Azure HDInsight で PySpark入門
はじめに
他のエンジニアから引き継いだコードがある日突然エラーを吐くようになった・・・そしてコードを解読してデバッグ、というのはよくある話かと思われます。私もこの例にもれず、先輩エンジニアから引き継いだレコメンドエンジンが突然エラーを吐くようなったことがあります。
この時エラーを吐いたのが、PySpark で書かれた ALS というモデルでした。まだ未熟だった私はそもそも ALS がわからない & Spark 独自の記法に翻弄され、ほんと沖縄あたりに逃げ出したくなった思い出深い奴らです、 PySpark と ALS。
その時本当に困ったのは、① PySpark の実行環境を作る手間と、②(デバッグしづらい)ターミナル画面で作業しなければならないことでした。
この記事では、この①、②を解消してくれる、Azure HDInsight を使い、 PySpark で簡単なレコメンドエンジンを作成していきます。
Azure HDInsight で PySpark の実行環境を作成する
Azure HDInsight とはそもそも何であるか、については使い方も含めこちらの記事をご参考にしてください。
HDInsight クラスターを構築していきます。
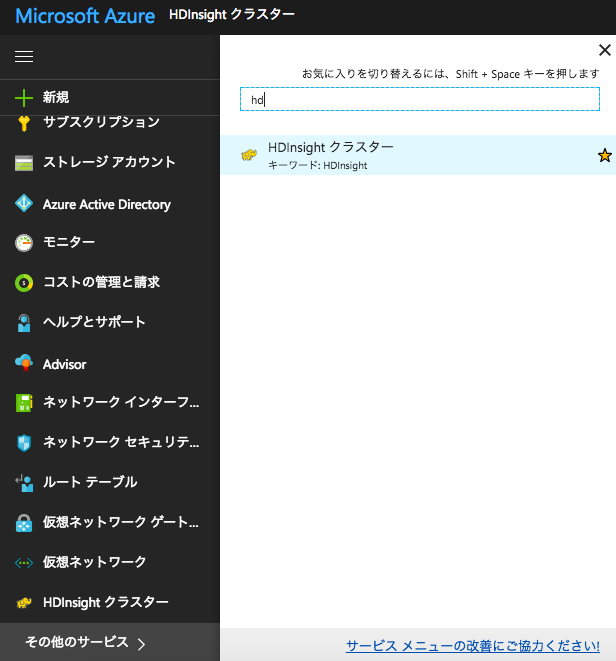
HDInsight クラスターはデフォルトではコンソール画面左端のサービス一覧に表示されませんので、「その他のサービス」→ 「hd」と入力し、「HDInsightクラスター」を選択してください。
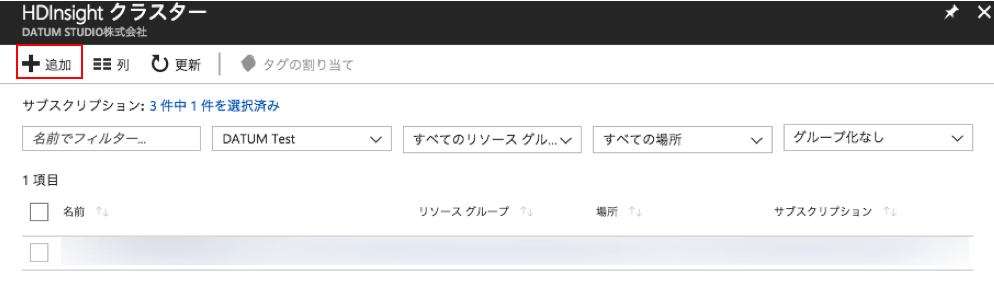
HDInsight クラスターの概要パネルが開きますので、上部にある「追加」をクリックしてください。クラスタの基本設定に進みます。
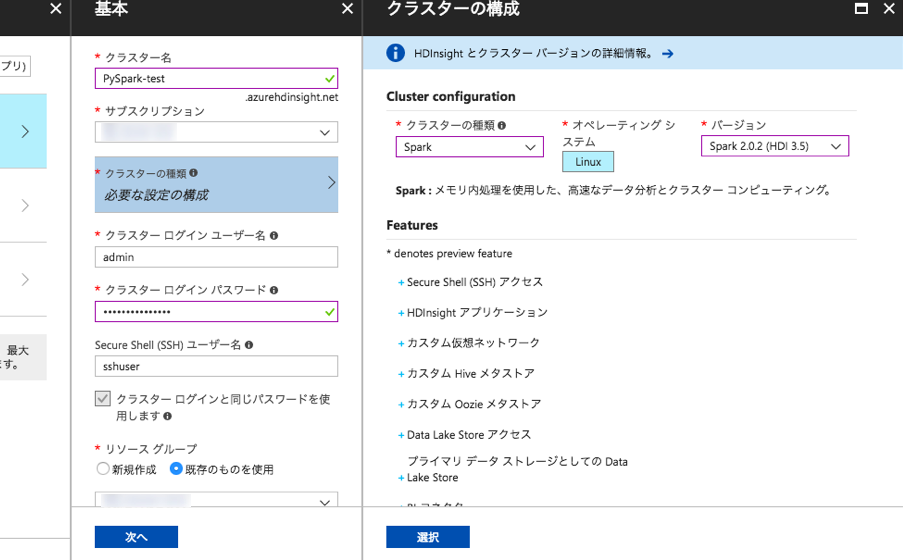
クラスター名は「PySpark-test」、クラスターの種類は「Spark」、Spark のバージョンは「Spark2.0.2 (HDI 3.5)」、オペレーションシステムは「Linux」を選択してください。それ以外の項目はデフォルトのままで大丈夫です。
ただ、パスワードについては一度どこかにメモしたものを、入力ボックスにコピペして設定するのが良いかもしれません。通常は確認用に2回入力させるものですが、クラスタ設定の際には一度きりです。間違ったパスワードを打ち込んでいても確認することができません。間違えた場合、あとで設定し直すことになるので面倒です。
次のストレージ設定は、作成済みのストレージアカウントを、なければ新規作成でOKです。
続いてクラスタサイズの編集です。
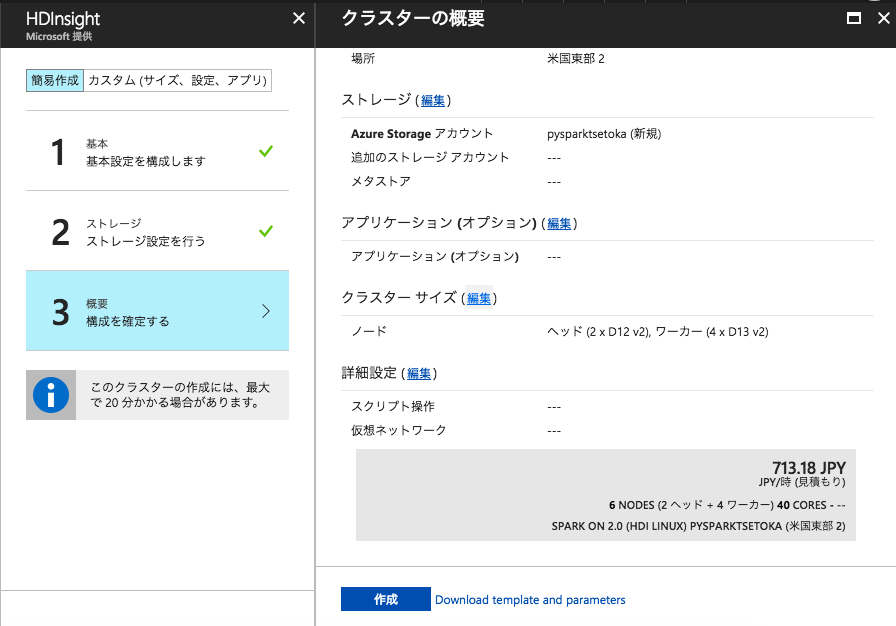
ここで「作成」ボタンを押さずに、クラスターサイズの編集を行いましょう。今回は練習ですので、デフォルトのクラスターサイズ使ってしまうとコストがかさみます。
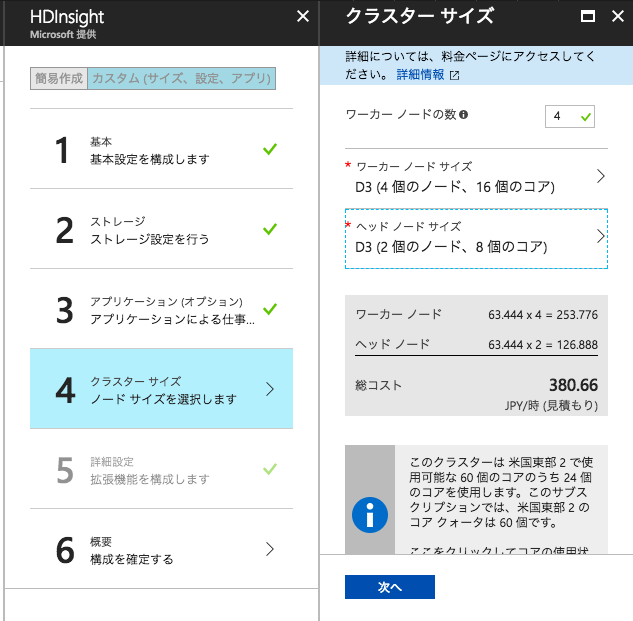
ここでは、ワーカーノード、ヘッダーノード共にD3を選択しました。それ以降の設定はデフォルトのままで大丈夫です。構成を確認してクラスタの作成を実行してください。
クラスタの作成ができましたら、接続して動作確認をします。HDInsight では、起動したクラスタ上で Jupyter notebook からインタラクティブに PySpark を扱うことができます。Jupyter notebook にアクセスしてみましょう。
以下は起動した クラスターの概要パネルです。

「クラスターダッシュボード」を選択し、次ページで「Jupyter notebook」のパネルを選択します。
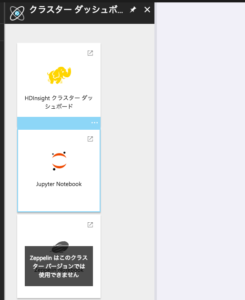
するとWebブラウザに以下ログイン画面が現れるので、ユーザーは「admin」で、先ほど設定したパスワードを入力しましょう。
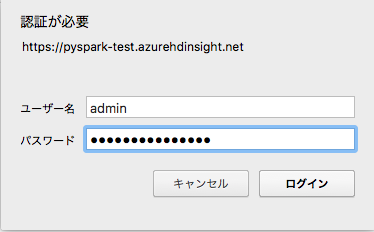
ログインに成功すると、以下のような Jupyter Notebookの画面にアクセスできます。
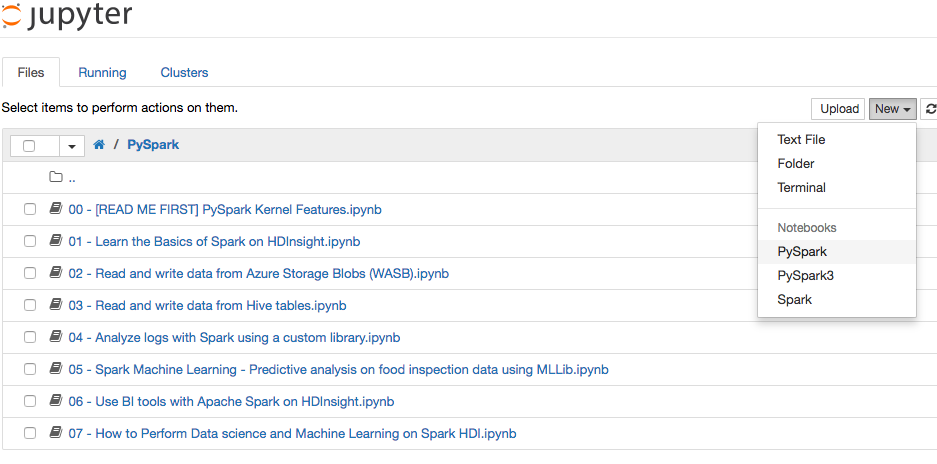
次章では、このJupyter 上の 「New」から「PySpark」ファイルを作成し、そこからインタラクティブにPySparkを扱います。
PySpark で ALS によるレコメンデーションを行う
レコメンデーションの手法の一つに、ALSによる協調フィルタリングというものがあります。これについては下記URLが参考になります。
このALS によるレコメンドをPySpark で試してみましょう。題材は、Sparkに同梱されているサンプルの MovieLens という映画のレビュー情報のデータがあるのでこれを用いて、映画のレコメンデーションを行います。
先ほど立ち上げた HDInsight の Jupyter notebook上で「PySpark」の新規ファイルを立ち上げ、以下のコードを実行していきます。
import os, sys
import pandas as pd
import numpy as np
import time
spark_home = "/usr/hdp/current/spark2-client"
# Sampleデータの読み込み
df = pd.read_csv(os.path.join(spark_home, 'data/mllib/als/sample_movielens_ratings.txt'),
delimiter='::', names=('uid', 'iid', 'rating','time'),engine='python')
# データの中身を確認
df.head(10)最初のコマンドを実行すると、以下の画面のようにSpark のセッションがスタートします。
読み込んだデータの中身は以下のようになっております。
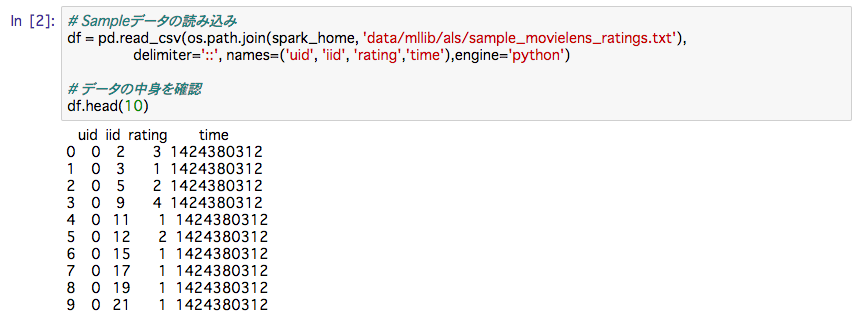
uidはユーザーID, iidはアイテム(映画)ID、中のデータはユーザーごとの映画のレビュー得点です。
続いて、訓練データの整形を行います。
from pyspark import SparkContext
from pyspark.mllib.recommendation import ALS, Rating
sc = SparkContext.getOrCreate()
# pandas.DataFrame を pyspark.rdd.RDD に変換
sc_rating = sc.parallelize(df.as_matrix())
# ユーザーID と アイテム(映画)ID、を int型に、映画の rating を float型に変換し、
# Ratingで ["user", "product", "rating"]の名前付きタプルへ変換
ratingsRDD = sc_rating.map(lambda l: Rating(int(l[0]), int(l[1]), float(l[2])))
# 訓練データとテストデータに分割
trainingRDD, testRDD = ratingsRDD.randomSplit([7, 3], seed=123)
# レコード数の確認
print "trainingRDD has {}reocrds.".format(trainingRDD.count())
print "testRDD has {}reocrds.".format(testRDD.count())「RDD」は耐障害性分散データセットと呼ばれ、繰り返し利用するデータをメモリ上に保持します。Apache Spark では、この RDD にデータを保持して操作します。「sc」は pyspark の RDD 型を利用するために必要なインスタンスです。sc.parallelize()はリストやタプルから RDD を作成します。sc_rating.take(10) で df.head(10) のような操作ができます。
Rating の挙動についてはソースコードがシンプルなので、公式ドキュメントを読むと良いでしょう。
次に ALS でモデルを作成します。
# ALS(Alternating Least Squares)でレコメンデーション
rank = 10
numIterations = 20
regularizationParameter = 0.1
# 学習時間も計測する
start = time.time()
model = ALS.train(
ratings=trainingRDD,
rank=rank,
iterations=numIterations,
lambda_=regularizationParameter,
seed=123)
elapsed_time = time.time() - start
print "elapsed_time:{}".format(elapsed_time) + "[sec]"ついでに、モデル作成部分の処理時間を計測しましたが、HDInsight での処理時間は7秒ほどでした。ちなみにこのコードをローカルマシン( MacOS )で実行すると3分ほどかかったので、差は歴然です。
続いて、3割で残しておいたテストデータでモデルの精度を確認します。
# 精度の計算
def limitter(x):
if x > 5: # 5以上の値は5とする
return 5
elif x < 0: # マイナスの値は0とする
return 0
else:
return x
testdata = testRDD.map(lambda p: (p[0], p[1]))
predictions = model.predictAll(testdata).map(lambda r: ((r[0], r[1]), limitter(r[2]) ))
ratesAndPreds = testRDD.map(lambda r: ((r[0], r[1]), r[2] )).join(predictions)
MSE = ratesAndPreds.map(lambda r: (r[1][0] - r[1][1])**2).mean()
print("Mean Squared Error = " + str(MSE))結果は下記のようになりました。
Mean Squared Error = 1.05163372995
最後に実測値と予測値を散布図で可視化してみましょう。この Jupyter 上でグラフを可視化するには、以下のような独特な操作を行います。
# 予測と実測値の値を一時テーブルとして登録
act_pred_df = spark.createDataFrame(ratesAndPreds.map(lambda r: (r[1][0], r[1][1])), ['act', 'pred'])
act_pred_df.registerTempTable('ActPredDF')まず、可視化したい「act_pred_df」を「ActPredDF」という名前の一時テーブルとして登録します。また、続きの処理は notebook のセルを分けて実行していきます。
%%sql -o act_pred_result SELECT * FROM ActPredDF
%%sql というマジックコマンドで先ほど登録した「ActPredDF」を SQLライクに取り出せます。また「-o act_pred_result」という引数により、クエリの結果を「act_pred_result」に pandas.DataFrame 形式で格納します。
最後に下記を実行してプロットを出力できます。
%matplotlib inline act_pred_result.plot(kind='scatter', x='pred', y='act')
このあたりの可視化の方法は、PySpark 内のサンプルコードから読み解いただけなので、記述に誤りなどあるかもしれません。
出力結果は以下になります。
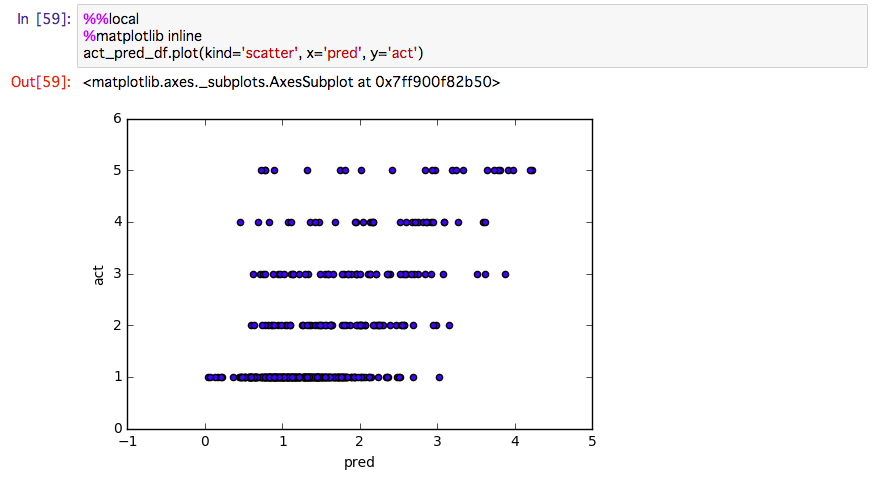
まとめ
通常 PySpark を利用するには、まず Spark のセットアップが必要です。その上、Jupyter notebook 上で動かそうとなると、さらに環境構築の手間がかかります。
Azure HDInsight はそういった環境構築の煩わしさを解消し、さらに Jupyter notebook 上で Spark や Hadoop といった分散処理システムを気軽に動かせるため、分析サイクルを高速に回すことができます。
今回は学習データが1500件程度でしたが、実際のデータ分析においては数十万件のデータを扱うことが珍しくありません。そういった大規模データで ALS のような計算不可の大きいモデリングをするときに、HDInsight のようなサービスが必要不可欠になるでしょう。
最後までお読みいただきありがとうございました。
このページをシェアする: