Python 描画入門 – 第1回 histogram
目次
この連載では、下記ライブラリ・メソッドの基本的な仕様を、グラフの種類ごとに紹介していきます。
- matplotlib→matplotliについての関連ブログはこちら
- pandas.DataFrame
- seaborn
入門レベルの知識ですが、異なるライブラリを並べて書くことで簡易なカタログとして使える記事になればいいと考えています。第1回はhistogramです。
使用データ
代表的な、irisを使用します。データはヘッダーを付けたCSVに加工してあります。
import pandas as pd
iris = pd.read_csv('iris.csv')
print(iris.head())sepal_length sepal_width petal_length petal_width class 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa
setosa = iris[iris['class']=='Iris-setosa']
versicolor = iris[iris['class']=='Iris-versicolor']
virginica = iris[iris['class']=='Iris-virginica']
print(setosa.head())
print(versicolor.head())
print(virginica.head()) sepal_length sepal_width petal_length petal_width class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
sepal_length sepal_width petal_length petal_width class
50 7.0 3.2 4.7 1.4 Iris-versicolor
51 6.4 3.2 4.5 1.5 Iris-versicolor
52 6.9 3.1 4.9 1.5 Iris-versicolor
53 5.5 2.3 4.0 1.3 Iris-versicolor
54 6.5 2.8 4.6 1.5 Iris-versicolor
sepal_length sepal_width petal_length petal_width class
100 6.3 3.3 6.0 2.5 Iris-virginica
101 5.8 2.7 5.1 1.9 Iris-virginica
102 7.1 3.0 5.9 2.1 Iris-virginica
103 6.3 2.9 5.6 1.8 Iris-virginica
104 6.5 3.0 5.8 2.2 Iris-virginica1. matplotlib.pyplot.hist()
基本仕様
matplotlib.pyplot.hist(x=[DataFrame/Series, ...])の形で呼び出します。デフォルトでは、複数の項目を階級内で横並びに表示します。
複数項目で階級幅は同期されます。階級数は10です。色は自動で振り分けられます。凡例はデフォルトでは表示されません。pyplot.show()より前に呼び出されたグラフがまとめて描画されます。
import matplotlib.pyplot as plt
%matplotlib inline
# デフォルト
plt.hist(x=[iris.sepal_length, iris.sepal_width, iris.petal_length, iris.petal_width])
plt.show()
積み上げヒストグラムの簡易な描画
複数の項目をxパラメータにリスト形式で指定することで、ひとつのヒストグラムに出力できます。これを用いることで積み上げヒストグラムを簡単に描画できます。
import matplotlib.pyplot as plt
# 3種類のsepal_lengthを10階級のヒストグラムに出力する.
plt.hist(x=[setosa.sepal_length, versicolor.sepal_length, virginica.sepal_length],
color=['coral', 'lightblue', 'khaki'], #色の指定
stacked=True) #積み上げヒストグラム
# 凡例
plt.legend(['setosa', 'versicolor', 'virginica'])
plt.show()
2. pandas.DataFrame.plot()
基本仕様
pandas.DataFrame.plotは前述のmatplotlib.pyplotのラッパーで、kindプロパティにグラフ種類を指定することで様々なグラフをシンプルなコードで描画できます[^1]。 ヒストグラムはDataFrame.plot(kind='hist')またはDataFrame.plot.hist()の形式で呼び出します。デフォルトでは、複数の項目が重ねて描画されます。 複数項目で階級幅は同期される。階級数は10です。色は自動で振り分けられ、凡例も自動でつくので見やすくなります。
# デフォルト;全ての数値項目を重ねて表示
iris.plot(kind='hist')
# 下記も同様
# iris.plot.hist()
複数項目を一括で可視化
パラメータの設定で、複数の数値項目を個別に出力できます。同じデータフレームの値から出力したグラフの階級幅は同期されます。
# デフォルト;項目ごとに別のグラフを出力
iris.plot(
kind='hist', # グラフ種別
subplots=True, # 項目ごとに分割
figsize=(8, 5), # 描画する面積
layout=(2, 2) # レイアウト(行数, 列数)
)
グラフを重ねて描画
‘ax’パラメータで、複数のデータフレームから生成したヒストグラムを重ねて描画できます。
# 品種ごとに10階級ずつのヒストグラムを重ねて表示
# * color: 色を指定
# * alpha: 透明度
ax = setosa.sepal_length.plot(kind='hist', color='coral', alpha=0.5)
ax = versicolor.sepal_length.plot(kind='hist', color='skyblue', alpha=0.5, ax=ax)
virginica.sepal_length.plot(kind='hist', color='khaki', alpha=0.5, ax=ax)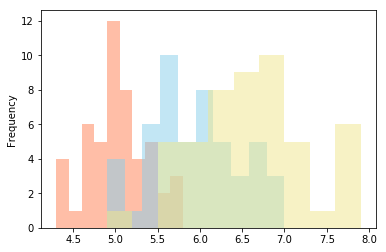
3. pandas.DataFrame.hist()
基本仕様
DataFrame.hist()の形で呼び出します。デフォルトでは、複数の項目が別々に描画されます。 階級幅・頻度(y軸の幅)は統一されません。階級数は10です。色は統一されます。各グラフ上部に項目名が表示されます。
# 全ての数値項目を別々のグラフに出力
iris.hist()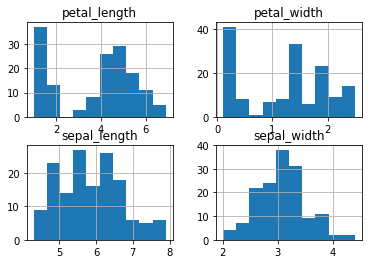
簡易な可視化
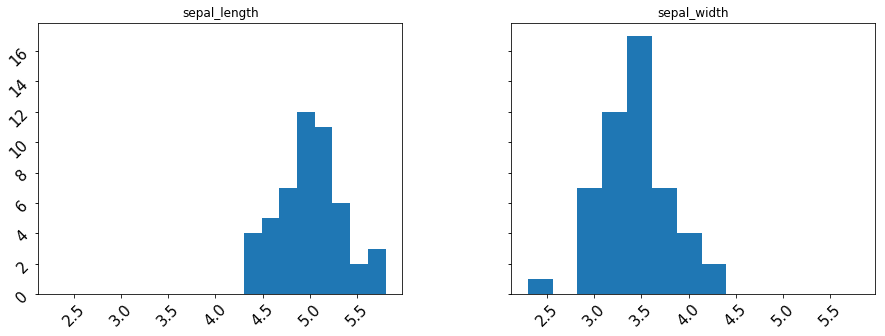
シンプルな書式で呼び出せることに加え、ラベルや罫線などの操作が直感的でわかりやすいです。手軽に分布を確認したいときに重宝します。。
# 簡易な設定
setosa.hist(
column=['sepal_length', 'sepal_width'], # 項目を指定
figsize=(15, 5), # 描画する面積
sharex=True, sharey=True, # x軸,y軸の同期
xrot=45, yrot=45, # ラベルの回転
xlabelsize=15, ylabelsize=15, # ラベルのサイズ
grid=False,
bins=8
)
4. seaborn
基本仕様
sns.distplot(a=DataFrame/Series)の形で呼び出します。デフォルトでは複数項目を描画できません。 階級数は、フリードマン=ダイアコニスの法則に則って自動で定められます。importするだけでmatplotlibの描画がseaborn風になるほか、sns.distplot()でカーネル密度推定の結果とともにヒストグラムを描画できます。
import seaborn as sns
# デフォルト;カーネル密度推定の曲線とともにヒストグラムを表示
sns.distplot(a=setosa.sepal_length)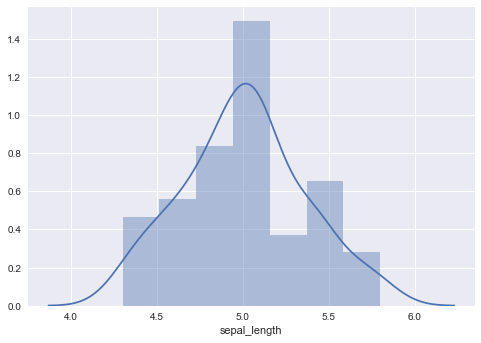
import seaborn as sns
# matplotlibのseaborn風の描画
plt.hist(x=[setosa.sepal_length, versicolor.sepal_length, virginica.sepal_length],
color=['coral', 'lightblue', 'khaki'], #色の指定
stacked=True) #積み上げヒストグラム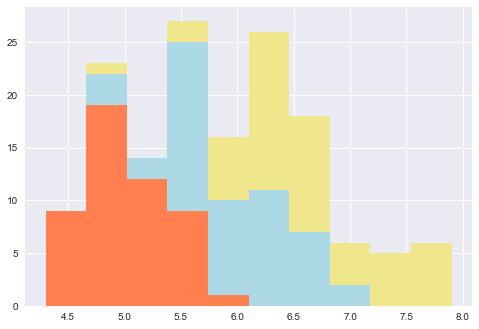
カーネル密度推定/ラグプロット
seabornのヒストグラムでは、デフォルトでカーネル密度推定の結果を示すグラフが描画されます。また、rugパラメータによってラグプロットの描画もできます。
import seaborn as sns
# カーネル密度推定/ラグプロット
# * kde:カーネル密度推定(デフォルト:True)
# * rug:ラグプロット(デフォルト:False)
ax = sns.distplot(a=setosa.sepal_length, kde=True, rug=True)
ax = sns.distplot(a=versicolor.sepal_length, ax=ax, kde=True, rug=True)
sns.distplot(a=virginica.sepal_length, ax=ax, kde=True, rug=True)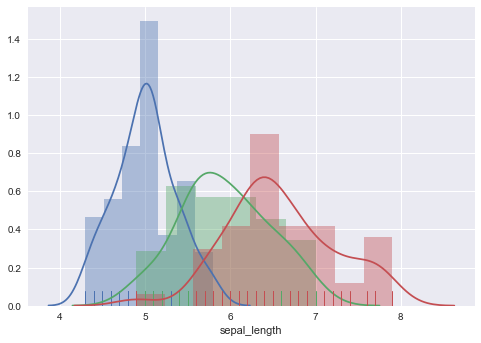
所感
基礎集計のとっかかりなど、分布の概観をつかめればよい段階ではpandas.DataFrame.hist()が気軽に呼び出せて便利という印象を受けました。次に簡易に呼び出せるのがpandas.DataFrame.plot()で、少し手間がかかるが痒いところに手が届くのがmatplotlib。seabornはプレゼンテーション用のイメージが強かったですが、書式もシンプルなのでぜひ普段から使っていきたいですね。
参考
DATUM STUDIOでは様々なAI/機械学習のプロジェクトを行っております。
詳細につきましてはこちら
詳細/サービスについてのお問い合わせはこちら
このページをシェアする: