Lookerにおける開発環境と本番環境を分離する方法

こんにちは。
ちゅらデータでデータビジネスコンサルタントをしている山本です。
みなさん、Lookerを使っていますか?
使われている方は周知のことですが、Lookerは他のBIツールと大きく違っていることがありますよね。
LookMLと呼ばれるコードで、ビューやモデル、ダッシュボードの定義ができ、GitHubなどと連携できるため、一般的なシステム開発と同じように進めることが可能なことです。
また、他のBIツールでは、デスクトップアプリで開発して、サーバにデプロイするといったことが行われますが、Lookerは開発もサーバで行います。
そのため、開発環境と本番運用環境との分離が重要になってきます。
この記事では、そんなLookerでダッシュボードを開発する際の環境分離についてお話したいと思います。
最後までお付き合いいただけますと幸いです。
Lookerで環境を分離する3つの方法
まず始めに、Lookerで環境を分離する方法について整理してみます。
環境分離の方法は、大きく、3つ考えられます。
1.Lookerのモードで分離する方法
2.プロジェクトで分離する方法
3.インスタンスで分離する方法
以降、それぞれの方法について、少し掘り下げて見ていきたいと思います。
Lookerの「モード」で分離する方法
Lookerでは、LookMLを使って開発するときには「開発モード」に入る必要があります。
LookMLは、データソースやカラム(ディメンションやメジャー)の指定や定義、中間集計を行うための派生テーブルなどの作成、テーブルの結合条件の指定、といったことを記述する、SQLに近いコードです。
ですので、データソースを追加したい、ダッシュボードで使うための指標や切り口(分析軸)を追加したいという場合は、開発モードで作業することになります。
開発モードに入ると、本番環境とは異なるGitのブランチで作業することができます。
そのため、本番環境に影響を与えずに開発できるということですね。
簡易的な開発であれば、この機能を使うだけで、十分、開発・本番環境が分離できるのではないかと思います。
ただし、複数人で開発を進める場合は、いくつか課題が出てきます。
LookerのGitには、以下の制約があります。
・本番用と開発用の大きく2階層のブランチ構成である
・開発用のブランチは、個人ブランチと共有ブランチを作成でき、切り替えることができるが、個人ブランチ→共有ブランチへのマージは(Looker上では)できない
そのため、複数人が個人ブランチで作業し、それを中間ブランチにマージし、動作検証を行った上で、本番用ブランチにマージする、というステップは踏めません。
少し規模が大きくなると、環境分離としては、心許ない感じもします。
プロジェクトで分離する方法
そこで、開発用と本番用のプロジェクトを作り、環境を分離する方法を検討します。
開発用プロジェクトの個人ブランチで作業し、それをmainブランチにマージ、開発用プロジェクト内で検証した上で、本番プロジェクトに移行しようという作戦です。
最初に考えつくのは、開発用のプロジェクトで開発を行い、マージしたコードを本番用プロジェクトにコピーしてしまうことではないかと思います。
単純でわかりやすいのですが、この方法を取る場合、いくつか課題が出てきます。
・開発用プロジェクトのコードを本番用プロジェクトにコピーする部分はLookerの外で行う必要がある
・Lookerでは、モデル名はユニークである必要があるため、本番プロジェクト側のモデル名を変更する必要がある
・それに伴い、LookMLダッシュボードのコードも変更する必要がでてくる(グラフやテーブルのデータソースをモデル名から指定しているため)
できれば、Lookerの機能だけで、環境分離を実現したいですよね。
Lookerには、GitHubなどのリモートリポジトリのコードをインポートできる「remote_dependency」という機能があり、それを使えば実現できます。
「remote_dependency」で行われていることを簡単に図解すると、下図のようになります。
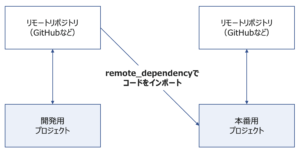
開発プロジェクトでコードの変更が加わっても、「依存関係の更新」を行うまでは、本番プロジェクトには影響しません。
そのため、開発用プロジェクトで十分テストして、問題がないことを確認した上で、本番プロジェクトの更新を行うことができます。
開発用と本番用で接続先のデータベースを変更する場合、接続名などを定数化しておき、開発用プロジェクトでは「export: override_required」、本番用プロジェクトでは「override_constant」を指定することで実現できます。
この方法を使えば、本番用プロジェクトは最初に「remote_dependency」のコードを用意しておくだけで、開発プロジェクトで動作検証したコードがそのまま本番プロジェクトでも使えますので、本番側での追加検証の手間も省けます。
インスタンスで分離する方法
前項のプロジェクトで分離する方法で十分満足できそうですが、「remote_dependency」のコードを準備しておく必要がある、開発環境と本番環境が全く同じコードではない、LookMLダッシュボードは開発→本番移行できるがユーザ定義ダッシュボードは別途作らないといけない、という欠点があります。
そんな欠点を解消するためには、物理的に環境を分離してしまうのが良さそうです。
Lookerは本番環境とは別に開発用のインスタンスを契約することができます。
インスタンスで分離してしまえば、開発環境と本番環境が物理的に分けられますので、先述の「モデル名ユニーク」の問題なども気にせずに、開発環境で作成したコードをそのまま本番環境に移行可能です。
また、Gazerを使うことで、ユーザー定義ダッシュボードも移行できます。
https://community.looker.com/open-source-projects-78/gazer-a-command-line-tool-for-looker-content-management-8066
さらに、開発用のインスタンスを持つメリットとして、「標準拡張サポートリリース(ESR)プログラム」を利用できることも挙げられます。
Lookerは、ほぼ毎月マイナーバージョンアップが行われますが、ESRではリリースサイクルが変更され、本番環境インスタンス以外で、事前に検証することができるようになり、より安定した運用ができるようになります。
https://cloud.google.com/looker/docs/standard-extended-support-release-program-overview
まとめ
Lookerで開発・本番環境を分離する方法について、お話させていただきましたが、いかがだったでしょうか。
それぞれの方法の特徴をご理解いただけましたでしょうか。
開発規模に応じて、環境分離の最適な方法も変わると思いますので、一度、検討してみてはいかがでしょうか。
このページをシェアする: