dbt Coalesce 最速レポート2日目-セッション編②-

DATUM STUDIOの向井です。引き続きdbt Coalesceの各セッションの内容についてお届けします。
目次
From silos to AI-ready: How Okta built governed analytics at scale
このセッションはOkta社の事例紹介です。データのサイロ化を防ぐための対策として、4つの方針を提唱しています。
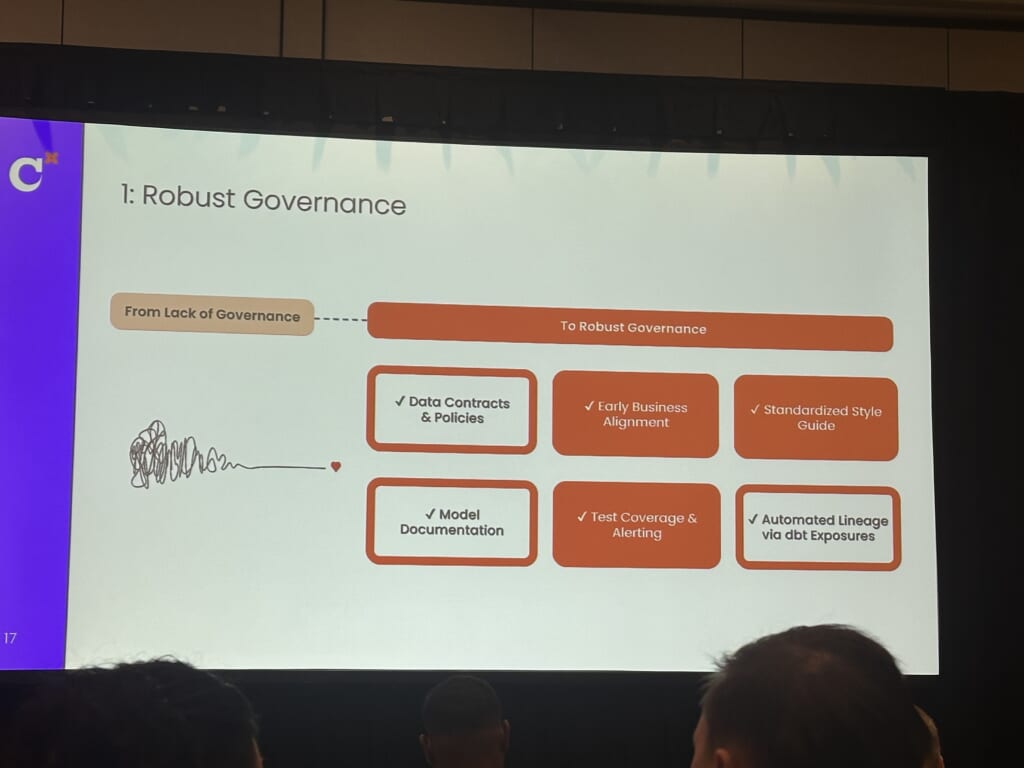
1.Robust Governance
テストの標準化や設計ガイドラインを作成して、統一されたガバナンスを策定します。
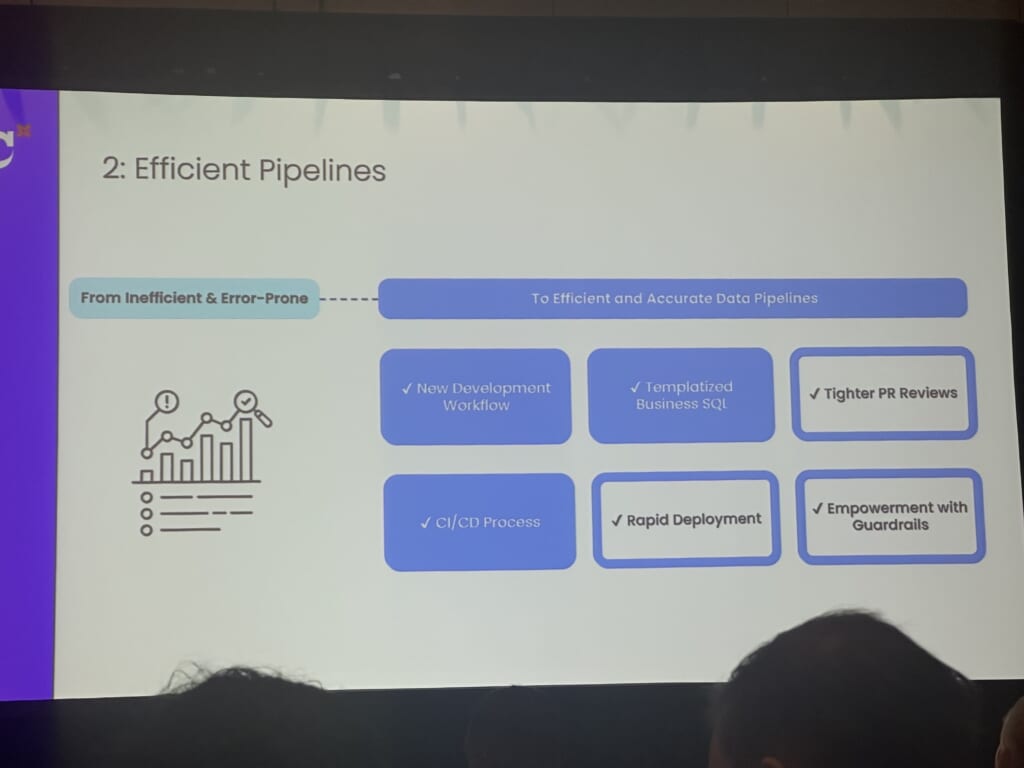
2.Efficient Pipelines
CICDを充実させ、AIを活用したコードレビューでより効率的なパイプラインを目指します。
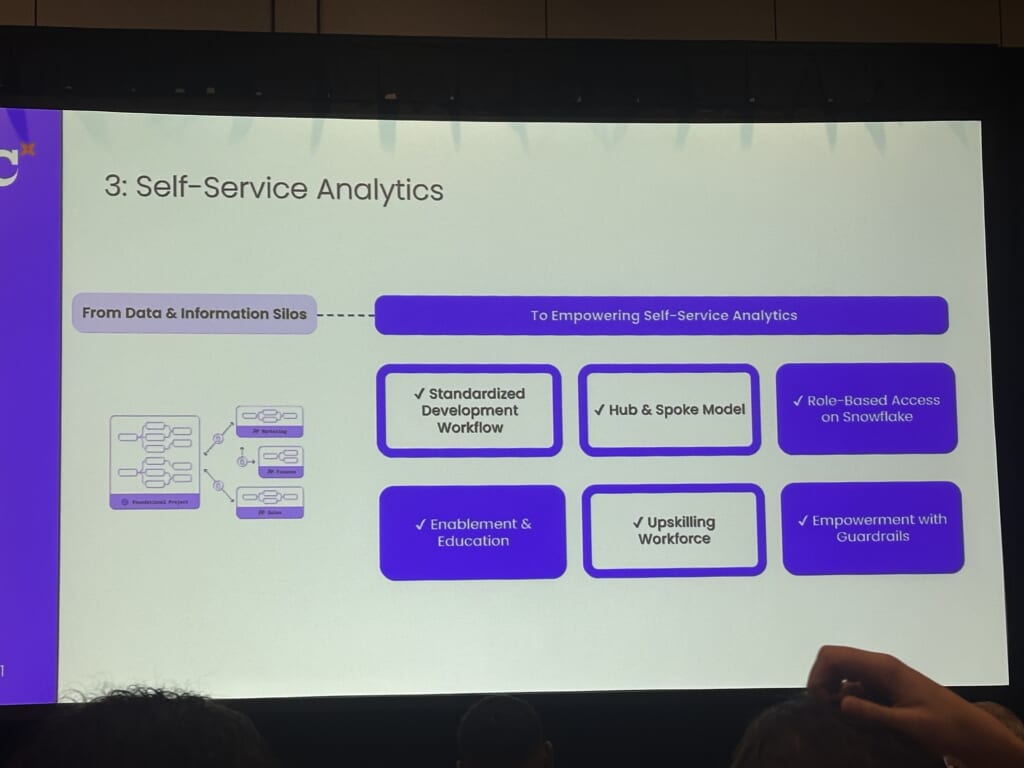
3.Self-Service analytics
ワークフローの標準化とHub&Spokesモデルによって、自分に必要なデータのみを提供します。
また、AI活用の未来として、dbtのAI AgentやMCP Serverを利用する目標が示されていました。
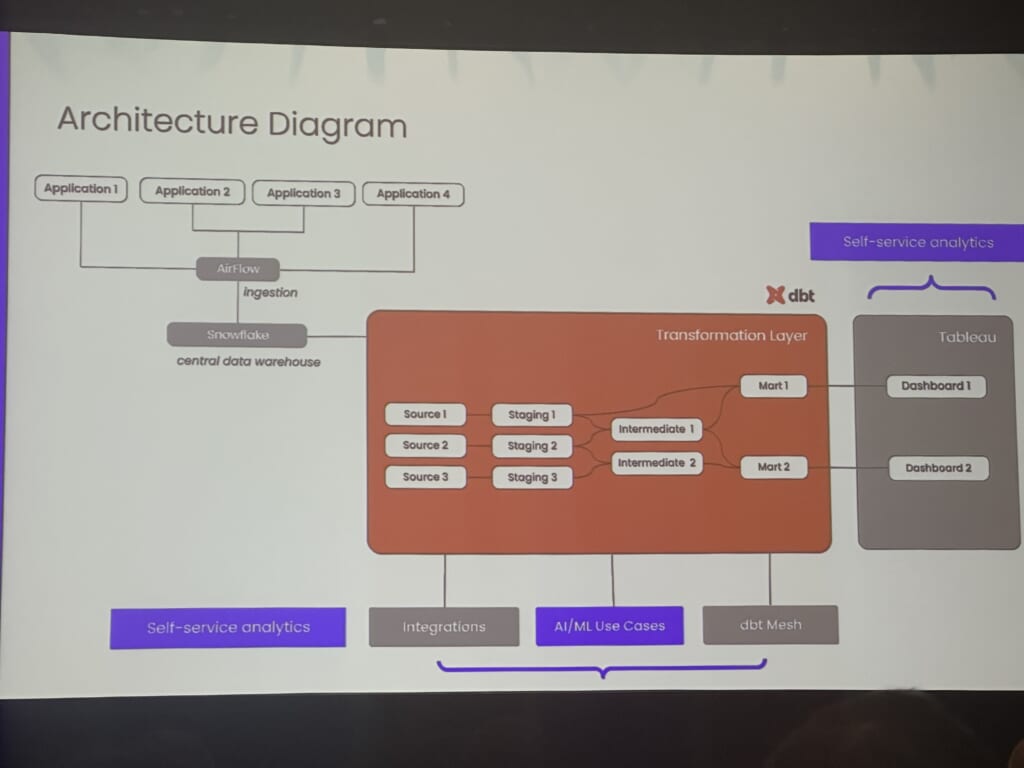
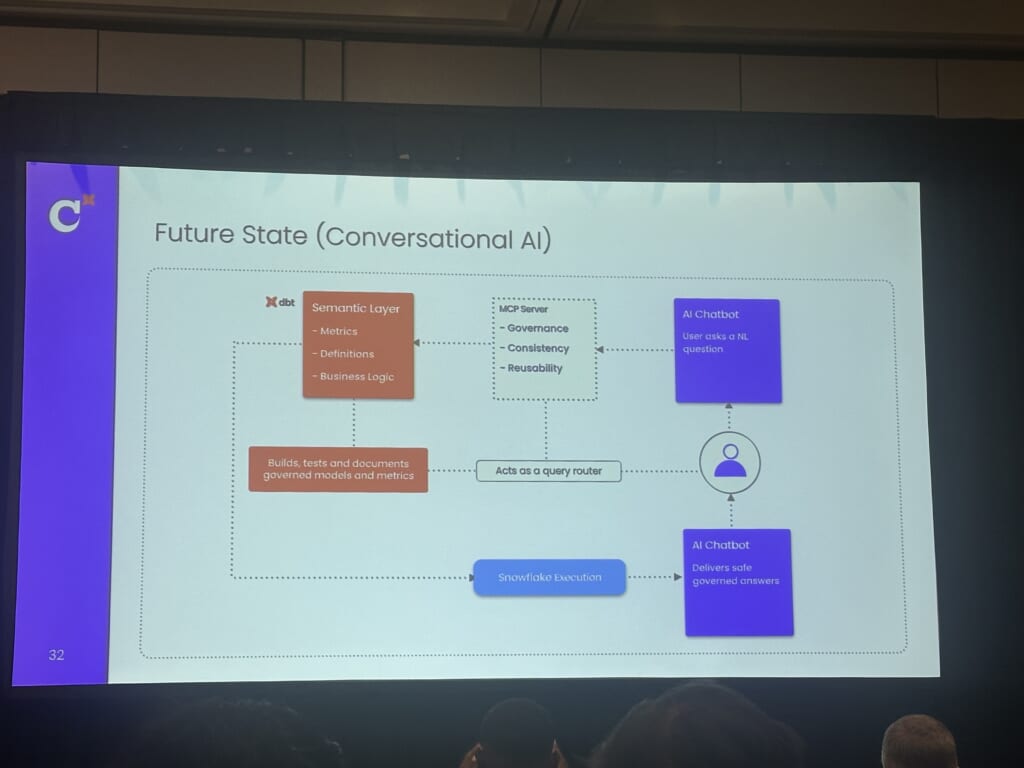
dbtのAI関連の機能はまだSnowflakeのCortex Agentに分がある状況ですが、これからの業界標準化の波にうまく乗ることを期待したいですね。
DuckLake: Making BIG DATA feel small
こちらのセッションでは、MotherDuckからDuckLakeの紹介とデモが行われました。
DuckLakeはmetadataをDB内に保管するシンプルなテーブルフォーマットです。
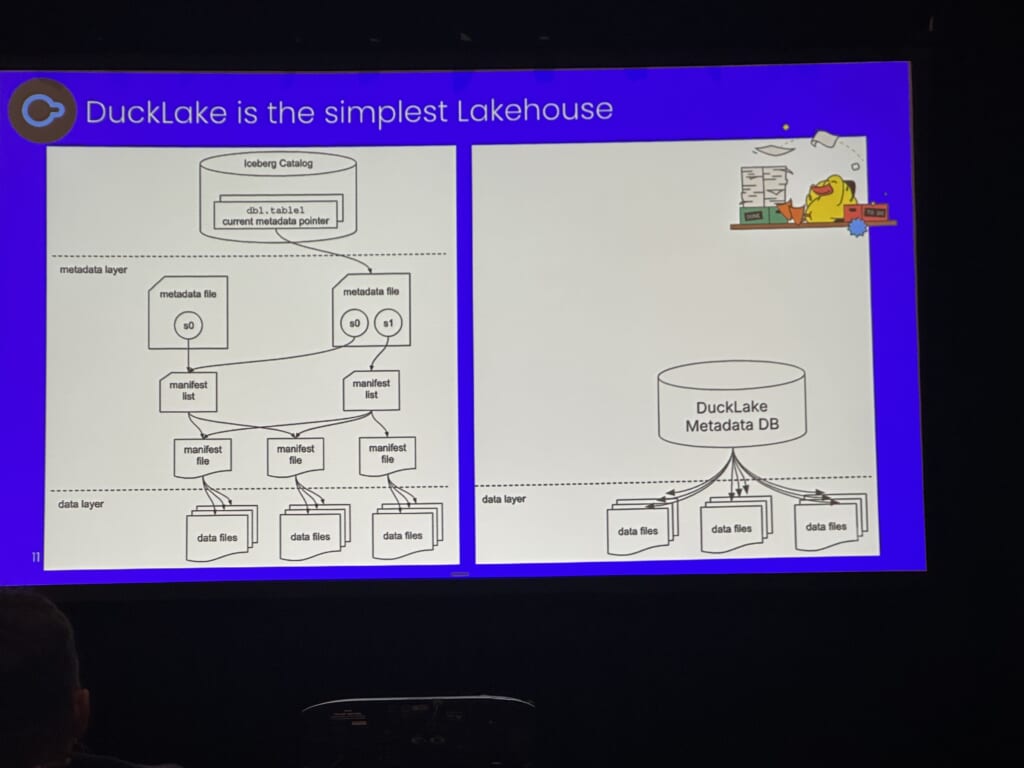
metadata DBとしてはDuckDBの他にPostgres、 MySQL、 SQLiteも利用可能で、AWS AthenaやSnowflakeなどの大規模なアーキテクチャを利用しない点は魅力的に感じました。
デモでは、DuckDBをローカルに立ち上げて実際にクエリする様子が紹介されました。
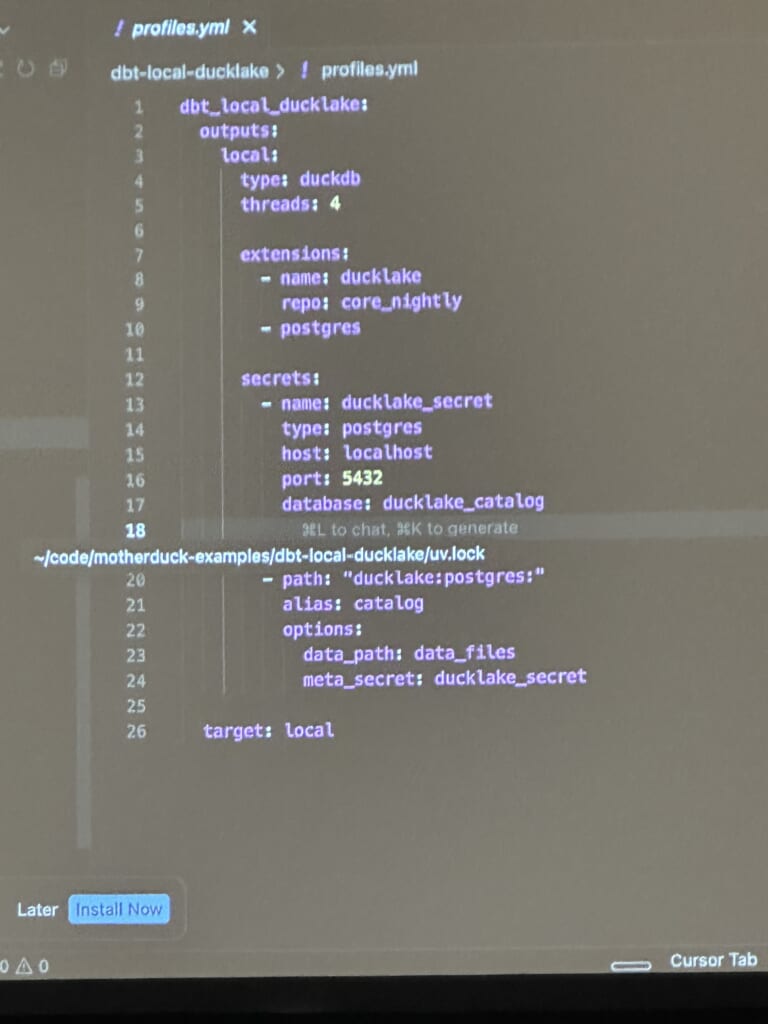
実際に運用する際、本番環境ではサーバレスな環境が推奨のようです。セッションではMotherDuckが推奨されていましたが、RDSなどのソリューションも利用できそうです。
また、軽量なデータであれば、WASM上でDuckDBを動作させるアイデアも面白いと思いました。


おわりに
dbtは BigQuery 、Snowflake、DatabricksなどのDWH製品と密接な関係にあるものの、どれかに偏った立場を示していません。これらの影響か、各セッションもData Meshによるマルチクラウドの事例や、他製品との互換性を意識したアーキテクチャの紹介が多いように感じられました。今後も標準化の波がどんどん進むことを期待したいです。
このページをシェアする: