Snowflake Summit 2025 最速レポート3日目⑤
Power Declarative Pipelines with Dynamic Tables and Apache Iceberg

DATUM STUDIOの原戸です。
ダイナミックテーブルとIcebergを使用した宣言的なパイプラインの作成方法とそのメリットについて紹介されたセッションについてレポートします。
データエンジニアリングの世界は近年ますます複雑化し、ストリーミングとバッチのハイブリッド処理、即時性、メンテナンス性、拡張性といった多様な要件が求められるようになりました。
このような背景のもと登場したのが、SnowflakeによるDynamic Iceberg Tablesです。これは、Apache Icebergの高性能なテーブルフォーマットとSnowflakeのマネージド・アーキテクチャを融合させた、新しいタイプの宣言的パイプライン構築ソリューションです。
目次
動的なデータ管理を実現するDynamic Iceberg Tables
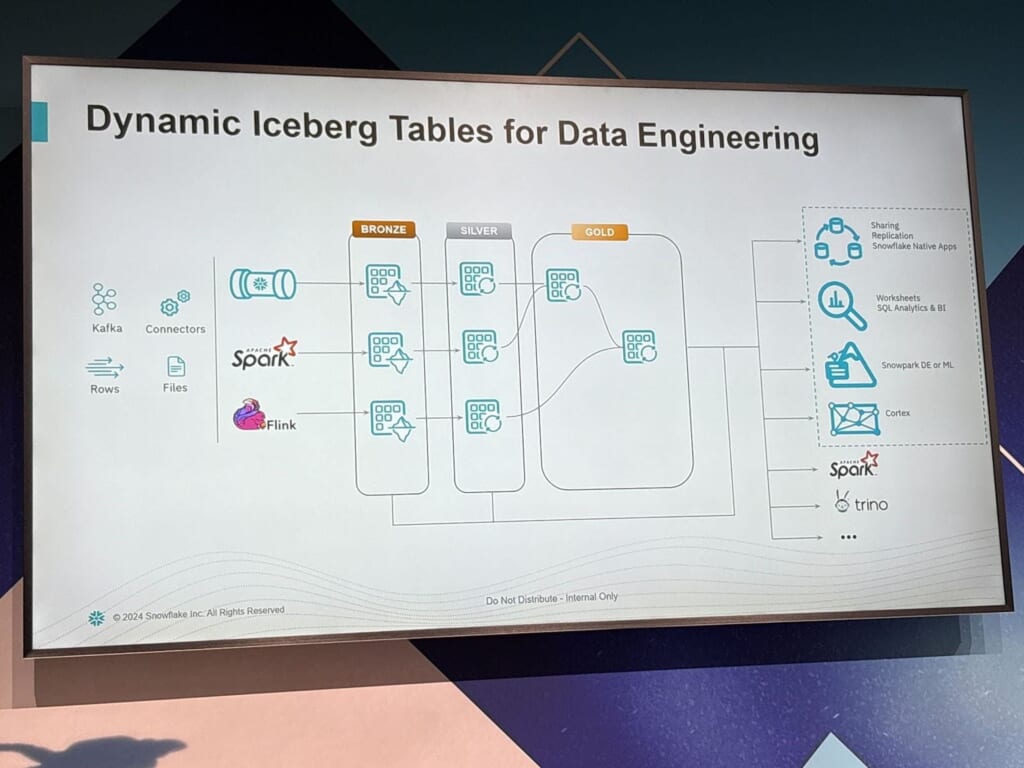
Dynamic Iceberg Tablesとは、特定のクエリの結果をIceberg形式のテーブルとして定義し、その内容を自動で定期的に更新するという新機能です。従来、クエリ結果を永続化して定期的に更新するには、バッチ処理のスケジューリングやワークフローオーケストレーションなどの煩雑な運用が必要でしたが、Dynamic Iceberg Tablesではわずか数行のSQLを記述するだけで、こうした仕組みがすべて内包されます。

従来の課題とDynamic Iceberg Tablesがもたらす変革
従来のデータパイプライン運用には3つの大きな課題がありました。
一点目は「複雑性」です。多くのステップや依存関係、スケジューリング、リトライ処理を含むパイプラインは構築が難しく、障害点が多くなりがちです。
二点目は「非効率性」です。処理単位が大きく、必要のない再計算や手動最適化が頻発し、保守コストが高いという問題があります。
そして三点目は「管理性の低さ」です。パイプラインは脆くさらに上流の変更に弱いため、複数のベンダーやツールをまたぐことで管理が煩雑になります。
Dynamic Iceberg Tablesは、こうした問題を根本から解決します。まず、宣言的なSQLだけでストリーミングおよび連続バッチ処理が実現でき、オーケストレーションの設定が不要になります。これは、複雑な依存関係の解消と運用負荷の大幅な軽減を意味します。さらに、クエリに基づいた増分処理が行われ、必要最小限の再計算だけが実行されるため、非常に効率的です。Snowflake側でクエリ内容を解析し、リフレッシュ戦略の推奨まで行ってくれるため、手動のチューニングも不要です。

Apache Icebergとの融合によるモダンなパイプライン設計
Apache Icebergは、高性能でトランザクションセーフなテーブルフォーマットとして知られています。Hiveメタストアの制約に縛られず、スナップショットごとのバージョン管理やスキーマの進化、パーティショニングの自動化などをサポートしています。Dynamic Iceberg Tablesでは、このIcebergの強みをSnowflakeがネイティブに活用し、ストレージの分離やクエリエンジン間の相互運用性を実現しています。
作成されたIceberg形式のテーブルは、Snowflake内部はもちろん、Apache Spark、Trino、Flinkといった他のエンジンからもアクセス可能です。これにより分析や機械学習、ETL処理、アプリケーション連携といった多様なユースケースに対応できます。データサイロを作らず、あらゆるチーム・ツール・プラットフォーム間で同じデータを使い回すことが可能になるのです。
パイプラインの信頼性と可観測性
Dynamic Iceberg Tablesは、信頼性と可観測性(オブザーバビリティ)においても優れています。Snowsight UIでは、各Dynamic Tableのステータス、リフレッシュ履歴、対象ラグ、最新のエラー情報など一目で確認可能です。さらに、イベントテーブルを通じて、SlackやMicrosoft Teams、PagerDutyなどへの通知を自動化できるため、異常発生時の迅速な対応が可能です。
加えて、DatadogやGrafanaといった外部の監視ツールとも連携可能であり、エンタープライズレベルのモニタリング体制を構築することも容易です。これにより運用チームがシステムの健全性を常に把握できるだけでなく、DevOpsとの連携やSRE的な対応もスムーズになります。

宣言的なデータエンジニアリングの未来
Dynamic Iceberg Tablesの本質的な価値は、SQLだけで完結するという点にあります。もはや複雑なETLツールやオーケストレーションエンジンに頼る必要はありません。パイプラインの構築と運用がSQLで宣言的に定義できるということはデータエンジニアだけでなく、アナリストやサイエンティスト、ビジネスユーザーにとっても大きな恩恵となります。
まとめ
SnowflakeのDynamic Iceberg Tablesは、パイプライン設計のあり方を根本から変える可能性を秘めた技術です。シンプルな宣言的記述で複雑な依存関係を吸収し、自動的にリフレッシュされるIcebergテーブルとして提供されることで、データ運用の手間とリスクを大幅に削減します。
エンジニアリングのコストを抑えつつ、ユーザー体験を向上させたいと考える企業や組織にとって、Dynamic Iceberg Tablesは非常に有効な選択肢となるでしょう。システムのスケーラビリティとガバナンス、セキュリティを保ちながら柔軟で迅速なデータ処理が可能になるこの仕組みは、今後の標準的なデータアーキテクチャの中核となることが期待できるといいですね!
より詳細なDynamic Tablesの仕組みや活用方法は、以下の資料が参考になりますのでぜひご覧ください。
Streaming Democratized: Ease Across the Latency Spectrum with Delayed View Semantics and Snowflake Dynamic Tables
このページをシェアする: