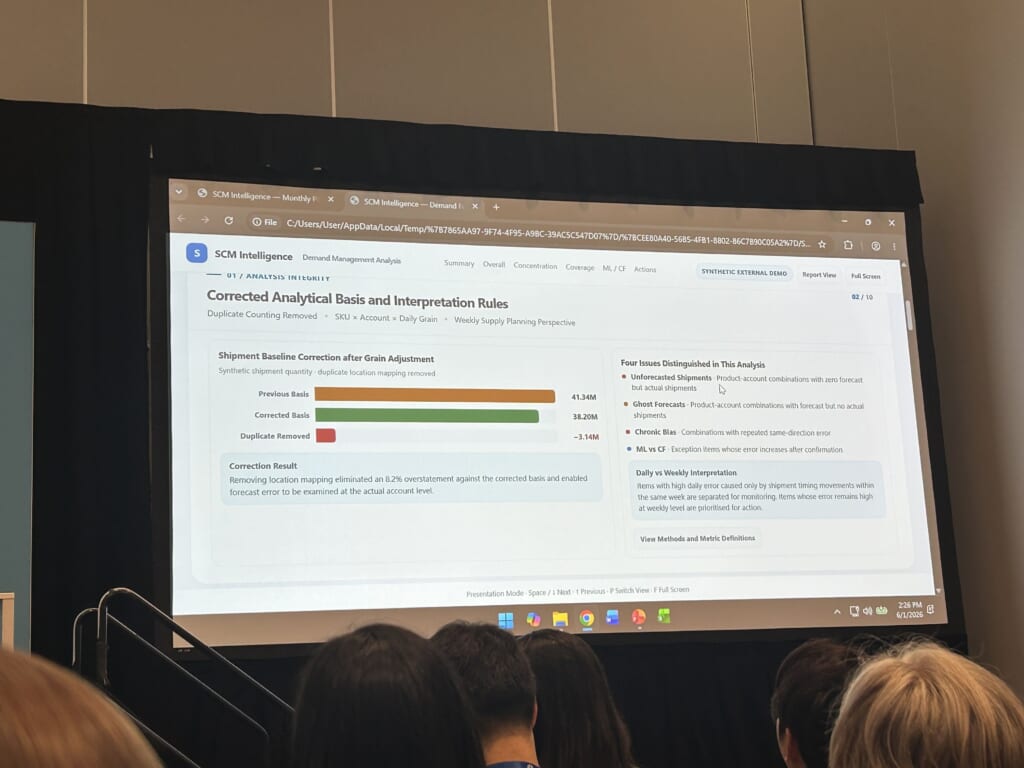
2:需要予測エラー分析
従来は1か月以上かかっていた分析が、AIで1分以内に完了します。予測データが存在しない、実績データが存在しない、慢性的なバイアスがあるなど、複数の異常パターンを自動で検出し、対応の優先度を示してくれます。
なお、エージェントが生成した分析レポートは、HTML形式で出力されるようにしているとのことで、レポートの自動生成から出力までの一連のフローが完結していました。
まとめ
このセッションでは、「Cortex Search上に経験やノウハウを文書として蓄積し、Cortex Agentがそれを参照しながら分析の順序を自律的に判断する」というアーキテクチャを構築している最新事例について学ぶことができました。
Cortex Analystを活用したText-to-SQLやCortex Searchを活用したテキスト検索の次のステップを模索し、お客さまの業務に活用できるか気になっていたところで、「こういうことを知りたかった」という内容を知ることができ、このセッションを聴講してよかったなと思いました。
明日からも皆さんのお役に立てるグローバルの最新事例や新機能を発信していきます!
このページをシェアする: