Snowflake Summit 2026 最速レポート Day1
【セッション解説】 Snowflake パイプラインの
浪費を測る9つの指標

目次
はじめまして、DATUM STUDIOの鈴木です。
現在、サンフランシスコで開催中のSnowflake Summit 2026に参加しています。
現地では、様々な企業がSnowflakeを活用した自社の取り組みについて、セッションでプレゼンする場が設けられています。
その中でも今回は、KeeboのMike Scherer氏によるセッション「Messy Pipelines Are Expensive: A Hygiene Framework for Cutting Snowflake Waste」(DE210)を聴講してきましたのでご紹介します。
本記事では、きれいに組んだはずのパイプラインに潜むコストの無駄をどう見つけるか、という同セッションの内容について解説します。
なぜ、きれいなパイプラインがコストを溶かすのか?
セッションは「The Modern Data Paradox」というスライドから始まりました。「パイプラインを作る技術は成熟した。だが今、私たちはその“成功の税金(Success Tax)”を払っている」というメッセージとともに、4つの数字が並びます。
パイプライン衛生の不備による年間平均損失が$12.9M、監視されていないパイプラインにより総収益の31%に悪影響が及んでいる、パイプラインの保守・クリーンアップに毎週55時間奪われる、新規レコードの半分に少なくとも1つの重大なエラーが含まれることが示されました。
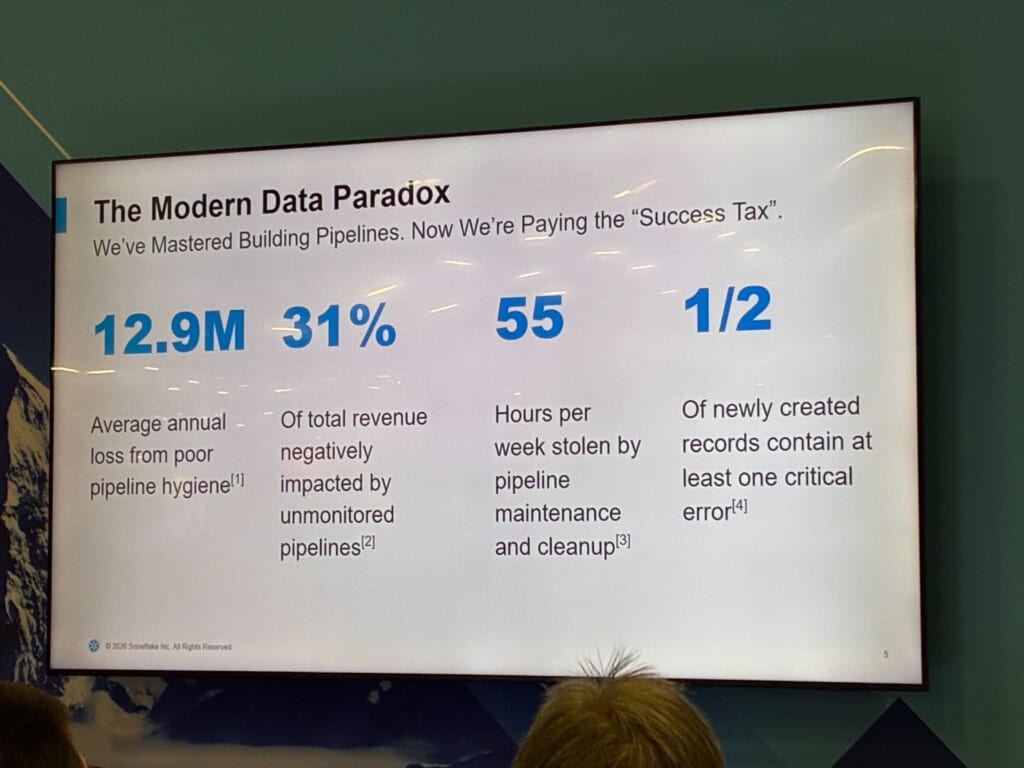
[1] Gartner, “Dirty Data Tax $12.9M”.
Gartner「Magic Quadrant for Data Quality Solutions」(2020年、Chien & Jain) 。データ品質管理ツールを既に購入している大企業の参照顧客154社への調査。
[2] Monte Carlo, “Revenue Risk (31% Impact)”.
Wakefield Research の年次 State of Data Quality 調査 (データ専門家200名、2023年3月) 。影響を受ける売上の平均が26%から31%へ上昇。
[3] Forbes, “The Maintenance Trap (55 Hours/Week)”.
「データ準備が時間の大半を食う」という 80/20 (パレートの法則) の通説。
[4] Harvard Business Review, “The Error Baseline (47% Error Rate)”.
企業のデータのうち、新規レコードの47%に1つ以上の重大エラー、基本的な品質基準を満たしているのはわずか3%である、という重大な業務上のギャップを明らかにしている研究。
なぜ、こうなるのか?ですが、dbtをはじめとするツールは、コードの構造やデータの流れを可視化してくれます。しかし「そのクエリが、本番でいくら使っているか」までは見えません。
表面上は順調でも、内部の不調が静かに進行して気づいたときには手遅れになる。AIがコードを量産する今、この傾向はますます強まっています。
浪費を断つ4つのステップ
Mike氏は、コスト削減を一度きりのイベントではなく、繰り返し回せるプロセスとして捉えるべきと主張します。その枠組みが、Identification(特定) → Prioritization(優先順位付け)→ Optimization(最適化)→ Enforcement(徹底)の4ステップです。各段階は前の段階に依存し、特定なしに優先順位は決まらず、優先順位なしに最適化は機能しません。

最大の難関であり、同時に最も重要だと強調するのが、最後のEnforcementです。
「『あなたのパイプラインは無駄が多い』と同僚に指摘して回るのは気まずく、楽しくない。これは、技術ではなく組織文化の問題であり、ミスを許容しそこから回復できる文化があって、初めて回り続ける」というのが、Mike氏からのメッセージでした。
では、その起点となるIdentificationを、具体的に何で測るのか。
セッションでは浪費を測る9つの指標が、3つの群に分けて示されました。各群の全指標を挙げつつ、それぞれ代表的な1つを掘り下げます。
浪費を測る指標群(1)ROI : そのパイプラインは投資に見合うか
- ・Ancestry Cost Multiplier : 1つの出力を生む際、上流全体でいくらかかっているか
- ・Zombie Model : 長期間アクセスのないモデル = 削除候補
- ・Duplicated Query : 複数のDAGで重複実行されるSQL = マテリアライズ候補
Zombie Modelを掘り下げると、あるモデルがどの程度の頻度でアクセスされているかを測る指標です。
Mike氏は「30日を超えてアクセスがなければ、おそらく削除してよい」と述べ、QUERY_HISTORYとACCESS_HISTORYを突き合わせて、他のモデルと比較することで洗い出せると説明しました。

浪費を測る指標群(2)クレジット流出 : 無駄に溶けている消費
- ・The Scanning Efficiency Ratio : 不要なパーティションスキャンや、効いていないJOIN
- ・The Small File Problem : auto-clusteringの不調(スキャン増・ストレージ増を招く)
- ・Model Cost Variance : コストのばらつき。隠れた上流依存や不安定なワークロードの兆候
Model Cost Varianceは、ワークロードがどれだけ予測可能かを示す指標です。
Mike氏によれば、分散が大きいほどワークロードは不安定・予測不能で、その背後には隠れた上流依存が潜んでいる可能性が高いとのこと。結果として、Data Freshnessの問題、ウェアハウスのメモリ問題、ウェアハウスの競合が起きているかもしれない、と述べました。

浪費を測る指標群(3)衛生 : 運用設定の最適化
- ・Idle Warehousing / Auto-suspend : アイドル課金とcold startのバランス調整
- ・Idle-to-Peak Ratio : ピーク時と通常処理時のサイジングの乖離
- ・Engineering Deployment : 保守・クリーンアップの雑務に優秀なエンジニアの時間を費やしていないか
Engineering Deploymentは、他と少し毛色が違います。保守やクリーンアップといった雑務に、優秀なエンジニアの時間を溶かしていないか。インフラではなく「人のコスト」に目を向けた指標です。
こちらは、Mike氏が「ディレクターとして、最も思い入れがある」と語っていました。曰く、多くのエンジニアはパイプラインの保守やデータのクリーンアップに時間を費やしたくはなく、ビジネスを動かすインパクトのあるクエリや機能に取り組みたいもの。こうした雑務に埋もれさせることは、Aクラスの人材を失う格好の方法であり、だからこそそういった人材を引き留め、時間が正しく使われるようにすべきだ、と締めくくりました。

まとめ
Mike氏が強調していたのは、「これらの指標は単体ではなく、組み合わせて初めてROIの全体像が見える」ということでした。
そして、こうした特定と改善を一度きりで終わらせず、自動化・自律化によって継続的に回し続けることを勧めていました。
普段、運用をメインに担当している身としては、コストを抑えるための観点をこれだけ具体的に持ち帰れたことが、自分の業務にダイレクトに活かせそうで大きな収穫でした。まずは、自分が見ているパイプラインから確認してみようと思います。
Snowflake Summit 2026は、まだ1日目です。明日以降も気になるセッションやブースに足を運び、そこで得た学びをご紹介していく予定です。
引き続き、お付き合いいただけたら嬉しいです。
このページをシェアする: