dbt Coalesce 最速レポート 最終日-セッション編-

DATUM STUDIOの兒玉です。dbt Coalesce 最終日のレポートです。あっという間の4日間でした…。最終日は基本的にセッションだけだったので、面白かったものをいくつかご紹介します!
目次
Governance as code: How dbt and AI unlock scalable data collaboration
クラウドセキュリティサービスを提供しているZscaler社の事例紹介です。
Zscaler社は当初、中央集権型のモノリスなデータ基盤体制を採用していました。その結果、全事業部門を支える必要があり、効率性・採用率・信頼性・スケーラビリティなどの課題に直面したそうです。そこで、データチームが全てを管理することを見直し、中央チームが分析の基盤を整備し、ドメインチームが自分たちでパイプラインを構築できるように大きく方針転換を行ったそうです。さらに「分散型ガバナンス」を導入し、各チームが自律的に運用できる仕組みが整えられました。
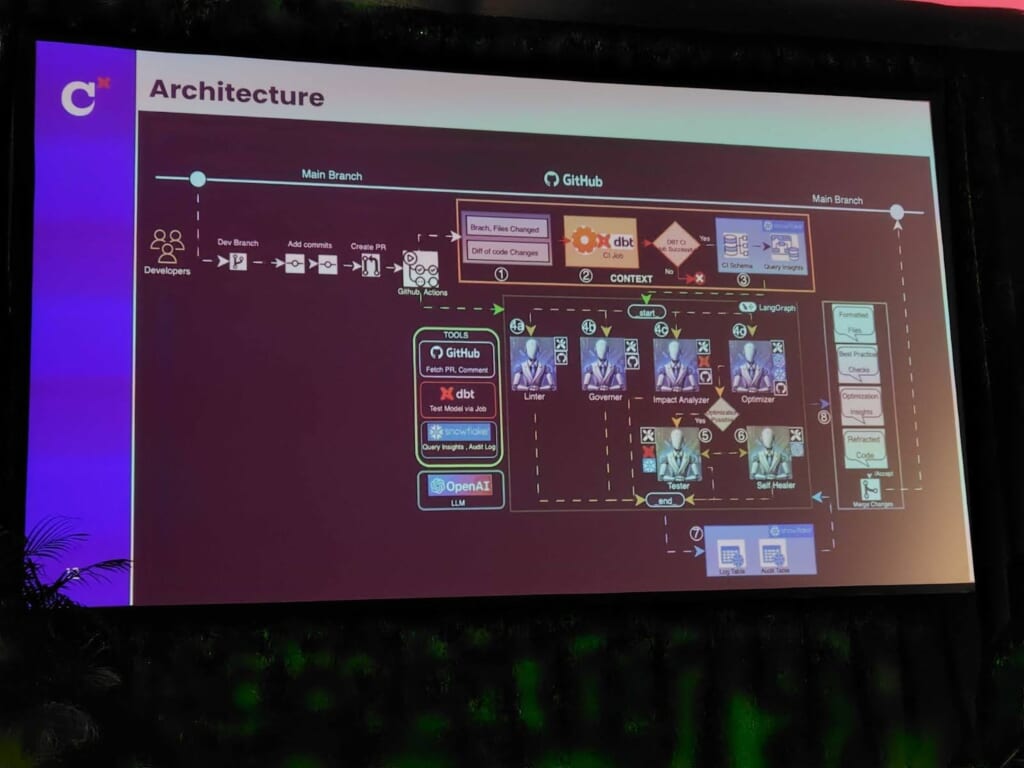
次にボトルネックとなったのは、レビューです。すべてのPR(プルリクエスト)は中央チームがレビューし、一貫したベストプラクティスを維持していたため、結果的に中央チームの負担は増大してしまったそうです。これに対してZscaler社では「PRISM」と呼ばれる独自のレビューエージェントシステムを構築し、PRの自動レビューと自動承認を実現する仕組みを整備しました。
PRISMは、以下の情報源をAIエージェントに接続して動作するプロセスだそうです。
dbt Discovery API
→ モデルの下流リネージ(依存関係)を可視化し、AIが依存関係を理解した上で提案できるようにします。
dbt CI ジョブ
→ PR時に変更内容を自動検証し、実行時間やスキャンサイズなどのメタ情報を取得。これがAIによる最適化の文脈データになります。
dbt Cloud API
→ モデルの検証やコンパイル結果を取得し、変更の裏側を理解するために使用します。
Snowflakeのクエリ統計情報
→ クエリ実行の詳細を分析し、AIがより精緻な最適化提案を行えるようにします。
結果的には、以下の成果が得られたとのこと。驚異的な改善ですね。
・レビュー時間を最大90%削減
・四半期あたり約90万ドルのコスト削減を試算
・年間約2100時間の工数削減(=フルタイム1人分)
仕組み自体が面白いですがレビューを自動化するだけでなく、承認までAIに任せてしまう大胆さを組織に持たせることができているのもポイントだと感じます。
Introducing ade-bench: A new scorecard for measuring which robots work well with dbt
こちらのセッションは、他とは少し毛色が異なります。AIエージェントの性能を検証するベンチマークテストを実行する仕組みを、dbtを利用して実現するための「ade-bench」というツールの紹介でした。
最近の基盤モデル各社(OpenAI, Anthropic, Google Cloud )は「コード」の生成が得意であることを前面に出しています。登壇者のBenn Stancil氏は、その理由のひとつとして評価指標(ベンチマーク)が整備されていることを挙げました。
一方で、データ分析やアナリティクス・エンジニアリング領域では、実務に即した標準的な評価セットが乏しいため、モデルやエージェントの改善度合いを比較しづらいという課題があります。
そこで、Text-to-SQLで単発のクエリを当てる類のタスクではなく、“実在のdbtプロジェクトに対して、壊れたパイプラインを直す・モデルを追加する・設定を適切に施す”といった、より現実的で多段な課題を与え、dbt testsを用いた自動採点で合否を判定する一連のプロセスを実行するツールを作ったとのことでした。
同ツールによる、現時点でのベンチマークの結果は以下のとおりです。
・dbt Fusion + Claude 4.5は、dbt Coreよりも“速く安く”動く傾向(課題構成による)
・MCPサーバ連携で成功率が明確に改善
・旧世代モデルは安いが精度低め、Gemini はこの条件だと高コストに振れがち、CodeEXはコスパ良好といった“手触り”
・ただし、余計なカラム名変更など、人間なら避ける“逸脱”を起こす場面もあり、完全自動の道のりはまだ長いという率直な結論
生成AIのベンチマークをdbtで作るなんて、これまで考えたことも聞いたこともなかったので、非常に面白かったです…!
dbt Coalesce 2025 総括
2025年現在、ELTやストレージ、コンピュートなどがそれぞれ「餅は餅屋」的に別々のツールとして存在していたモダンデータスタック的な世界観は過ぎ去り、もはや BigQuery 、Snowflake、Databricksなどのプラットフォームが持つ機能だけで、ある程度のデータ基盤を構築できるようになりました。
そんな中、dbt LabsやFivetranのような企業が合併しながら、ベンダーロックインしないオープンなプラットフォームを実現するための立場というスタンスを取るようになったのは、ある意味必然的な流れだと思います。
また、コードのコンテキストをより深く捉えられるFusionエンジンの提供や、リモートMCPサーバーの公開など、AIエージェントを意識した機能拡張が今後も中心となっていくと予想されます。
このページをシェアする: