Azure GPU × Chainer で深層学習
経緯
ある日、私が社内で作業しているところに 弊社 CTO が嬉々として近づき 、私のPCにこんなシール↓を貼っていきました。

いや、僕 Azure で〇〇ラーニングとかしたこと無いし、Chainer も 使ったことないんだけどなぁ。。。
と言うと、そこは CTO「じゃあ使えるようになればいいんですよ」という強引な解決策を残して去っていきました。
そんな経緯があって私は、PCに貼られた「 Azure × Chainer 」が使えるナイスなエンジニアを目指すことになりました。
でなきゃこのシール、ただのハッタリ
というわけで修行の成果を披露すべく、この記事で紹介するのは以下の3つです。
1. Azure の GPU 搭載 VMの起動方法
2. Chainer を用いた深層学習を “GPU” で行う方法
3. GPUインスタンスと 非GPUのローカルマシン(MacOS)との学習速度の比較
逆にこの記事で話さない事は以下の項目です。
1. そもそもの深層学習とかCNNの理論
2. Chainer の詳細なコード解説
1. Azure の GPU搭載 VM を起動する
公式のチュートリアルを参考にしています。もともと想定していたのは、
1. GPU インスタンス起動
2. 1のインスタンスにpyenv, anaconda3 などpython実行環境の構築
3. Cuda Driver など、GPUを使えるようにセットアップ
だったのですが、2と3 の要件を満たす深層学習に適したVMイメージが提供されていたので、そちらを利用します。
1-1. GPU インスタンスの起動
まずは、GPUインスタンスを作成していきます。
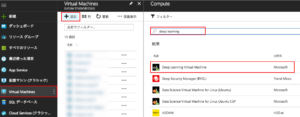
左端の「Virtual Machines」 をクリックして、仮想マシンの一覧を開いたら、上部の「追加」をクリックします。マシンイメージの選択画面が開くので「deep learning」で検索し、「Deep Learning Virtual Machine」を選択してください。
続いて基本設定です。
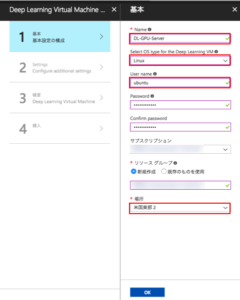
Nameは「DL-GPU-Server」とし、OS type は 「Linux」、User name は 「ubuntu」としました。場所は、「米国東部2」を選択しました。地域によってはGPU インスタンスが利用できませんので、ご注意ください。
最後にサイズ選択です。
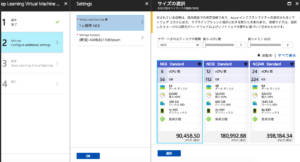
今回は練習ですので、NC6 Standardを選択してください。Storage Accountはデフォルト新規されるものをそのまま利用する形で大丈夫です。
次の画面で検証に成功したら、インスタンスを作成してください。
1-2. セキュリティグループの 受信セキュリティ 設定
じつはこのインスタンスですが、デフォルトでSSHやJupyterhubのポートに全IPからのアクセスが可能になっています。
以下は、作成したインスタンスの受信セキュリティ設定の画面です。

今回のような「Deep Learning Virtual Machine」のマシンイメージから作成となると、設定時点ではSSH公開鍵の登録ができず、ユーザ名とパスワードでの認証となります。
そのうえ全IPからのアクセスを許可してしまうのはセキュリティ上良くないので、任意のIPアドレス範囲からのみアクセスできるように設定しましょう。

・default-allow-ssh
・default-allow-jupyterhub
・default-allow-rstudio-server
の3つについて、ソースを「IP Addresses」に変更し、ソースIPアドレス/CIDR 範囲に特定のIPアドレス範囲(例えば自宅とか、会社のもの)を入力してください。
1.3 jupyterhub の起動確認
さきほど設定した受信セキュリティを見ると、デフォルトでRstudio ServerとJupyterhubのポートが空いています。
今回は chianer をpythonで書いていくので、jupyterhub にアクセスできるか確認していきます。
「https://GPU インスタンスのグローバルIP:8000 」でWebブラウザからアクセスします。
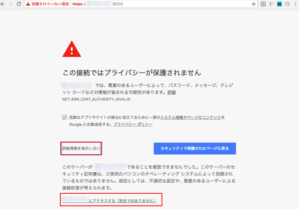
という警告が出ますが、TLS証明書を設定してないためです。気になる方はあとで証明書を設定すれば良いので、今回は無視して、「詳細設定」→「 xxxxにアクセスする」をクリックしていけば大丈夫です。
続いてログイン画面です。
インスタンスの基本設定のところで設定したユーザ名とパスワードを入力してください。ログインに成功したら「Start My Server」を選択してください。
以上で動作確認は終了です。
GPUインスタンスの準備までびっっくりするぐらい手間がかからなかったですね。本体なら、立てたインスタンスにPython 入れて、Cuda Driver 入れて・・・という作業を思えば雲泥の差です。
2. Chainer を用いた深層学習を GPU で行う
続いて、実際にChainer のコードを動かしてみます。Chainer は
2-1. Chainer でニューラルネットの実装
MNISTデータセットを用いて、Chianerで手書き文字認識を試してみます。スクリプトは本家 Chianerのチュートリアルとこちらを参考にしております。
まずは簡単な全結合の3層ニューラルネットから(人によってはこれを2層と呼ぶかもしれませんが)
#-*- using:utf-8 -*-
import numpy as np
import chainer
from chainer import Variable
import chainer.functions as F
import chainer.links as L
import time
class ThreeLayerNet(chainer.Chain):
def __init__(self, n_units, n_out):
super().__init__(
# 全結合層は L.Linear で記述
l1=L.Linear(None, n_units),
l2=L.Linear(n_units, n_units),
l3=L.Linear(n_units, n_out),
)
# 伝播の処理、活性化関数の定義
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)
def check_accuracy_loss(model, xs, ts):
ys = model(xs)
loss = F.softmax_cross_entropy(ys, ts)
ys = np.argmax(ys.data, axis=1)
cors = (ys == ts)
num_cors = sum(cors)
accuracy = num_cors / ts.shape[0]
return accuracy, loss
def main():
model = ThreeLayerNet(50, 10)
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
# MNIST データセットの読み込み、初回だけダウンロード時間がかかります。
train, test = chainer.datasets.get_mnist()
xs, ts = train._datasets
txs, tts = test._datasets
# 6万件の学習データを600分割して、100件ずつ学習させる
batch_size = 100
train_size = xs.shape[0]
split_size = np.int(train_size / batch_size)
# 学習に要した時間を計測する
start = time.time()
for i in range(batch_size):
# for i in range(10):
for j in range(split_size):
# パラメータの勾配をゼロに初期化
model.cleargrads()
# ミニバッチの取得
batch_mask = np.random.choice(train_size, batch_size)
x = xs[batch_mask]
t = ts[batch_mask]
t = Variable(np.array(t, "i"))
# 学習
y = model(x)
# 交差エントロピー誤差計算
loss = F.softmax_cross_entropy(y, t)
# 誤差逆伝播法で勾配の計算
loss.backward()
# パラメーターの更新
optimizer.update()
accuracy_train, loss_train = check_accuracy_loss(model, xs, ts)
accuracy_test, _ = check_accuracy_loss(model, txs, tts)
print(
"Epoch {epoch_num} loss(train) = {loss_train}, accuracy(train) = {accuracy_train}, accuracy(test) = {accuracy_test}".format(
epoch_num=i + 1, loss_train=loss_train.data, accuracy_train=accuracy_train,
accuracy_test=accuracy_test))
elapsed_time = time.time() - start
print("elapsed_time:{0}".format(elapsed_time) + "[sec]")
if __name__ == '__main__':
main()ネットワークの定義部分は ThreeLayerNet クラスによって定義されています。
class ThreeLayerNet(chainer.Chain):
def __init__(self, n_units, n_out):
super().__init__(
# 全結合層は L.Linear で記述
l1=L.Linear(None, n_units),
l2=L.Linear(n_units, n_units),
l3=L.Linear(n_units, n_out),
)
# 活性化関数の定義
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)super().__init__で chianer.Chain の__init__メソッドを継承し、レイヤーのパラメタを定義し、実際のネットワーク構造は__call__にて記述します。
これをローカルマシンで実行します。マシンスペックは以下のようになっております。
・OS: Mac OS Sierra
・プロセッサ:1.6 GHz Intel Core i5
・メモリ:8 GB 1600 MHz DDR3
以下がローカルでの実行結果となります。
Epoch 1 loss(train) = 0.2115129679441452, accuracy(train) = 0.9392333333333334, accuracy(test) = 0.9396 Epoch 2 loss(train) = 0.1456599235534668, accuracy(train) = 0.95795, accuracy(test) = 0.9545 . . . Epoch 99 loss(train) = 0.0038083139806985855, accuracy(train) = 0.9989333333333333, accuracy(test) = 0.9725 Epoch 100 loss(train) = 0.007314713206142187, accuracy(train) = 0.9977333333333334, accuracy(test) = 0.9717 elapsed_time:330.16433095932007[sec]
エポックごとに学習結果が返されます。精度は 97% くらいで、処理時間は5分くらいです。
ローカルマシンでの実行でこの時間だったらGPUにするまでもなさそうです。
2-2. Chainer でCNNの実装
そんなわけで、より計算負荷の大きい CNN で試してみましょう。例えば、2つの畳込み層、2つのプーリング層であれば以下のようになります。
# -*- using:utf-8 -*-
import numpy as np
import chainer
import chainer.functions as F
import chainer.links as L
import time
from chainer import training
from chainer.training import extensions
# ネットワーク定義
class CNN(chainer.Chain):
def __init__(self, train=True):
# 各種パラメタ
super(CNN, self).__init__(
conv1=L.Convolution2D(1, 32, 5),
conv2=L.Convolution2D(32, 64, 5),
l1=L.Linear(1024, 10),
)
self.train = train
# ネットワーク構造は call 以下に記述
def __call__(self, x):
h = F.max_pooling_2d(F.relu(self.conv1(x)), 2)
h = F.max_pooling_2d(F.relu(self.conv2(h)), 2)
return self.l1(h)
def main():
model = L.Classifier(CNN())
# 更新手法を定義
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
# MNIST データセットの読み込み、初回のダウンロードだけ時間がかかります。
train, test = chainer.datasets.get_mnist(ndim=3)
train_iter = chainer.iterators.SerialIterator(train, batch_size=100)
test_iter = chainer.iterators.SerialIterator(test, batch_size=100, repeat=False, shuffle=False)
# パラメタ更新
updater = training.StandardUpdater(train_iter, optimizer, device=None)
trainer = training.Trainer(updater, (5, 'epoch'), out='result')
# 精度の評価
trainer.extend(extensions.Evaluator(test_iter, model, device=None))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'validation/main/loss', 'main/accuracy', 'validation/main/accuracy']))
# 計算の進捗報告してくれるメソッド。なけりゃ自分で作らなきゃな部分なので、こういうのあると嬉しい。
trainer.extend(extensions.ProgressBar())
# トータルの処理時間計算
start = time.time()
# 学習スタート
trainer.run()
elapsed_time = time.time() - start
print("elapsed_time:{0}".format(elapsed_time) + "[sec]")
if __name__ == '__main__':
main()全結合ニューラルネットの時と同じで、ネットーワーク構造とレイヤごとのパラメタは 冒頭の CNN クラスにて定義しています。
これをまずはローカルマシンで実行すると、実行結果は以下のようになります。
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy 1 0.175368 0.0518053 0.948667 0.9836 2 0.0510253 0.0414762 0.9844 0.9856 3 0.0362031 0.0368712 0.988533 0.9874 4 0.0276171 0.0296378 0.991533 0.9899 5 0.0220089 0.034934 0.992683 0.9887 elapsed_time:1056.6731357574463[sec]
大体 17分くらいかかって精度は 98% くらいです。次にこれを、GPUで動かすようにしてみましょう。
2-3. Chainer のコード を GPU で動かす
前節のコードをGPUで稼働させるには、以下のように変更します。
# -*- using:utf-8 -*-
import numpy as np
import chainer
import chainer.functions as F
import chainer.links as L
import time
from chainer import training
from chainer.training import extensions
# ネットワーク定義
class CNN(chainer.Chain):
def __init__(self, train=True):
# 各種パラメタ
super(CNN, self).__init__(
conv1=L.Convolution2D(1, 32, 5),
conv2=L.Convolution2D(32, 64, 5),
l1=L.Linear(1024, 10),
)
self.train = train
# ネットワーク構造は call 以下に記述
def __call__(self, x):
h = F.max_pooling_2d(F.relu(self.conv1(x)), 2)
h = F.max_pooling_2d(F.relu(self.conv2(h)), 2)
return self.l1(h)
def main():
model = L.Classifier(CNN())
# GPU対応にする
get_device = 0
chainer.cuda.get_device(get_device).use()
model.to_gpu()
# 更新手法を定義
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
# MNIST データセットの読み込み、初回のダウンロードだけ時間がかかります。
train, test = chainer.datasets.get_mnist(ndim=3)
train_iter = chainer.iterators.SerialIterator(train, batch_size=100)
test_iter = chainer.iterators.SerialIterator(test, batch_size=100, repeat=False, shuffle=False)
# パラメタ更新
# device引数に0を指定する
updater = training.StandardUpdater(train_iter, optimizer, device=get_device)
trainer = training.Trainer(updater, (5, 'epoch'), out='result')
# 精度の評価
# device引数に0を指定する
trainer.extend(extensions.Evaluator(test_iter, model, device=get_device))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'validation/main/loss', 'main/accuracy', 'validation/main/accuracy']))
# 計算の進捗報告してくれるメソッド。
trainer.extend(extensions.ProgressBar())
# トータルの処理時間計算
start = time.time()
# 学習スタート
trainer.run()
elapsed_time = time.time() - start
print("elapsed_time:{0}".format(elapsed_time) + "[sec]")
if __name__ == '__main__':
main()変更点としては、35~37行目でモデルにGPUをセットし、
# GPU対応にする
get_device = 0
chainer.cuda.get_device(get_device).use()
model.to_gpu()51行目と56行目でdevice 引数に0 (コード中では get_device に格納している) を指定しています。
# device引数に0を指定する
updater = training.StandardUpdater(train_iter, optimizer, device=get_device)
trainer = training.Trainer(updater, (5, 'epoch'), out='result')
# 精度の評価
# device引数に0を指定する
trainer.extend(extensions.Evaluator(test_iter, model, device=get_device))これを先ほど作成した GPU インスタンスで実行すると
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy 1 0.174103 0.0546844 0.947899 0.9821 2 0.0502047 0.0351247 0.984382 0.9884 3 0.0343665 0.0371531 0.989482 0.9881 4 0.025997 0.0309685 0.991699 0.9896 5 0.0202872 0.0276465 0.993432 0.99 elapsed_time:35.188849210739136[sec]
35秒に短縮!
3. GPUとローカルマシンで速度比較
さて、さきほどは 17分 → 35秒 の短縮結果でしたが、これならまだローカルで実行して我慢できるレベルです。
次はもっと層を深くして実行してみましょう。
3-1. CNN の層を深くして実行
まずはローカルマシン、GPU なしで測定してみます。実行したのは以下のコードです。
# -*- using:utf-8 -*-
import chainer
import chainer.functions as F
import chainer.links as L
import time
from chainer import training
from chainer.training import extensions
# ネットワーク定義
class CNN(chainer.Chain):
def __init__(self, class_labels=10, train=True):
super(CNN, self).__init__(
conv1_1=L.Convolution2D(None, 16, ksize=5, pad=2, nobias=True),
conv1_2=L.Convolution2D(None, 16, ksize=5, pad=2, nobias=True),
conv2_1=L.Convolution2D(None, 32, ksize=3, pad=1, nobias=True),
conv2_2=L.Convolution2D(None, 32, ksize=3, pad=1, nobias=True),
fc1=L.Linear(None, 512, nobias=True),
fc2=L.Linear(None, class_labels, nobias=True),
)
self.train = train
def __call__(self, x):
conv1_1 = self.conv1_1(x)
conv1_1 = F.relu(conv1_1)
conv1_2 = self.conv1_2(conv1_1)
conv1_2 = F.relu(conv1_2)
pool1 = F.max_pooling_2d(conv1_2, ksize=2, stride=2)
conv2_1 = self.conv2_1(pool1)
conv2_1 = F.relu(conv2_1)
conv2_2 = self.conv2_2(conv2_1)
conv2_2 = F.relu(conv2_2)
pool2 = F.max_pooling_2d(conv2_2, ksize=2, stride=2)
fc1 = self.fc1(pool2)
fc1 = F.relu(fc1)
fc2 = self.fc2(fc1)
return fc2
def main():
model = L.Classifier(CNN())
# 更新手法の定義
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
# MNIST 読み込み
train, test = chainer.datasets.get_mnist(ndim=3)
train_iter = chainer.iterators.SerialIterator(train, batch_size=100)
test_iter = chainer.iterators.SerialIterator(test, batch_size=100, repeat=False, shuffle=False)
updater = training.StandardUpdater(train_iter, optimizer, device=None)
trainer = training.Trainer(updater, (5, 'epoch'), out='result')
trainer.extend(extensions.Evaluator(test_iter, model, device=None))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'validation/main/loss', 'main/accuracy', 'validation/main/accuracy']))
# 計算の進捗報告してくれるメソッド
trainer.extend(extensions.ProgressBar())
# トータルの処理時間計算
start = time.time()
# 学習スタート
trainer.run()
elapsed_time = time.time() - start
print("elapsed_time:{0}".format(elapsed_time) + "[sec]")
if __name__ == '__main__':
main()前節のコードから変更したのは CNN クラスの部分のみです。
class CNN(chainer.Chain):
def __init__(self, class_labels=10, train=True):
super(CNN, self).__init__(
conv1_1=L.Convolution2D(None, 16, ksize=5, pad=2, nobias=True),
conv1_2=L.Convolution2D(None, 16, ksize=5, pad=2, nobias=True),
conv2_1=L.Convolution2D(None, 32, ksize=3, pad=1, nobias=True),
conv2_2=L.Convolution2D(None, 32, ksize=3, pad=1, nobias=True),
fc1=L.Linear(None, 512, nobias=True),
fc2=L.Linear(None, class_labels, nobias=True),
)
self.train = train
def __call__(self, x):
conv1_1 = self.conv1_1(x)
conv1_1 = F.relu(conv1_1)
conv1_2 = self.conv1_2(conv1_1)
conv1_2 = F.relu(conv1_2)
pool1 = F.max_pooling_2d(conv1_2, ksize=2, stride=2)
conv2_1 = self.conv2_1(pool1)
conv2_1 = F.relu(conv2_1)
conv2_2 = self.conv2_2(conv2_1)
conv2_2 = F.relu(conv2_2)
pool2 = F.max_pooling_2d(conv2_2, ksize=2, stride=2)
fc1 = self.fc1(pool2)
fc1 = F.relu(fc1)
fc2 = self.fc2(fc1)
return fc2実行結果は、65 分・・・ただ精度は99%まで上がってます。
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy 1 0.147027 0.0409412 0.953783 0.9865 2 0.0421712 0.0364964 0.98675 0.9876 3 0.0288728 0.0224909 0.990983 0.992 4 0.0217753 0.0237553 0.993083 0.9927 5 0.0162247 0.0219107 0.994567 0.9928 elapsed_time:3936.5276758670807[sec]
続いてこれをGPUで実行させます。
# -*- using:utf-8 -*-
import chainer
import chainer.functions as F
import chainer.links as L
import time
from chainer import training
from chainer.training import extensions
# ネットワーク定義
class CNN(chainer.Chain):
def __init__(self, class_labels=10, train=True):
super(CNN, self).__init__(
conv1_1=L.Convolution2D(None, 16, ksize=5, pad=2, nobias=True),
conv1_2=L.Convolution2D(None, 16, ksize=5, pad=2, nobias=True),
conv2_1=L.Convolution2D(None, 32, ksize=3, pad=1, nobias=True),
conv2_2=L.Convolution2D(None, 32, ksize=3, pad=1, nobias=True),
fc1=L.Linear(None, 512, nobias=True),
fc2=L.Linear(None, class_labels, nobias=True),
)
self.train = train
def __call__(self, x):
conv1_1 = self.conv1_1(x)
conv1_1 = F.relu(conv1_1)
conv1_2 = self.conv1_2(conv1_1)
conv1_2 = F.relu(conv1_2)
pool1 = F.max_pooling_2d(conv1_2, ksize=2, stride=2)
conv2_1 = self.conv2_1(pool1)
conv2_1 = F.relu(conv2_1)
conv2_2 = self.conv2_2(conv2_1)
conv2_2 = F.relu(conv2_2)
pool2 = F.max_pooling_2d(conv2_2, ksize=2, stride=2)
fc1 = self.fc1(pool2)
fc1 = F.relu(fc1)
fc2 = self.fc2(fc1)
return fc2
def main():
model = L.Classifier(CNN())
# モデルをGPUにセット
get_device = 0
chainer.cuda.get_device(get_device).use()
model.to_gpu()
# 更新手法の定義
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
# MNIST 読み込み
train, test = chainer.datasets.get_mnist(ndim=3)
train_iter = chainer.iterators.SerialIterator(train, batch_size=100)
test_iter = chainer.iterators.SerialIterator(test, batch_size=100, repeat=False, shuffle=False)
# device引数に値を指定
updater = training.StandardUpdater(train_iter, optimizer, device=get_device)
trainer = training.Trainer(updater, (5, 'epoch'), out='result')
# device引数に値を指定
trainer.extend(extensions.Evaluator(test_iter, model, device=get_device))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'validation/main/loss', 'main/accuracy', 'validation/main/accuracy']))
# 計算の進捗報告してくれるメソッド
trainer.extend(extensions.ProgressBar())
# トータルの処理時間計算
start = time.time()
# 学習スタート
trainer.run()
elapsed_time = time.time() - start
print("elapsed_time:{0}".format(elapsed_time) + "[sec]")
if __name__ == '__main__':
main()GPU実行の為に変更した部分は、2-3節と全く一緒です。
以下が実行結果となります。
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy 1 0.136203 0.0349827 0.958599 0.9898 2 0.0397109 0.0287768 0.988166 0.9898 3 0.0271944 0.0249732 0.991732 0.9922 4 0.0211752 0.0269511 0.993048 0.9916 5 0.0160625 0.0252386 0.995066 0.9931 elapsed_time:38.8367862701416[sec]
65 分 → 38 秒まで短縮!! ざっと100倍ぐらい早くなりました。
3-2. 速度比較のまとめ
ここまでの結果を表にまとめます。
| ネットワークの種類 | ローカルマシン | Azure GPU NC6 Standard |
全結合 – 3層ニューラルネット | 5分 | 未計測 |
CNN -2つの畳込み層 -2つのプーリング層 | 17分 | 35秒 |
CNN -4つの畳込み層 -2つのプーリング層 | 65分 | 38秒 |
畳込み層が増えたぐらいじゃ、ほとんどGPUの処理時間が変わってないですね。
深層学習となると処理待ち時間が多くなるのがネックですが、分析サイクルを回す上でこれは重宝します!
まとめ
深層学習ライブラリ Chainer を実行し、Azure GPU インスタンス上でニューラルネットを実装しました。CNNにおいては圧倒的な処理速度で、モデルのチューニングなど分析サイクルを高速で回すことができます。料金も一時間あたり ¥90 程度なので、スポットとして使えばコストもかかりません。「Deep Learning Virtual Machine」のマシンイメージも合わせれば、GPUインスタンスを立ち上げてすぐコードを実行できるのも魅力的です。
これで冒頭の「 Azure × Chainer 」シールに恥じぬエンジニアを名乗れます(ちなみにこのシール、この時の戦利品でしょうね)。
最後までお読みいただきありがとうございました!
このページをシェアする: