【Pythonで再現】DeepMindのDQNアルゴリズムを再現してみた
こんにちは。データムスタジオの林です。プログラミングで一番嬉しい瞬間は、書いたコードがうまく動いた時だと思います。
さて、世界最強の囲碁棋士も敵わない、Google DeepMindが開発したAlphaGoは、ご存知のこととは思われますが、AlphaGoが世界的な成功を収める前に、同社が初めて世間の注目を集めた論文、皆さんご存知でしょうか?
それは2015年にNatureに掲載された「Human-level control through deep reinforcement learning」です。同論文と続編では、deep Q-network (DQN)という革新的な強化学習手法により、人工知能エージェントをAtari 2600ゲーム機の殆どのソフトで人間レベルのパフォーマンスを得られるように学習させたらしいです。
今回はこの論文が示したDQNアルゴリズムをPythonで再現し、そしてOpenAIによるgym環境のエージェントを自動的に学習させたいと思います。
では、早速始めましょう!
目次
0. 強化学習の中心概念
強化学習の中心概念は「エージェント」「環境」「状態」「行動」「報酬」の五つとなります。
教師あり学習と違い、強化学習の学び方は与えられた訓練データを通じるではなく、「エージェント」が「環境」とインタラクトする中で積み重ねた経験より最適方策を練っていくのです。つもり、
ある環境におけるエージェントが状態$latex s_{1}$に対して行動$latex a$をし、その行動の結果として報酬$latex r$を得るのと同時に、環境の状態も行動$latex a$により状態$latex s_{2}$に変化していく
というステップの繰り返しです。こういう過去ステップを基に、長期的な報酬を最大化できる方策(各状態における最適行動)を学習するのが強化学習の目標です。
1. DQNの主要素
DQNアルゴリズムはQ-learningという強化学習手法の変種です。従来Q-learningとの違いが二つあります:
1.1 Q-Network
Q-learningアルゴリズムでは下記のような、Q-tableという行列で方策を表します:
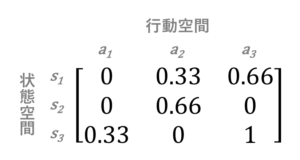
ここで各行、列がそれぞれ状態、行動に対応しており、値が各状態において各行動を取った場合の期待報酬です。
しかし、Q-tableでは連続な状態空間或いは行動空間に対応出来ないため、DQNはディープランニングを導入し、有限個の報酬ではなく、ニューラルネットワークに$latex Q:S\times A\to\mathbb{R}$関数を近似する役割を与えています。あらゆる$latex (s, a)$順序対に対して報酬を予測するこのネットワークはQ-networkと言います。
1.2 経験再生(experience replay)
更に、ゲームの流れが連続なので、各状態が前の状態と強く相関していることが多いです。ゆえに、Q-networkを学習時、確率的勾配降下法を類似しているサンプルにフィットさせると、局所的最小値に落ちてしまう恐れがあるらしいです。なので、ゲーム中続々発生したステップを順番に学習させるではなく、まずメモリに保存し、そしてランダムに抽出したサンプルにフィットさせるのです。この仕組みは経験再生と言います。
2. gym環境紹介
強化学習アルゴリズムをテストするのに環境が必要です。今回使うgymはOpenAlによる、強化学習アルゴリズム開発、テスト用のゲームのような環境です。gymをインストールするには
$ pip install gym
を実行します。
インストールが済んだらエージェントを動かせてみましょう。例えば、ランダムエージェントにCartPoleゲームを遊ばせるコードは:
import gym
# CartPole環境を作成
env = gym.make('CartPole-v1')
# 環境を初期化
env.reset()
while True:
# 画像を表示
env.render()
# 行動空間からランダムに行動を抽出
action = env.action_space.sample()
# エージェントに抽出した行動を取らせる
env.step(action)CartPole環境の学習目標は、車を左右移動して上に棒を立てることです。上記ランダムエージェントコードを実行すると、このように動きます:
すぐ倒れてしまいました。さすがにランダム行動ではクリア出来るはずがないです。
ということで、強化学習でチャレンジしましょう!
3. DQNを実装
論文に記述された擬似コードは下記の通りです:

この記事では大体擬似コードのままで再現しますが、DeepMindの使った畳み込みニューラルネットワークの代わりに、普通のフィードフォワードニューラルネットワークを採用しています。その理由は二つあります:
gym環境において、状態はAtariゲームのようなピクセルではなく、実数の順序対で表されています。
なので、画像認識の分野で優れた畳み込みニューラルネットワークを使う必要がありません。- 学習時間短縮のため。
3.1 Q-Network(ディープランニング)
def _build_network(self):
nn = Sequential()
nn.add(Dense(20, activation='relu',
input_dim=(self.agent_hist_len
* self.env.observation_space.shape[0])))
nn.add(Dense(20, activation='relu'))
nn.add(Dense(10, activation='relu'))
nn.add(Dense(self.env.action_space.n))
nn.compile(optimizer='adam', loss='mse', metrics=['mae'])
return nn
def _clone_network(self, nn):
clone = self._build_network()
clone.set_weights(nn.get_weights())
return cloneまずはQ-networkを作成する関数を定義します。ここで_build_network()は初期ニューラルネットワークを作成します。そして_clone_network()の役割は一定周期でフィットしたQ-networkウェートで目標Q-network(アルゴリズムにおける$latex \hat{Q}$)のウェートを上書きます。
3.2 最適行動
@staticmethod
def _flatten_deque(d):
return np.array(list(chain(*d)))
def _get_optimal_action(self, network, agent_hist):
agent_hist_normalized = self.scaler.transform(
self._flatten_deque(agent_hist).reshape(1, -1))
return np.argmax(network.predict(agent_hist_normalized)[0])
def _get_action(self, agent_hist=None):
if agent_hist is None:
return self.env.action_space.sample()
else:
self.eps = max(self.eps - self.eps_decay, self.eps_min)
if np.random.random() < self.eps:
return self.env.action_space.sample()
else:
return self._get_optimal_action(self.Q, agent_hist)次はエージェントの行動方策を決める関数です。_get_optimal_action()は単純にQ-networkによる予測報酬が最大の行動を返します。_get_action()は$latex \epsilon$-greedy方策を実装し、ステップが経つにつれ減衰する確率$latex \epsilon$で行動を探索してから、徐々に最適行動に寄り付きます。
3.3 メモリ
def _remember(self, agent_hist, action, reward, new_state, done):
self.memory.append([self._flatten_deque(agent_hist), action, reward,
new_state if not done else None])
def _init_memory(self):
print('Initializing replay memory: ', end='')
self.memory = deque(maxlen=self.memory_size)
while True:
state = self.env.reset()
agent_hist = deque(maxlen=self.agent_hist_len)
agent_hist.append(state)
while True:
action = self._get_action(agent_hist=None)
new_state, reward, done, _ = self.env.step(action)
if len(agent_hist) == self.agent_hist_len:
self._remember(agent_hist, action, reward, new_state, done)
if len(self.memory) == self.replay_start_size:
print('done')
return
if done:
break
state = new_state
agent_hist.append(state)こちらはエージェントのメモリに当たります。_remember()関数でエージェントに経験したステップを覚えさせることが出来ます。_init_memory()は学習開始時繰り返して_remember()を呼び出し、ランダムに初期メモリを作成します。
3.4 経験再生
def _get_samples(self):
samples = random.sample(self.memory, self.mb_size)
agent_hists = np.array([s[0] for s in samples])
Y = self.target_Q.predict(self.scaler.transform(agent_hists))
actions = [s[1] for s in samples]
rewards = np.array([s[2] for s in samples])
future_rewards = np.zeros(self.mb_size)
new_states_idx = [i for i, s in enumerate(samples) if s[3] is not None]
new_states = np.array([s[3] for s in itemgetter(*new_states_idx)(samples)])
new_agent_hists = np.hstack(
[agent_hists[new_states_idx, self.env.observation_space.shape[0]:],
new_states])
future_rewards[new_states_idx] = np.max(
self.target_Q.predict(self.scaler.transform(new_agent_hists)), axis=1)
rewards += self.gamma*future_rewards
for i, r in enumerate(Y):
Y[i, actions[i]] = rewards[i]
return agent_hists, Y
def _replay(self):
agent_hists, Y = self._get_samples()
agent_hists_normalized = self.scaler.transform(agent_hists)
for i in range(self.mb_size):
self.Q.train_on_batch(agent_hists_normalized[i, :].reshape(1, -1),
Y[i, :].reshape(1, -1))いよいよ最も面白い部分に入りました。ここで_get_samples()はエージェントのメモリからサンプルを抽出し、サンプル別に即時報酬に最大遅延報酬を足します。それから、_get_samples()に基づいて、_replay()は抽出したサンプルと報酬にQ-networkをフィットさせます。
3.5 学習させる
では、全ての要素を組み合わせましょう:
import os
import gym
import time
import random
import pickle
import numpy as np
import pandas as pd
from itertools import chain
from collections import deque
from operator import itemgetter
from sklearn.preprocessing import StandardScaler
from keras.models import Sequential, load_model
from keras.layers import Dense
import matplotlib.pyplot as plt
plt.style.use('seaborn')
plt.rcParams['font.family'] = 'IPAexGothic'
class DQN(object):
def __init__(self, env_id, agent_hist_len=4, memory_size=2000,
replay_start_size=32, gamma=0.99, eps=1.0, eps_min=1e-4,
final_expl_step=1000, mb_size=32, C=100, n_episodes=400,
max_steps=500):
self.env_id = env_id
self.env = gym.make(env_id)
self.path = './data/' + env_id
self.agent_hist_len = agent_hist_len
self.memory_size = memory_size
self.replay_start_size = replay_start_size
self.gamma = gamma
self.eps = eps
self.eps_min = eps_min
self.final_expl_step = final_expl_step
self.eps_decay = (eps-eps_min) / final_expl_step
self.mb_size = mb_size
self.C = C
self.n_episodes = n_episodes
self.max_steps = max_steps
self._init_memory()
self.scaler = StandardScaler()
self.scaler.fit(np.array([t[0] for t in self.memory]))
@staticmethod
def _flatten_deque(d):
return np.array(list(chain(*d)))
def _get_optimal_action(self, network, agent_hist):
agent_hist_normalized = self.scaler.transform(
self._flatten_deque(agent_hist).reshape(1, -1))
return np.argmax(network.predict(agent_hist_normalized)[0])
def _get_action(self, agent_hist=None):
if agent_hist is None:
return self.env.action_space.sample()
else:
self.eps = max(self.eps - self.eps_decay, self.eps_min)
if np.random.random() < self.eps:
return self.env.action_space.sample()
else:
return self._get_optimal_action(self.Q, agent_hist)
def _remember(self, agent_hist, action, reward, new_state, done):
self.memory.append([self._flatten_deque(agent_hist), action, reward,
new_state if not done else None])
def _init_memory(self):
print('Initializing replay memory: ', end='')
self.memory = deque(maxlen=self.memory_size)
while True:
state = self.env.reset()
agent_hist = deque(maxlen=self.agent_hist_len)
agent_hist.append(state)
while True:
action = self._get_action(agent_hist=None)
new_state, reward, done, _ = self.env.step(action)
if len(agent_hist) == self.agent_hist_len:
self._remember(agent_hist, action, reward, new_state, done)
if len(self.memory) == self.replay_start_size:
print('done')
return
if done:
break
state = new_state
agent_hist.append(state)
def _build_network(self):
nn = Sequential()
nn.add(Dense(20, activation='relu',
input_dim=(self.agent_hist_len
* self.env.observation_space.shape[0])))
nn.add(Dense(20, activation='relu'))
nn.add(Dense(10, activation='relu'))
nn.add(Dense(self.env.action_space.n))
nn.compile(optimizer='adam', loss='mse', metrics=['mae'])
return nn
def _clone_network(self, nn):
clone = self._build_network()
clone.set_weights(nn.get_weights())
return clone
def _get_samples(self):
samples = random.sample(self.memory, self.mb_size)
agent_hists = np.array([s[0] for s in samples])
Y = self.target_Q.predict(self.scaler.transform(agent_hists))
actions = [s[1] for s in samples]
rewards = np.array([s[2] for s in samples])
future_rewards = np.zeros(self.mb_size)
new_states_idx = [i for i, s in enumerate(samples) if s[3] is not None]
new_states = np.array([s[3] for s in itemgetter(*new_states_idx)(samples)])
new_agent_hists = np.hstack(
[agent_hists[new_states_idx, self.env.observation_space.shape[0]:],
new_states])
future_rewards[new_states_idx] = np.max(
self.target_Q.predict(self.scaler.transform(new_agent_hists)), axis=1)
rewards += self.gamma*future_rewards
for i, r in enumerate(Y):
Y[i, actions[i]] = rewards[i]
return agent_hists, Y
def _replay(self):
agent_hists, Y = self._get_samples()
agent_hists_normalized = self.scaler.transform(agent_hists)
for i in range(self.mb_size):
self.Q.train_on_batch(agent_hists_normalized[i, :].reshape(1, -1),
Y[i, :].reshape(1, -1))
def learn(self, render=False, verbose=True):
self.Q = self._build_network()
self.target_Q = self._clone_network(self.Q)
if verbose:
print('Learning target network:')
self.scores = []
for episode in range(self.n_episodes):
state = self.env.reset()
agent_hist = deque(maxlen=self.agent_hist_len)
agent_hist.append(state)
score = 0
for step in range(self.max_steps):
if render:
self.env.render()
if len(agent_hist) < self.agent_hist_len:
action = self._get_action(agent_hist=None)
else:
action = self._get_action(agent_hist)
new_state, reward, done, _ = self.env.step(action)
if verbose:
print('episode: {:4} | step: {:3} | memory: {:6} | \
eps: {:.4f} | action: {} | reward: {: .1f} | best score: {: 6.1f} | \
mean score: {: 6.1f}'.format(
episode+1, step+1, len(self.memory), self.eps, action, reward,
max(self.scores) if len(self.scores) != 0 else np.nan,
np.mean(self.scores) if len(self.scores) != 0 else np.nan),
end='\r')
score += reward
if len(agent_hist) == self.agent_hist_len:
self._remember(agent_hist, action, reward, new_state, done)
self._replay()
if step % self.C == 0:
self.target_Q = self._clone_network(self.Q)
if done:
self.scores.append(score)
break
state = new_state
agent_hist.append(state)
self.target_Q.save(self.path + '_model.h5')
with open(self.path + '_scores.pkl', 'wb') as f:
pickle.dump(self.scores, f)
def plot_training_scores(self):
with open(self.path + '_scores.pkl', 'rb') as f:
scores = pd.Series(pickle.load(f))
avg_scores = scores.cumsum() / (scores.index + 1)
plt.figure(figsize=(12, 6))
n_scores = len(scores)
plt.plot(range(n_scores), scores, color='gray', linewidth=1)
plt.plot(range(n_scores), avg_scores, label='平均')
plt.legend()
plt.xlabel('学習エピソード')
plt.ylabel('スコア')
plt.title(self.env_id)
plt.margins(0.02)
plt.tight_layout()
plt.show()
def run(self, render=True):
fname = self.path + '_model.h5'
if os.path.exists(fname):
self.target_Q = load_model(fname)
else:
print('Q-network not found. Start learning.')
self.learn()
state = self.env.reset()
agent_hist = deque(maxlen=self.agent_hist_len)
agent_hist.extend([state]*self.agent_hist_len)
score = 0
while True:
if render:
self.env.render()
action = self._get_optimal_action(self.target_Q, agent_hist)
new_state, reward, done, _ = self.env.step(action)
score += reward
if done:
print('{} score: {}'.format(self.env_id, score))
return
state = new_state
agent_hist.append(state)
time.sleep(0.05)DQNオブジェクトを作成し、learn()メソッドを呼び出すと、学習が始まります。
dqn = DQN('CartPole-v1')
dqn.learn()4. 学習結果検証
学習過程を観察するため、上記クラスにplot_training_scores()メソッドも加えました。
学習後にplot_training_scores()を呼び出すと、エージェントの各学習エピソードにおけるスコア(灰)と平均スコア(青)が示されます。
dqn.plot_training_scores()
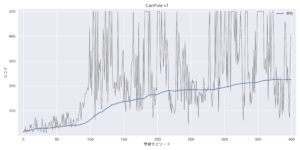
平均スコアが徐々に上がっていくのが、アルゴリズムがうまく動いていたことの証です。ちなみに、CartPole環境の最大ステップ数が500のため、最高スコアも500点です。
最後に、学習したQ-networkでCartPoleを遊ばせてみましょう:
dqn.run()
CartPole-v1 score: 500.0
見事にバランスを保って、最高スコアを得られました。
5. まとめ
いかがでしょうか。今回はDeepMindのDQNアルゴリズムをPythonで再現し、gym環境にてテストしました。DQNでは見事に訓練データなしでクリア出来ました。さすがDeepMindと思います。
では、また次回!
6. 参考文献
・Human-level control through deep reinforcement learning
・https://deepmind.com/blog/deep-reinforcement-learning/
このページをシェアする: