TwitterAPIを用いたクローラー作成

こんにちは。データ事業部2部の安部健太郎です。
今回は、Twitterのクローラー作成についてお話したいと思います。
Twitterのクローラーに関しては、サイトをそのままクローリングすることも技術的には可能ですが、TwitterはAPIを提供しているため、本記事ではAPIを使ったクローリング方法に関して説明いたします。
APIを提供しているサイトでは、APIを使ってデータを取得するのがマナーであり、かつAPIを使ったほうがより速く正確にデータ取得をすることができます。
Twitter APIキーの取得
TwitterのAPIキーを取得するためには、Twitterのアカウントを作成し、電話番号を登録する必要があります。
Twitterの電話番号登録は、まずTwitterホーム画面から右上のアイコンをクリックし、「設定とプライバシー」ページへ移ります。
その後、左カラムの「モバイル」から自分の電話番号を登録します。
次に、APIキーを取得するためのサイト(https://apps.twitter.com/)に行きます。
先程電話番号を登録したツイッターアカウントでログインしてから、Create New Appボタンをクリックします。
そうすると、以下のような画面がでてきますが、適当に入力して大丈夫です。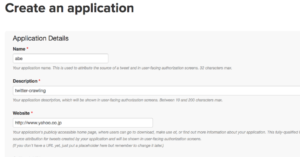
入力が終わると以下のような画面に遷移します。そこで、「Keys and Access Tokens」タブをクリックし、以下の2つのキーをメモしておきます。
・Consumer Key (API Key)
・Consumer Secret (API Secret)
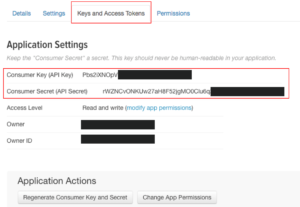
さらに下に進むと、Token Actionsと文字が現れるので、そこの Create my access tokenをクリックします。
すると、Your Access Tokenというのが表示されるため、ここから以下の2つの値をメモしておきます。
・Access Token
・Access Token Secret
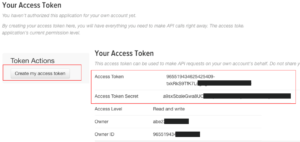
これら4つの値を使うことで、Twitterのデータを抽出することができます。
大切な情報なので、これらの値が外部に漏れないように、注意して管理しましょう。
Tweet情報取得のコード作成
pip install コマンドでインストールしてください。import pandas as pd from requests_oauthlib import OAuth1Session import json
次に、先程取得したAPIキーを、変数に入れます。
CK = 'xfUGKbhNTHBxxxxxxxxxxxx' CS = 'qvxs3MGLRhTWWsUsq8uWD2EFFsPD8YVxxxxxxxxxxxx' AT = '165379760-KuSI20zF9lkpnhZIkirrAqxxxxxxxxxxxx' ATS = 'sWGY6WWhPkd0JLeyKeQksDIOs00bC2xxxxxxxxxxxx'
params = {'q' : '大谷', 'count' : 5}次に、url の指定、またTwitter認証を行います。
そして、以下のように、APIを投げて返ってきたデータをreqという変数に入れます。
url = "https://api.twitter.com/1.1/search/tweets.json" twitter = OAuth1Session(CK, CS, AT, ATS) req = twitter.get(url, params = params)
ステータスコードが、`req.status_code` に格納されているので、この値が200になっていることを確認してから、Tweet情報を取得してみましょう。
以下のように書くと、search_timeline という変数に辞書型で結果が格納されます。
if req.status_code == 200: search_timeline = json.loads(req.text)
search_timelineから、Tweetごとの結果を得るためには、`search_timeline[‘statuses’]` にアクセスします。
そこに、Tweet情報がリスト型で格納されているので、1件目のTweetのみを抜き出すには、以下のように書きます。
search_timeline['statuses'][0]
text にTweetの文章が入っています。for tweet in search_timeline['statuses']:
print(tweet['text'])
print('-----')tweet_id を使います。tweet_id を保存しておき、次の100件のTweetを取得する際に、そのtweet_id よりも古いTweetを取得するという流れになります。max_id = -1
url = 'https://api.twitter.com/1.1/search/tweets.json'
keyword = '大谷'
count = 100
params = {'q' : keyword, 'count' : count, 'max_id' : max_id}
from time import sleep
columns = ['時間', 'ツイート']
df = pd.DataFrame(columns=columns)
while(True):
if max_id != -1:
params['max_id'] = max_id - 1
req = twitter.get(url, params = params)
if req.status_code == 200:
search_timeline = json.loads(req.text)
if search_timeline['statuses'] == []:
break
for tweet in search_timeline['statuses']:
created_at = tweet['created_at']
text = tweet['text']
append_list = [created_at, text]
df_next = pd.DataFrame(
[append_list],
columns=columns
)
df = df.append(df_next)
max_id = search_timeline['statuses'][-1]['id']
else:
print('15分待ちます')
sleep(15*60)上のコードのポイントですが、Tweetを全て取得し終わった時には終了するように、以下のように書いていてwhile文を終了させています。
if search_timeline['statuses'] == []: break
また、sleep関数を使い、Tweet取得の上限に達してしまった場合には、自動で15分待つようにしています。
if req.status_code == 200:
search_timeline = json.loads(req.text)
else:
print('15分待ちます')
sleep(15 * 60)
まとめ
TwitterAPIを用いてTweet情報を取得することができました。
今回はTweet時刻とTweet文章だけを抽出しましたが、リツイート回数や、いいねの回数など、様々な情報を取得することができます。
取得する内容によって上限回数に違いがあるので、コードを書く際には、こちらのドキュメントを参照しながらやってみてください。
DATUM STUDIOでは様々なAI/機械学習のプロジェクトを行っております。
詳細につきましてはこちら
詳細/サービスについてのお問い合わせはこちら
このページをシェアする: