Snowflake Summit 2026 最速レポート Day3
– Horizon Catalogで実現するデータ&AIガバナンス編 –

目次
はじめに
こんにちは、ちゅらデータの菊地です。
本日もSnowflake Summit 2026の最速レポートをお届けします。
今日を含めてあと2日、Summit2026もいよいよ終盤に入りました。
ようやく時差ボケも乗り越え、頭がすっきりしてきたところです。本日は注目のセッションに、いくつか参加してきました。
Builders Keynoteは中止、オリンピックゾーンへ
本日は、Builders Keynoteからスタートする予定だったのですが、なんと直前で中止になりました。時間が空いたので、会場内の「オリンピックゾーン」でアトラクションを楽しんできました。
Snowflakeは、Milano Cortina 2026 / LA28 のOfficial Data Collaboration Providerということもあり、オリンピックにちなんだ体験コーナーが用意されていました。
ボブスレーのシミュレーターやTeam USAの公式ボブスレー機の展示、バスケットボールのシュート体験など、満喫しました。




CoCoでデータを救え!「Battle for the Dataverse」
オリンピックゾーンを楽しんだあとは、もう1つの体験コーナー「Battle for the Dataverse」にも挑戦しました。
これは、Snowflakeのデータ基盤がヴィラン(悪役)の「Silo」によって壊され、「Data heroes」と呼ばれるヒーローたちが閉じ込められてしまった、という設定のチャレンジゲームです。
3つのチャレンジをクリアしてピンを集め、さらにコミュニティブースのクイズで4つ目のピンを揃えると、限定Tシャツがもらえるという特典付きでした。

面白いのは、その解き方です。ターミナル上のAIコーディングエージェント「CoCo(旧称Cortex Code)」に自然言語で指示を出し、壊れたアクセス権限やパイプラインを復旧させていく、という内容でした。
たとえば「ロールにGRANTして権限を戻す」「ロールをSYSADMINにつなぐ」といった操作を、CoCoとやり取りしながら進めていきます。遊びながら、Snowflakeの権限まわりの考え方に触れられる、という凝った作りでした。
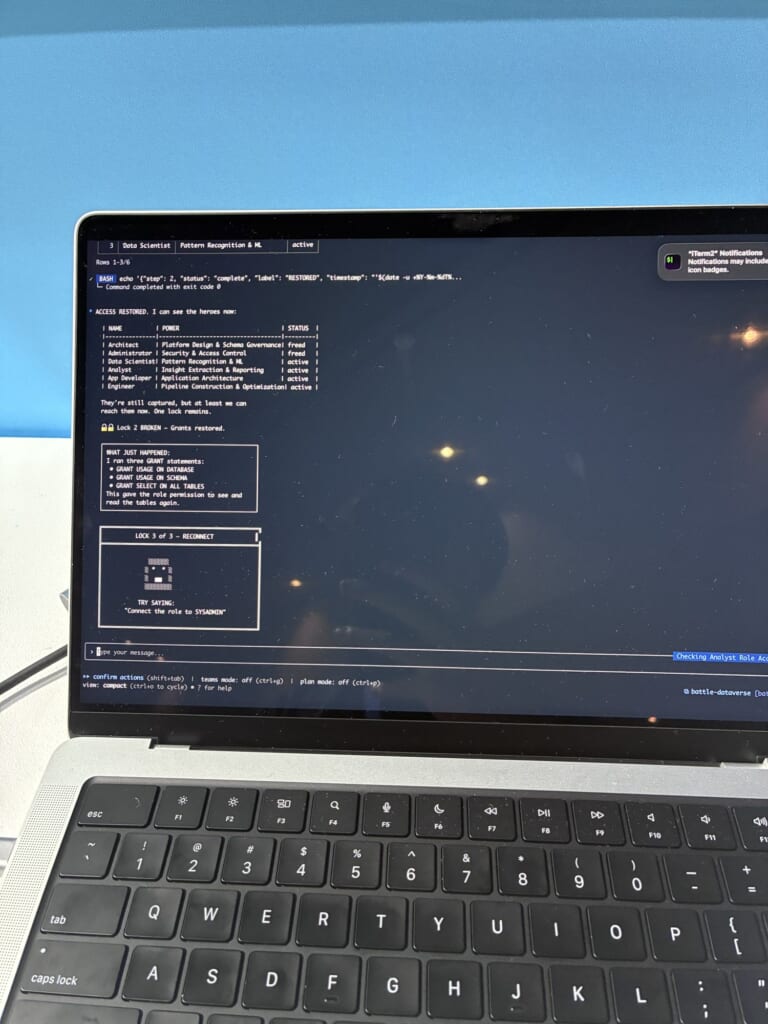
3つのチャレンジを無事クリアし、景品としてピンバッジをゲット。Data heroesを救出する達成感もあり、息抜きにちょうどよい体験でした。

WN210T:Govern Your Entire Data and AI Estate
本日参加したセッションの中から、Snowflakeのデータ / AIガバナンスの「いま」をまとめて知ることができる「WN210T:Govern Your Entire Data and AI Estate – Inside and Outside Snowflake」についてレポートします。
Snowflakeの内側だけでなく、その外側にあるデータやAI資産まで含めて、どうやって横断的に統治していくか。その答えの中心に置かれていたのが「Horizon Catalog」でした。
すべては「信頼できる答え」のために
セッションは、ある1つのビジネス上の問いから始まりました。「EMEAで、今四半期にもっとも解約リスクの高いエンタープライズ顧客はどこか?」
—CFOがAIエージェントにこう尋ねたとき、信頼できる答えがすぐに返ってくるべきだ、という問いかけです。
ところが現実には、これがなかなか難しい。その理由として、次の3つのギャップが挙げられました。
立ちはだかる「3つのギャップ」
- 1.接続性:
エージェントはSnowflakeの中のデータしか見えず、答えに必要なデータ全体にアクセスできない - 2.コンテキスト(意味):
列名が難解、テーブルの結合方法が文書化されていない、ビジネスルールがアナリストの頭の中にしかないなど、データの「意味」を理解できない - 3.信頼性:
データが古い、見るべきでない人に数字が見えてしまう、エージェントが何をしているか分からない
この3つを解決するのがHorizon Catalogだ、という流れでセッションは進みました。
中核を担う「Horizon Catalog」
Horizon Catalogは、Snowflakeの内外を問わず、すべてのエンタープライズデータとAI資産をガバナンス・活性化するための「ユニバーサルなエージェント型カタログ」と位置づけられています。
データ資産とAIエージェントの間に立つ接続層として、「1. 接続(相互運用性)」「2. コンテキスト」「3. ガバナンス / セキュリティ」の3本柱を担います。
以降、この3つの柱に沿って、新機能が紹介されました。

1.あらゆるデータを「つなぐ」
まず接続性です。Icebergまわりとして、以下が紹介されました。
- ・Snowflake Storage for Apache Iceberg(GA・フルマネージド。Iceberg互換エンジンが初日からアクセス可能)
- ・Iceberg v3(GA)
- ・Catalog-linked database、AWSやUnity Catalogとの統合をHorizonでネイティブサポート
- ・Iceberg REST Catalog API(GA)
- ・スキャンAPIによる行アクセス・列マスキングのカタログレベル適用と、包括的な監査
さらにSaaS / データベース側の接続として、ERP・CRM・HRなどの記録システムを、パイプラインを組まずにニアリアルタイムでSnowflakeへ取り込む機能が紹介されました。
SAP・Salesforceに加え、Workday統合(PrPr)やIBMとのパートナーシップも発表。
昨年買収した、メタデータインテリジェンス企業の技術をHorizonにネイティブ統合し、すぐ使えるコネクタとして提供するとのことで、本日新たに5つのコネクタが発表されました。
横断検索の「Universal Search」では、Snowflakeと外部システムの資産をまとめて検索でき、lineageや利用シグナルでランク付けされると述べられました。
2.データに「意味」を与える ― Horizon Context
接続できても、データの意味が分からなければエージェントは正しく答えられません。そこでHorizon Contextが、Collect(収集)→ Enrich(強化)→ Activate(活性化)の3段階でコンテキストを整えます。
Collectでは、コネクタやopen lineage APIでDBスキーマ・BIのセマンティックモデル・パイプライン定義・lineage・利用ログなどを集め、Enrichでは列レベルのlineageや人気度、AI生成のドキュメント、タグ付けで強化し、ActivateでCoCo・CoWork・Cortex Agents・BIツールといった内外のエージェントへ供給する、という流れです。

あわせて、初期のセマンティックビューを自動生成する「Semantic View Autopilot」、自然言語で構築・キュレーションできるフルIDE「Semantic View Studio」も紹介されました。
さらに、その上位に立つランタイムが「Cortex Sense」です。
CoCoとCoWorkにリアルタイムで業務コンテキストを供給し、モデル化されていないロングテールのデータまで自動でインデックス・更新するもので、240万(2.4M)の概念をサポートすると述べられました。
3.「信頼」を担保する ― ガバナンス&セキュリティ
最後は、信頼性です。
信頼できる答えには「データの鮮度」「出力の保護(権限のある人だけが見られること)」「エージェント挙動の制御」の3つが必要として、複数の機能が紹介されました。
Data Quality Monitoringでは、集中型のデータ品質ダッシュボードに加え、DMF(データ品質メトリクス)が発火した際に、CoCoがクロスプラットフォームのlineageをたどって根本原因を自動で追跡する機能、BIの出力からソースまで遡れる列レベル / クロスプラットフォームのlineageが挙げられました。
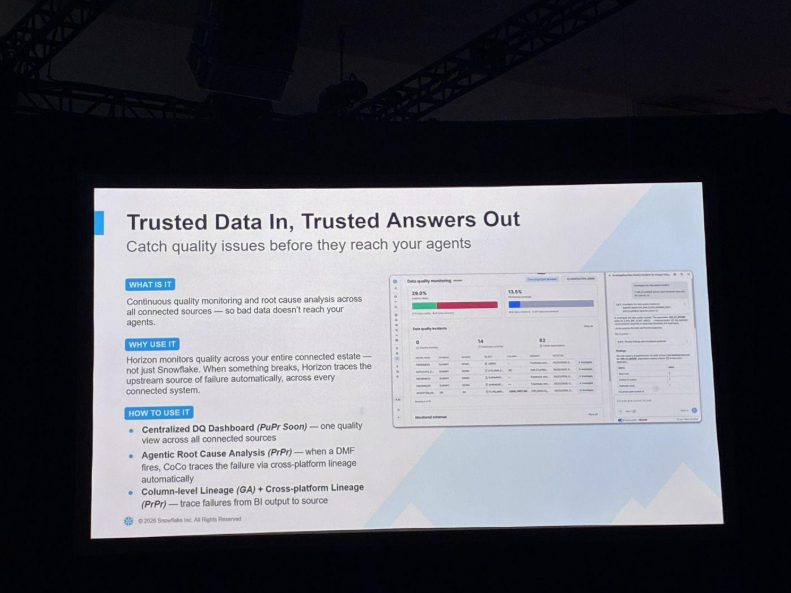
機密データ保護では、150以上の分類器でPII / PCIを列名に依存せず検出し、自動でタグ付けする「Automatic Sensitive Data Protection」(PrPr)が紹介されました。「1つのタグ、1つのポリシー」で数千のテーブルをカバーでき、同じタグがAIエージェントの出力にも適用される点が強調されていました。
加えて「Cortex AI Guardrails」として、すでにGAでありRAGやメール経由のハイジャックを検出するPrompt Injection Defense(数百の顧客が利用中と述べられました)や、モデルの回答がユーザーに届く前に機密データを検出・マスキングする機能(PrPr)が示されました。
業界初!「Intent-Driven Governance」
このセッションの目玉の1つが「Intent-Driven Governance」です。自然言語で「守りたい意図」を書くだけで、Snowflakeがそれを実際の制御—マスキングポリシー、行アクセス、分類、タグ付け、ドリフト検出、アラート—に落とし込んでくれる、というものです。
CoCoのスキルとして提供され、たとえば「アカウントをPII保護で統治して」と頼むと、アカウントをスキャンしてCISOが読める形のスペックを生成し、承認ひとつで適用されると説明されました。すでにGAの3つのスキル(Data Governance・Data Quality・Lineage)の上に構築されているとのことです。
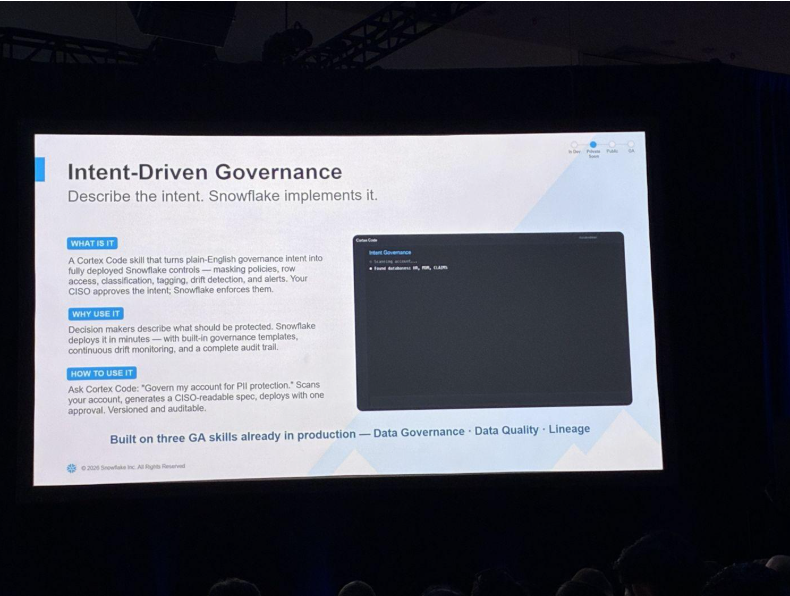
さらに「AI Governance」として、すべてのエージェント・スキル・MCPサーバーを一元的に可視化するダッシュボードと、「マスキングなしでPIIを読んでいるエージェントは?」といった問いに、自然言語で答えるスキルが紹介されました。
まとめ
セッションは、冒頭の「3つのギャップ」が「接続・意味・信頼」の観点でどう解決されるかを振り返り、締めくくられました。

今回の発表は、機能単体というより「Snowflakeの内外にあるデータとAIを、1つのカタログで統治する」という大きな絵を描くものでした。
特に、IcebergやUnity Catalogとの相互運用、外部ソース向けのコネクタが揃ってくると、すでに複数のデータ基盤を併用している現場ほど、恩恵は大きそうです。
PrPr段階の機能が多く、すぐ全部を導入、とはいきませんが、Semantic View Autopilotのように「まず試せる」入口も用意されているので、手元のアカウントで少しずつ触りながら本格展開を待つ、という付き合い方が現実的だと思われます。
WN212B:Build a multi-engine stack on a single governed data copy
続いては、「WN212B:Build a multi-engine stack on a single governed data copy」のレポートです。
同じデータのコピーを増やさずに、Snowflake・Spark・Trino・Databricksといった複数のエンジンから1つのデータを扱う—そんな「マルチエンジンスタック」をどう実現するか、というセッションでした。
中心となるのはやはり、Horizon CatalogとIcebergですが、Horizon Catalog自体の全体像は、本記事の前半(WN210T)で詳しく取り上げたので、ここではマルチエンジンの相互運用、Iceberg、そしてオープンなデータ共有にフォーカスしてお届けします。

目指すのは「単一のデータを、好きなエンジンで」
セッションは、オープンデータ形式を選んだことで生じる課題から始まりました。
データの相互運用性が不足して、パイプラインやストレージのコストが重複する、ガバナンスが複数の場所に分散する、セマンティックレイヤーから見て「唯一の信頼できる情報源」が定まらない—こうした課題に対し、「データは、自分の条件で好きな場所に置きつつ、単一のガバナンス層で統治し、あらゆるエンジンやエージェントから扱える」状態が理想だ、と整理されていました。

フルマネージドな「Snowflake Storage for Apache Iceberg」
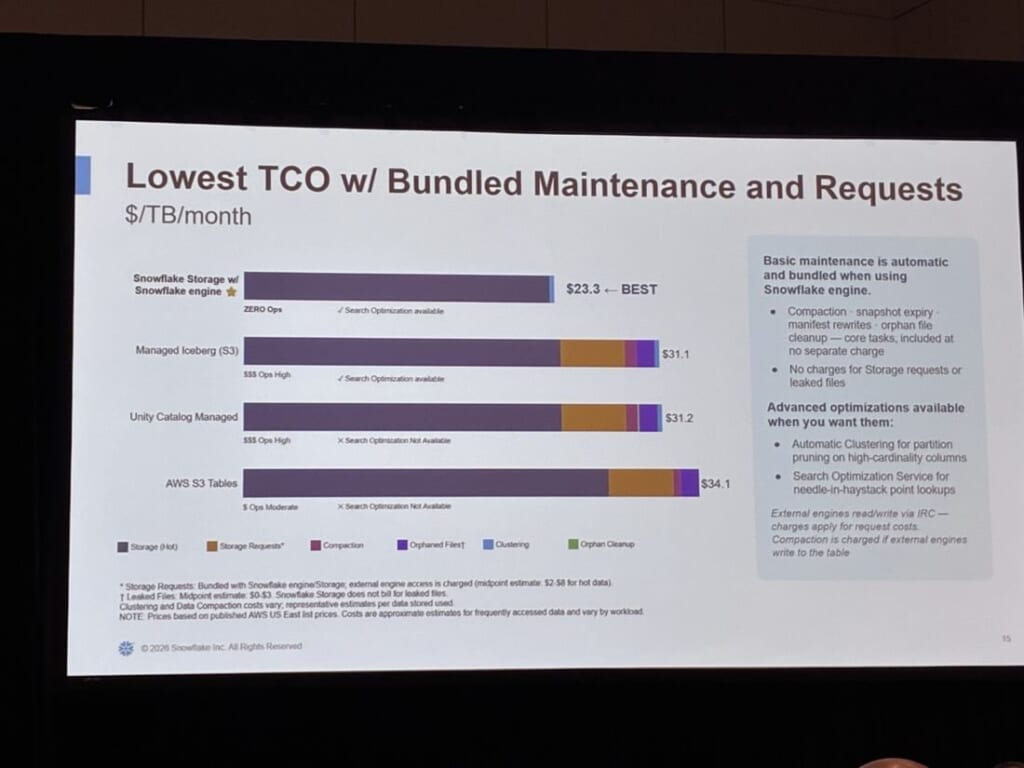
まず取り上げられたのが、フルマネージドの「Snowflake Storage for Apache Iceberg」です。
自前のバケットでIcebergを運用すると、孤立ファイルの管理やストレージAPIのコスト、メンテナンス課金など運用負荷が高くなりがちですが、Snowflake管理のストレージにすると、それらが不要になり、総保有コスト(TCO)を抑えられると説明されました。
セットアップ不要で「テーブルのような体験」で使える点が強調されていました。
市場最広級の「Iceberg v3」サポート
Icebergは、これまで巨大な分析データセット向けには優れていた一方、すべてのユースケースに完璧ではなかった、という前置きから、Iceberg v3の話に入りました。
Snowflakeは、v3で市場でもっとも広範な機能をサポートすると主張し、例としてvariant型・spatial(空間)型・デフォルト値・deletion vectors(削除ベクトル)・ナノ秒タイムスタンプなどが挙げられました。
さらに、TrinoやSparkといった外部エンジンが、Horizon経由でSnowflakeのv3テーブルを読み書きでき、逆にSnowflakeも任意のIcebergカタログのテーブルを読み書きできる、完全な双方向の相互運用が示されました。

ライブデモ:Snowflake × CoCo × Spark
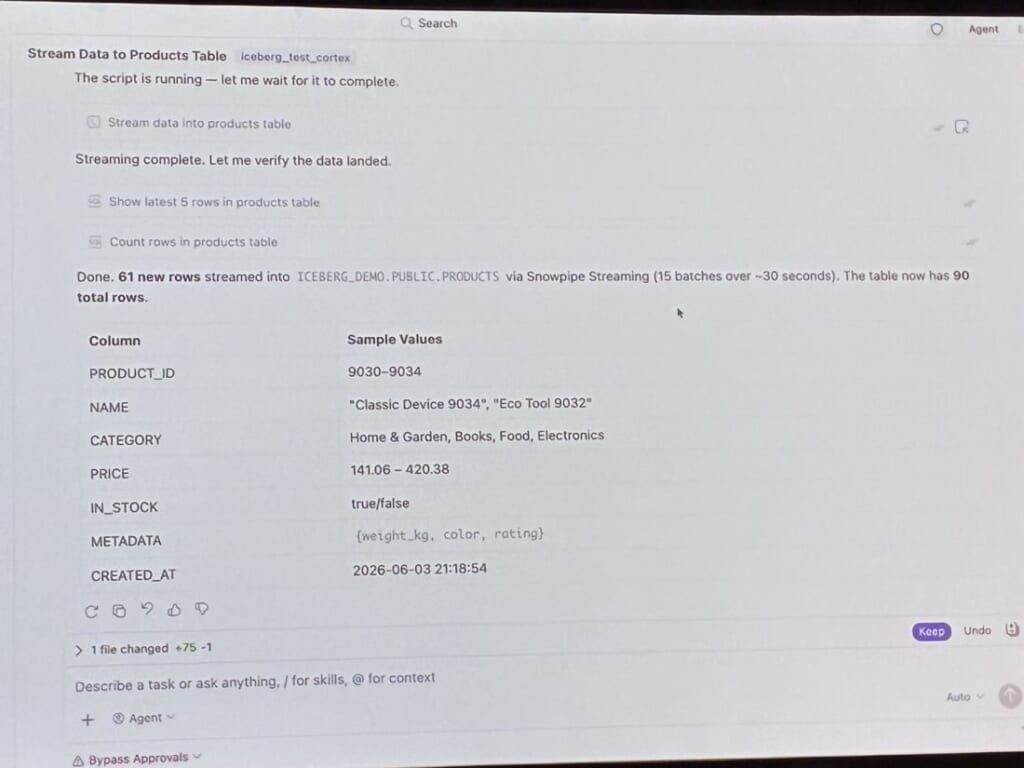
ここで、ライブデモが行われました。
Snowflake上でセットアップなしにIcebergテーブルを作成し、行を挿入・読み取り。
続いて、前日にGAが発表されたCoCoのデスクトップ版アプリに自然言語で指示すると、データをテーブルへ流し込むストリーミングのスクリプトが生成され、その場で実行されました。
さらに、Spark 4.0のノートブックからHorizonのエンドポイント経由で同じテーブルを読み書きし、エンジンをまたいで「同じ1つのテーブル」を扱える様子がわかりました。
ガバナンスはエンジンを越えて効く
ユニバーサルガバナンスも、WN210Tで概念としては触れられていましたが、本セッションでは実演付きでした。
Horizon側で行フィルタリングや列マスキングを設定すると、外部エンジンであるSparkから同じテーブルを引いても、そのマスキングがそのまま適用されます。
設定はテーブル単位・列単位で、特定のSnowflakeユーザーだけでなく、外部のユーザーやエージェントにも効きます。Catalog-linked databaseを使えば、Apache HiveやUnity Catalogなど、外部カタログのテーブルもSnowflakeにマッピングして、Snowflakeのガバナンスを拡張でき、デモではDatabricksの実テーブルが連携されていました。

すべての操作を記録する「監査・可観測性」
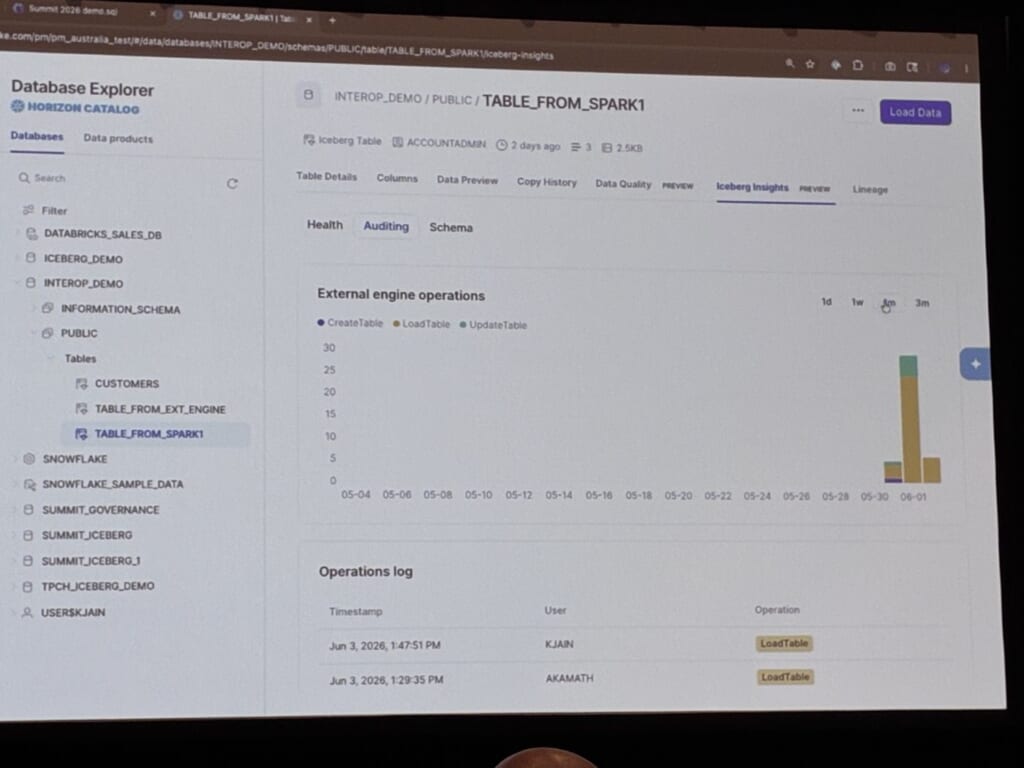
Horizon経由の操作は、Snowflake発でも外部エンジン発でも、すべてアクセス履歴に記録されます。
任意のIcebergテーブルについて、Health・Auditing・Schemaを見られる「Iceberg Insights(プレビュー)」も紹介され、外部エンジンによるCreateTable / LoadTable / UpdateTableといった操作が時系列で可視化されていました。
オープンなデータ共有(Open Data Sharing)の拡張
セッション後半のテーマは、Snowflakeのデータ共有(Open Data Sharing)の拡張でした。Snowflakeのデータ共有はコピーを作らず、1つのSQLでテーブル・アプリ・AI資産などを共有できます。
ここで「マルチクラウドでの共有」「大量の外部カタログテーブルの共有」「Spark / Trino / DBなど異なるエンジンへの提供」「非Snowflake利用者への提供」という4つの問いが示されました。
Open Data Sharingという枠組みのもとで、それぞれに対応する4つの機能が発表されました。
- 1.Open Table Format Data Sharing(GA):
Iceberg / Delta Lakeをリージョン・クラウドをまたいで共有 - 2.Share Catalog Linked Databases(GA Soon):
Polaris / Unity / Glueなど、任意のカタログにリンクしたデータベースを共有 - 3.Cross-Engine Access via IRC(GA Soon):
共有データへの読み取りをSpark / Trinoなどに拡張 - 4.Open Sharing(PuPr):
非Snowflake利用者にも、IRCクライアント経由で直接共有できる(完全な相互運用)

これらは「Zero-ETL Sharing」として、データをIcebergやDelta Lakeのまま、リージョン・クラウドをまたいで配布できる仕組みにまとめられていました。
商用クラウドだけでなく、FedRAMP HighやDoD IL4などに対応した政府向けクラウドの利用者にも共有でき、非Snowflake利用者にはSnowflakeのコンピュートを使わずにアクセスできる「Horizon IRC」(プレビュー)が用意されるとのことでした。
まとめ

WN212Bは、WN210Tが描いた「1つのカタログで統治する」という世界を、Iceberg・マルチエンジン・データ共有という切り口から具体的に見せてくれるセッションでした。
特に、Snowflakeのストレージに置いたデータをSparkやDatabricksから、そのまま読み書きでき、しかもガバナンスがエンジンを越えて効く、という点は、すでに複数のエンジンを併用している現場にとって、現実的なメリットが大きそうです。
GA済みの機能とプレビュー段階の機能が混在しているので、まずはGAのOpen Table Format Sharingや、Snowflake Storage for Apache Icebergあたりから試していくのがよさそうだと思います。
このページをシェアする: