
概要
三井物産流通グループ株式会社(以下、三井物産流通グループ)は、三井物産株式会社の100%出資子会社として食品・日用品物流の高度化および中間流通機能を担う企業です。2024年に持株会社1社と事業会社4社が統合し、誕生しました。
各社に蓄積された豊富なノウハウとネットワークを活かし、卸売・物流・情報サービスを中心にサプライチェーン全体の最適化を推進しています。さらに、デジタル技術の活用によるフードロス削減など、新たな価値創出にも取り組んでいます。
日本の流通システムを支える同社が扱うデータ量は膨大であり、関連会社やパートナー企業とのデータ連携が不可欠です。
しかし、従来のシステムは外部委託によって開発されていたため開発効率が低く、業務の標準化やデータの一元管理が困難な状況にありました。
そこで同社はSnowflakeを活用した「データ処理基盤」の構築を決断。商品の受発注や請求、会計、倉庫間の在庫移動など、1日あたり数千万件にのぼる膨大なトランザクションデータをSnowflakeでいかに効率的に処理するかが鍵となりました。
三井物産流通グループが進める日本最大級の流通基盤リプレイスプロジェクトにおいて、DATUM STUDIOがSnowflakeを活用したデータ処理基盤の構築を支援した事例をご紹介します。
課題
三井物産流通グループでは、業務の標準化やデータ統合の面で次のような課題を抱えていました。
1.ウォーターフォール型開発による非効率性
従来のシステム構築は開発行程を上から下へ進める「ウォーターフォール型」を採用していたため、工程やスケジュールを明確にして進めるので管理しやすい一方で途中の仕様変更時には前工程に戻って修正する必要があり、コストの肥大や納期遅延といった課題が生じていました。
そのような状況から業務部門・IT部門・開発ベンダー間での認識齟齬や手戻り、開発効率の低下を招いていました。
2.データ連携の煩雑さと標準化の遅れ
三井物産流通グループの取引先企業は広範な企業ネットワークを有しており、毎日様々な企業からファイルデータが取り込まれます。しかしながら流通業界においては、データをメールで送付することや取引先から三者三様の独自フォーマットを用いてデータがインターフェースされることが多く、データの一元管理や標準化が困難な状況にありました。
3.属人化・EUC乱立による業務品質のばらつき
システムが出力したデータに対して現場担当者の主観や知見に基づいた修正を加えることが多く、その作業を効率的に行うためのマクロやRPAなどのEUC(エンドユーザーコンピューティング)が点在していました。結果として、業務品質のばらつきと属人化が課題となっていました。
Snowflakeを採用した理由と具体的な取り組み
膨大かつ多様なデータを安定的かつ効率的に処理するため、三井物産流通グループは高いスケーラビリティとパフォーマンスを誇るSnowflakeを採用しました。
分析を目的とした「データ分析基盤」ではなく膨大なデータ処理を実現する「データ処理基盤」を構築することで、業務の標準化とリアルタイムなデータ連携を実現することが目的です。
プロジェクトの特徴
本プロジェクトの推進にあたっては、従来のウォーターフォール型に代わり「アジャイル型」を採用しました。小さな単位で開発・テスト・改善を繰り返すことで、仕様変更にも柔軟に対応できるのが特徴です。
チームは1チームあたり約10名で構成され、現在は約70名体制で推進しています。業務部門主体のチーム構成で、現場視点を積極的に取り入れることを重視しています。
また、四半期に一度のペースでプロジェクトメンバーが集まり、先3カ月の計画を約3日間かけてディスカッションします。エンジニアとビジネス職が定期的に顔をあわせて対話を重ねるスタイルこそが、現場に本当に必要とされる機能を的確に開発できた成功要因の一つとなりました。
技術面でのポイント

1.Snowflakeをハブとした、データ連携アーキテクチャ
上図のとおりSnowflakeを中心(ハブ)に据え、EDI・Streamlit・Dynamics365・kintoneなど様々なクラウドサービスを疎結合な構成で連携しています。すべてのデータをまずSnowflakeに集約して統一フォーマットで処理することで、業務の標準化と高い拡張性を実現しました。
また、既にSnowflakeを導入している取引先企業とはデータシェアリングを通じて、双方のデータをリアルタイムで同期することも可能になりました。
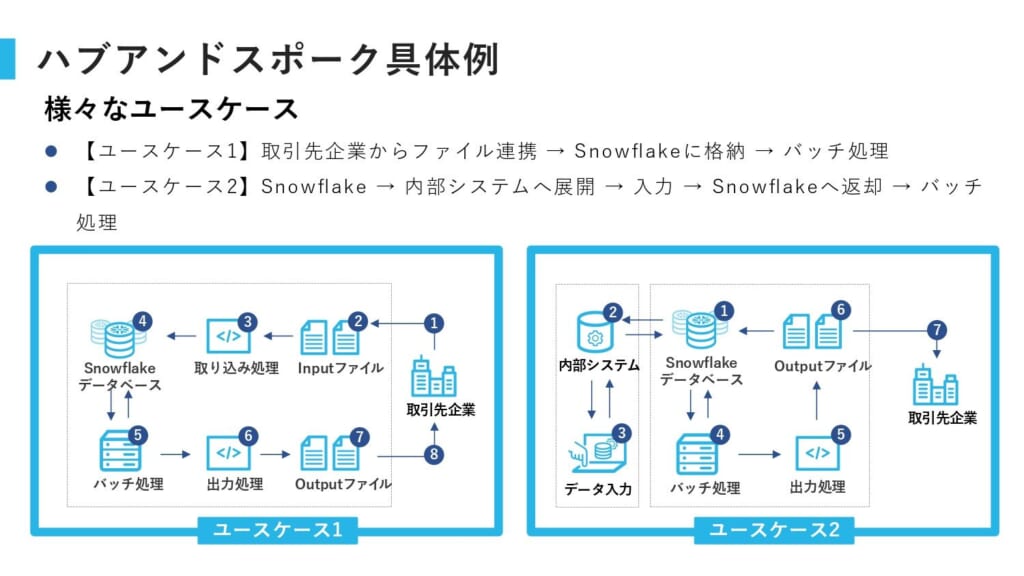
2.大量のデータ処理を安定化・高速化
三井物産流通グループは広範な企業ネットワークを有しており、各社から毎日ファイルデータが取り込まれます。本プロジェクトではユースケースごとに最適な構築を設計しました。
- ユースケース1(シンプルなケース)
「どの商品がどの倉庫にあり、どの倉庫会社の拠点にあるか」といった情報を各社から受け取り、それらのデータを一度すべてSnowflakeに取り込み、他のデータとマージしてバッチ処理を実行。処理後に自社の最新状態を出力して関連企業と情報を同期させる仕組みです。
この「取引先の状態を取り込み、更新し、その結果を返す」というサイクルを通じて、膨大な関連企業のデータを常に同期しています。 - ユースケース2(発展的なケース)
周辺の各システムが非同期的に動作し、裏側でデータの入力・加工、Snowflakeへの書き込み・読み取りなどの処理をリアルタイムかつ非同期で実行しています。
これらの仕組みを支えているのが、Snowflakeの圧倒的なパフォーマンスです。
5秒ごとに5万レコードを含む外部ファイルが連携され(1時間あたり約400ファイル、計2,000万レコード相当)、Snowflakeではこれらを安定的かつスケーラブルに処理することが可能です。
安定稼働を維持しながら倍のデータ量にも対応できる拡張設計を実現しており、必要に応じて同じアーキテクチャのまま、コンピューティングリソースを複製するだけで即時スケールアウトできます。
3.「ループを排除した」高効率SQL処理
この仕組みを実現するうえで鍵となったのが「ループを完全に排除した実装」です。
一般的に大規模データを扱うプログラムではデータを一括で取得したあとに1行ずつ順次処理するループ構造が採用されますが、本プロジェクトではそのループをすべて排除し、処理をSnowflakeに全面的に委ねるアプローチを取りました。
すべての処理をSQLベースで記述した結果、Snowflakeの分散並列処理能力を最大限に活用できるようになりました。
また、Snowparkを活用することでSQLだけでは書きにくい複雑なロジックや前処理も、シンプルかつ柔軟に実装することが可能となりました。
成果
今回のプロジェクトを通じて、同社では特に二つの成果を実感しています。
1.データ活用に対する社員のマインド変化
アジャイル開発による内製化に取り組んだ結果、業務部門の社員の「システムに対する捉え方」が大きく変化しました。これまでの「業務とシステムが分断された状態」から「ビジネスにシステムをフィットさせていく」という考え方にシフトしたことで自ら要件定義を行い、必要なデータを抽出してデータを主体的に扱うマインドが定着しつつあります。
この変化の延長線上に業務の標準化・効率化・省人化の実現があると考え、現在も継続して取り組みを進めています。
2.Snowflakeを活用したデータ活用基盤の進化
今回リプレイスした需給管理システムの中で、最もコアとなるのが需要予測(デマンドフォーキャスト)です。
リプレイス後はSnowflakeにデータを集約してチーム全体で共有できる「共通の資産」としてデータを扱えるようになり、結果としてMLOpsによる実験や開発も可能となりました。
MLOpsはエンジニアが構築できる仕組みではあるものの、それだけではビジネスの成長に直結する価値を生み出すことはできません。MLモデルから出力される予測値はサプライチェーンの下流側、つまり「小売店でどの商品がいくつ売れるか」という領域が中心です。
一方で同社の需要予測の目的は上流側、すなわちメーカーに「どれだけ発注・生産を依頼するか」という意思決定と継続的な精度向上です。そのため、在庫データやトラックの稼働状況など物流データと突き合わせ、予測値を「ビジネスで活用できる形」に加工しています。この加工ロジックは、現場で働く社員のノウハウや経験が不可欠であるため、内製開発のみで実現しています。
現在はSnowflake上で処理途中のデータまで共有・可視化されており、業務部門とエンジニアが協働しながらロジックを改善できるようになりました。試行錯誤しながら継続的にアップデートしていける環境が整ったことは、ビジネスの成長を加速させる上で大きな一歩となりました。
今後の展望
三井物産流通グループでは、中長期的な目標として「データドリブン経営」を掲げています。
本プロジェクトで培ったモダンアーキテクチャと内製開発の知見を活かし、データを扱うスキルを持つ人材の育成をさらに加速していく方針です。また、Snowflakeを中心としたデータ基盤をベースに標準化・効率化・自動化を一層推進し、業務改善のスピードと精度を高めていく考えです。
将来的には本プロジェクトで構築した仕組みを他事業にも展開し、外部パートナーとの共創やサービス化を通じて次世代の流通モデルの実現を目指します。
DATUM STUDIOのケイパビリティ
DATUM STUDIOはSnowflakeをはじめとするクラウドプラットフォームを活用し、データ基盤の設計・構築から、データ分析、AI実装、DX推進の支援まで一気通貫でご支援します。
要件整理から技術選定、アジャイル開発の導入支援など、クライアントの課題に合わせて成果につながるデータ基盤の構築と利活用を伴走型で実現します。
SnowflakeのAI Data Cloud Servicesパートナーとして豊富な実績を持つ弊社では、データエンジニアリング・AI・クラウド運用の専門チームが連携し、クライアントの「データドリブン経営」の実現に向けて最適なソリューションをご提案します。










