dbt Coalesce 最速レポート3日目-Community Keynote-

DATUM STUDIOの兒玉です。dbt Coalesce 3日目のレポートです。
目次
Community Keynote
3日目の冒頭はコミュニティによるKeynoteでした。主な発表内容は以下のとおりです。
・dbt-coreはApache2.0ライセンスで提供され続けることを強調
・UDF(ユーザー定義関数)機能の追加が発表
・コミュニティへの貢献者の表彰
dbt-coreのApache2.0ライセンス
2025年1月のSDF Labsの買収後、公開されたdbt FusionはRustで記述されており、大規模プロジェクトでより高速な解析(最大30倍の処理速度)を実現しています。dbt-coreの後継かのようにも見えるFusionエンジンが登場しましたが、CEOのTristan Handy氏は、dbt-coreはApache 2.0ライセンスの下でオープンソースとして維持され続けることを強調しました。
また、dbt Fusionは一部がオープンソース、一部がソース利用可能、一部がプロプライエタリなライセンスモデルを採用している点など、dbtのエコシステム全体でのライセンスモデルの整理について、あらためて発表がありました。

UDF機能の追加
dbtでUDF(ユーザー定義関数)を定義できるようになりました。dbt-core、dbt FusionともにBeta版として、すでに利用可能となっています。
https://docs.getdbt.com/docs/build/udfs
モデルやシードなどと同じファーストクラスのオブジェクトとして扱われています。dbtを用いることで、たとえば以下のような点でメリットがありそうです。
・dbt unit testの仕組みを使って、UDFの自動テストを構成できる
・UDFを利用しているモデルとのリネージを繋いで、依存関係を管理できる
コミュニティ貢献者の表彰
dbtコミュニティへの貢献を称え、様々なカテゴリーで賞が授与されました。今年は日本からもなんと2名の表彰がありました!素晴らしいニュースですね。

セッションレポート
今日のセッションは、どれも非常に内容が濃かったです…!
Below the tip of the Iceberg: How Wikimedia reduced reporting latency 10x using dbt and Iceberg
Wikipediaを運営している非営利団体であるWikimedia Foundationの事例紹介です。
ユーザーからの寄付金を分析するためにデータを活用していたものの、従来のシステムではデータ抽出に最長で1週間かかるなど、特にパフォーマンスの点において様々な問題を抱えていたそうです。
ただ、データセキュリティの観点から、クラウドサービスの利用ができなかったため、すべてをオンプレミスとOSSの組み合わせで、新しいデータプラットフォームを設計したとのことでした。この新しいプラットフォームは、Trinoをクエリエンジン、MetabaseをBIツール、MinIOをオブジェクトストレージ、Icebergをテーブルフォーマット、そしてdbtを変換ツールとして利用しています。
驚異的なのは、新しいデータスタックへの移行により、主要なデータモデルの構築に5時間以上かかっていたところから1時間未満に短縮。また、過去6年間のデータ取得に8分以上かかっていたのが、過去18年間のデータをわずか8秒で取得できるようになり、ユーザーエクスペリエンスとアナリストの生産性が大幅に向上したという点です。ものすごい改善ですね!
Goodbye manual testing & alert fatigue: Meet your AI data SRE Attachments
SYNQ社による、生成AIを用いたデータパイプラインのテストの実装の自動化に関するセッションです。
大企業では、数千におよぶdbtモデルとテストが存在し、問題発生時に原因や影響範囲を特定するのが困難になります。この課題を踏まえ、セッションでは「データ品質成熟度モデル」が提示されました。
これは、リアクティブなテスト → 戦略的テスト → 自動化という段階的な進化を描くもので、最終的にはデータ可観測性ツールを活用して品質維持を自動化する姿を示していました。
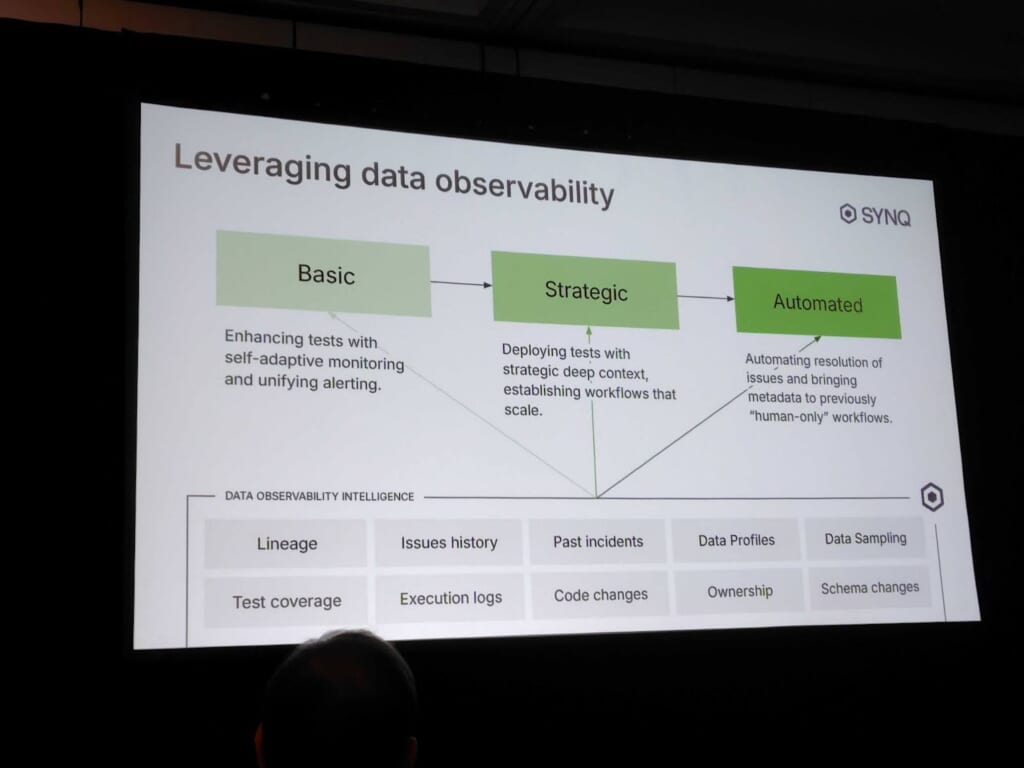
次に紹介されたのは、LLMとMTP(Metadata Tooling Platform)を組み合わせた自動テスト生成の仕組みです。具体的には、スキーマや既存チェックのメタデータをもとに、LLMがテストを提案したり、欠落している品質チェックを補完したりします。コンテキストをymlで定義する例や適切なコンテキストエンジニアリングのレベルなど、とても実践的な内容でした。
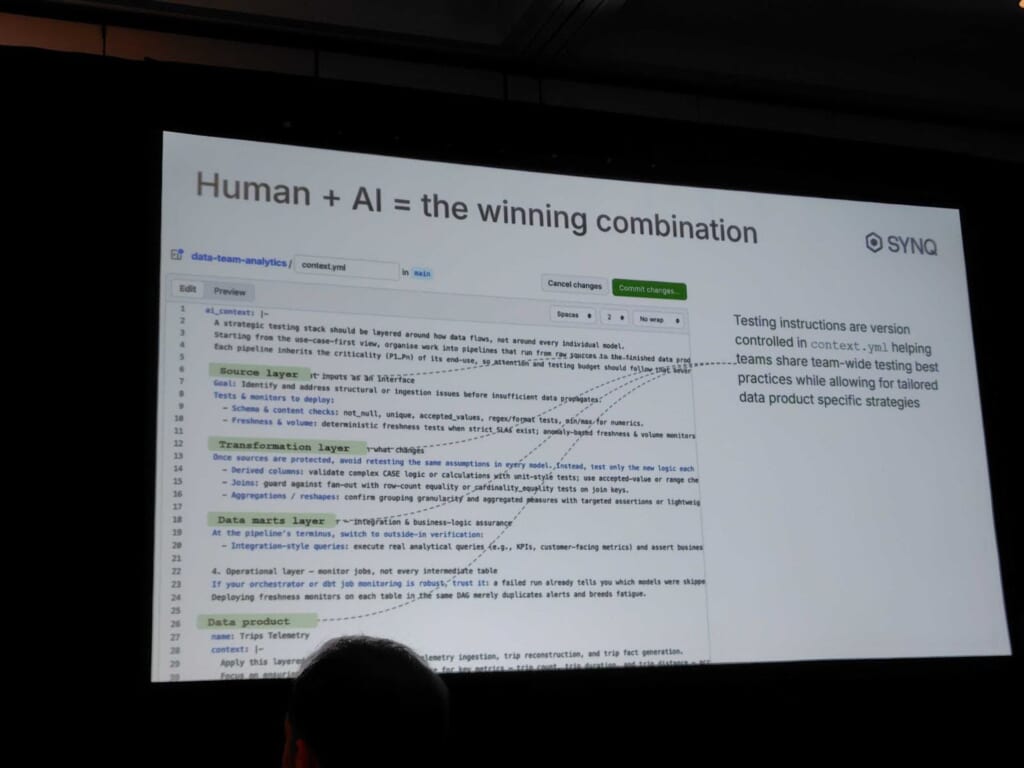

印象的だったのは「まず、テストやデバッグなどリスクの低い内部領域から始める」ことを推奨していた点です。
多くの組織において、まず「BIツールをチャット化して誰でも使えるようにする」といったユーザー向けの華やかな領域からAI導入を始めようとしがちです。
しかしながら、このセッションではそのような領域から着手するのは危険だと主張していました。理由は、こうしたツールを使用する多くの人がデータチーム外のメンバーであり、「データがどのように作られ、どのように壊れるのか」といった内部構造への理解が浅いためです。その結果、AIが返す結果が期待と少しでも異なった瞬間に、AIそのものだけでなくデータチームへの信頼も損なわれる危険性があるとのことです。
一方で、今回のセッションで紹介されたようなテストやデバッグなどの内部プロセスにAIを取り入れる方法は、データチーム自身が「運転席」に座ったまま扱える領域です。リスクが低く、導入効果も測りやすいため、AIを使ったワークフローを設計する際は、まずこのような「チーム内で完結する安全な領域」から始めることを推奨していました。
このページをシェアする: