TwitterクローラーとMecabを利用した大谷の打撃成績の推測

こんにちは、データ事業部2部の安部健太郎です。
前回の記事では、TwitterAPIを用いてツイートに”大谷”が含まれるツイートを検索してみました。
今回は、
・”大谷”が含まれるツイート数の時間推移
・ツイート内容の自然言語解析
を組み合わせ、この日大谷に何が起きたのか、推測してみたいと思います。
ツイート取得
ツイートの取得コードは以下のとおりです。コードの詳細は前回の記事を参照してください。
今回はツイートの時間変化を見たいため、ツイート時刻を後で使いやすいように、datetime型に変換、また日本時間にするために9時間を足しています。
この日(2018年4月13日)のエンゼルス戦は日本時間の9時10分開始で、大谷は8番DHで先発出場しました。
今回は試合開始前から試合終了後まで取得したいため、リクエストを500回送信し、50,000件のツイートを取得しています。
取得開始時間は2018年4月13日16時です。
import pandas as pd from requests_oauthlib import OAuth1Session from time import sleep import json from datetime import datetime, timedelta %matplotlib inline CONSUMER_KEY = 'xfUGKbhNTHBqyaxxxxxxxxxxxxx' CONSUMER_SECRET = 'qvxs3MGLRhTWWsUsq8uWD2EFFsPD8YVA8AZxxxxxxxxxxxxx' ACCESS_TOKEN = '165379760-KuSI20zF9lkpnhZIkirrAqbRY9DCxxxxxxxxxxxxx' ACCESS_TOKEN_SECRET = 'sWGY6WWhPkd0JLeyKeQksDIOs00bC2PVxxxxxxxxxxxxx' CK = CONSUMER_KEY CS = CONSUMER_SECRET AT = ACCESS_TOKEN ATS = ACCESS_TOKEN_SECRET twitter = OAuth1Session(CK, CS, AT, ATS)
max_id = -1
url = "https://api.twitter.com/1.1/search/tweets.json"
keyword = '大谷'
count = 100
params = {'q' : keyword, 'count' : count, max_id : max_id}columns = ['time', 'tweet']
df = pd.DataFrame(columns=columns)
i = 0
while(i < 500):
if max_id != -1:
params['max_id'] = max_id-1
req = twitter.get(url, params = params)
if req.status_code == 200:
search_timeline = json.loads(req.text)
if search_timeline['statuses'] == []:
break
for tweet in search_timeline['statuses']:
created_at = tweet['created_at']
created_at = created_at.split()
created_at = datetime.strptime('201804'+created_at[2]+created_at[3], '%Y%m%d%H:%M:%S')
created_at += timedelta(hours=9)
text = tweet['text']
append_list = [created_at, text]
df_next = pd.DataFrame(
[append_list],
columns=columns
)
df = df.append(df_next)
max_id = search_timeline['statuses'][-1]['id']
else:
print('5分待ちます')
print(f'i : {i}')
sleep(5*60)
i = i + 1ツイート数可視化
1分ごとのツイート数を合計し、ツイート数の時間推移を表した図が以下になります。
df_time = df.groupby(pd.Grouper(key='time', freq='1min')).count()
df_time.plot()
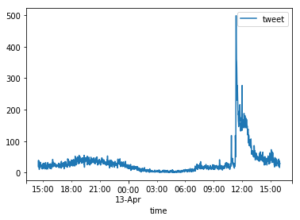
この日のエンゼルス戦は日本時間の9時10分開始のため、x軸の範囲を9時から15時までに変更します。
df_time.plot(xlim=('2018-04-13 09:00:00', '2018-04-13 15:00:00'))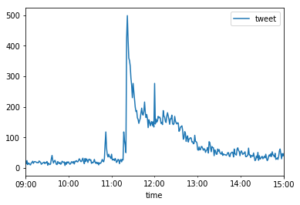
上の図より、9時半ごろに1度目のピーク、11時前に2度目のピーク、11時15分頃に3度目のピーク、その直後に大きなピークがあり、12時にもピークがあります。最後のピークは12時ちょうどで、かつ、この時間には試合が終わっているので、ニュースが一斉に出たと予想されます。そのため、今回は最初の4つのピーク時間のツイートを分析してみましょう。
ツイート分析
まずは、それぞれのピークの時間ごとに、dataframeを分割します。
peak1 = df[('2018-04-13 09:35:00'< df.time) & (df.time<'2018-04-13 09:40:00')]
peak2 = df[('2018-04-13 10:50:00'< df.time) & (df.time<'2018-04-13 10:55:00')]
peak3 = df[('2018-04-13 11:15:00'< df.time) & (df.time<'2018-04-13 11:18:00')]
peak4 = df[('2018-04-13 11:20:00'< df.time) & (df.time<'2018-04-13 11:30:00')]
次に、各時間にどのような単語が多くつぶやかれていたのかを表示する関数を作ります。
この関数では、MeCabを用いて形態素解析をして、多くつぶやかれた名詞のトップ20を表示させています。
def common_words(df):
t = MeCab.Tagger("-Ochasen")
t.parse('')
text = ' '.join(df.tweet)
node = t.parseToNode(text)
output =[]
while node:
word_type = node.feature.split(",")[0]
if word_type == '名詞':
output.append(node.surface)
node = node.next
cnt = Counter(output)
return cnt.most_common(20)まずは、一つ目のピークです。試合開始直後なので、おそらく今日1打席目の結果がこのツイートから読み取れるはずです。
上から順に見ていくと、14番目に”三振”という単語が含まれています。
おそらく、大谷は1打席目に三振したのでしょう。
#上位20単語を表示 common_words(peak1)
[('大谷', 142),
('.', 60),
('#', 60),
('https', 59),
('://', 59),
('t', 59),
('co', 59),
('/', 59),
('翔', 46),
(':', 43),
('@', 40),
('RT', 39),
('の', 31),
('三振', 28),
('くん', 25),
('打席', 24),
('1', 24),
('0', 22),
('平', 21),
('歳', 21)]次に、2つ目のピークです。
2番めに敬遠という単語があることから敬遠されたのだと予測できます。さらにただの敬遠ではなく、14番目に”申告”という単語があることから、申告敬遠だったのだと思われます。
#上位20単語を表示 common_words(peak2)
[('大谷', 379),
('敬遠', 216),
('https', 102),
('/', 102),
('://', 99),
('t', 99),
('.', 99),
('co', 98),
('#', 90),
('翔', 88),
('@', 78),
(':', 65),
('RT', 63),
('申告', 63),
('平', 40),
('打席', 39),
('_', 31),
('くん', 31),
('選手', 31),
('バット', 27)]次に、3つ目のピークです。
4つ目の大きなピークの直前ですが、ここにもピークがあり、4つ目のピークとは別のピークである可能性もあるため、ここも見てみました。
結果は以下のようになり、「満塁で打席が回ってきた」のではないか、と推測できます。また、この直後に4つ目の大きなピークがあることから、おそらくこの直後にタイムリーヒットを打ったのではないか、とこの時点で推測がつきます。
#上位20単語を表示 common_words(peak3)
[('大谷', 183),
('満塁', 88),
('/', 44),
('https', 43),
('.', 43),
('://', 42),
('t', 42),
('co', 42),
('翔', 36),
('@', 35),
(':', 28),
('RT', 26),
('平', 24),
('#', 20),
('打席', 16),
('敬遠', 16),
('3', 15),
('こと', 13),
('申告', 13),
('2', 13)]
次に、4つ目の大きなピークです。
満塁で回ってきている(と思われる)この打席でどのような結果を出したのか、見てみましょう。
結果を見ると、満塁で走者一掃の三塁打を打ったように思われます。ツイート数からも、ものすごい盛り上がりだったことが予想されます。
common_words(peak4)
[('大谷', 3609),
('.', 1218),
('/', 1213),
('https', 1209),
('t', 1209),
('://', 1207),
('co', 1207),
(':', 1146),
('@', 1102),
('RT', 1051),
('#', 1045),
('走者', 910),
('一掃', 910),
('三塁打', 877),
('満塁', 833),
('翔', 766),
('打席', 670),
('3', 638),
('点', 614),
('3', 587)]
ツイートからの結果予測が終わったところで、答え合わせをしてみましょう。
この日の大谷の結果は以下のとおりです。
第一打席:三振
第二打席:レフトフライ
第三打席:申請敬遠
第四打席:スリーベースヒット
第五打席:サードゴロ
どうでしょう、「三振」「申告敬遠」「スリーベースヒット」を見事に的中させることができました。スリーベースヒットは、満塁での打席で走者一掃のスリーベースヒットでした。
また、いくら大谷といえども、凡打の時にはツイート数が増えないこともわかりました。第一打席は1打席目、かつ9時過ぎで出勤前の時間帯だったため、ツイート数が多かったと予想されます。
まとめ
ツイート情報のみから、大谷の結果を推測することができました。
このように、Twitterクローリングと、自然言語処理を合わせることで、他にも様々な情報が得られます。平均値からの差分を計算し、ツイート数が増えた時にアラートを出す処理を加えても良いでしょう。APIを用いたクローラーはサイトへの負荷も気にする必要もないので、ぜひたくさん試してみてください。
このページをシェアする: