dbt Coalesce 2024 最速レポート3日目②

こんにちは、データエンジニア部の向井です。3日目のセッション内容をレポートします。
Let them cook: Hands-on with the visual editing experience
こちらのセッションでは、visual editorのデモが行われました。また開発ロードマップも示されました。

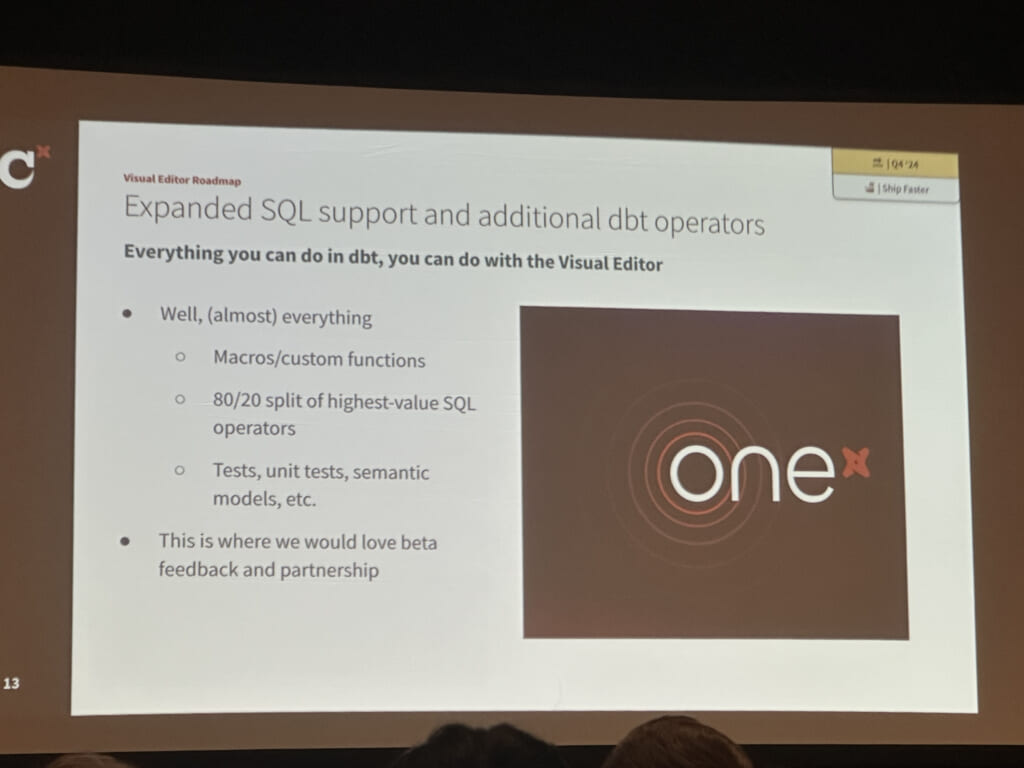
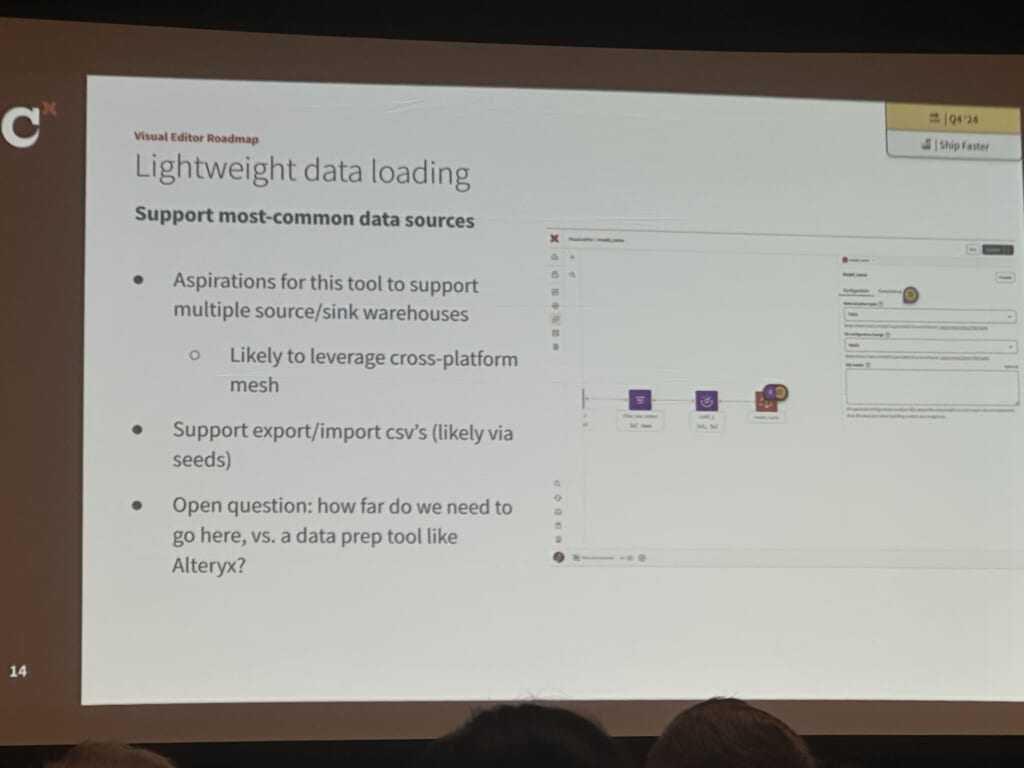

より開発が簡単になるような機能追加が多くみられ、「もっとビジネスユーザーに使ってもらいたい」という思いを感じる発表でした。
Leveraging column-level lineage to scale your dbt projects
この発表では、dbt explorerのcolumn level lineageの使い方と、自動メンテナンスの方法としてdbt-cll-evaluatorというツールが紹介されました。
https://github.com/dbt-labs/dbt-cll-evaluator



まだAPIに仕様変更が入る可能性が高く、開発中のツールですが、確認観点は非常に参考になるものでした。
A strategic approach to testing & monitoring with Data Products
このセッションではSYNQというプロダクトと、それが実現するdata reliability向上のためのテスト戦略が紹介されていました。
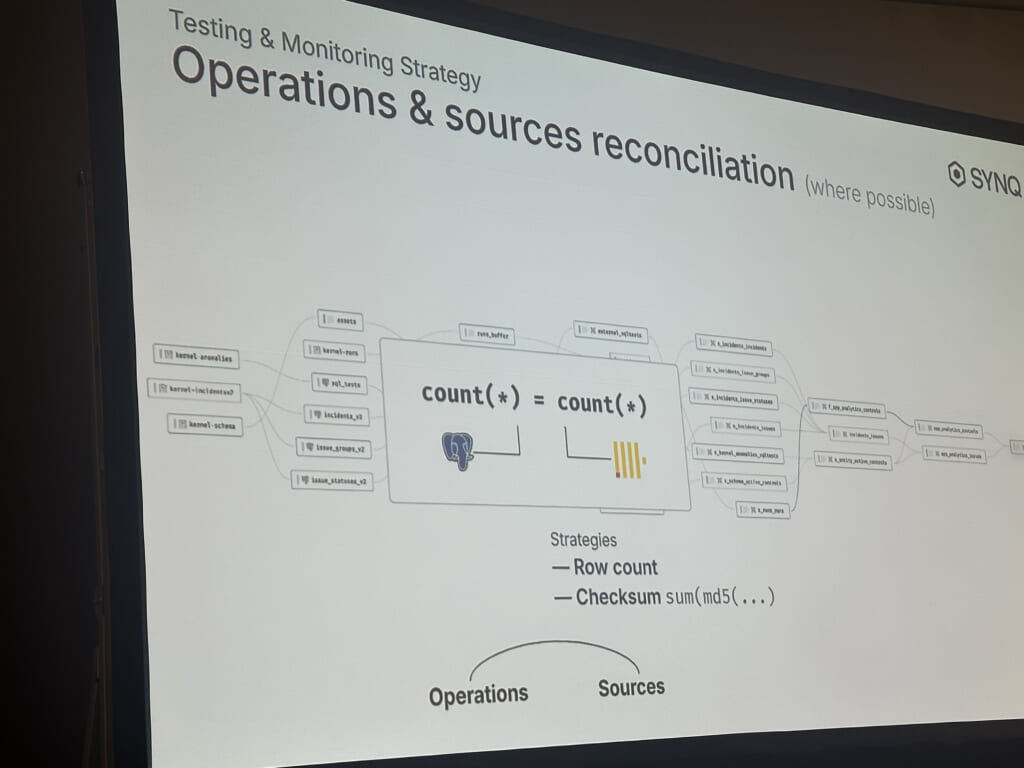
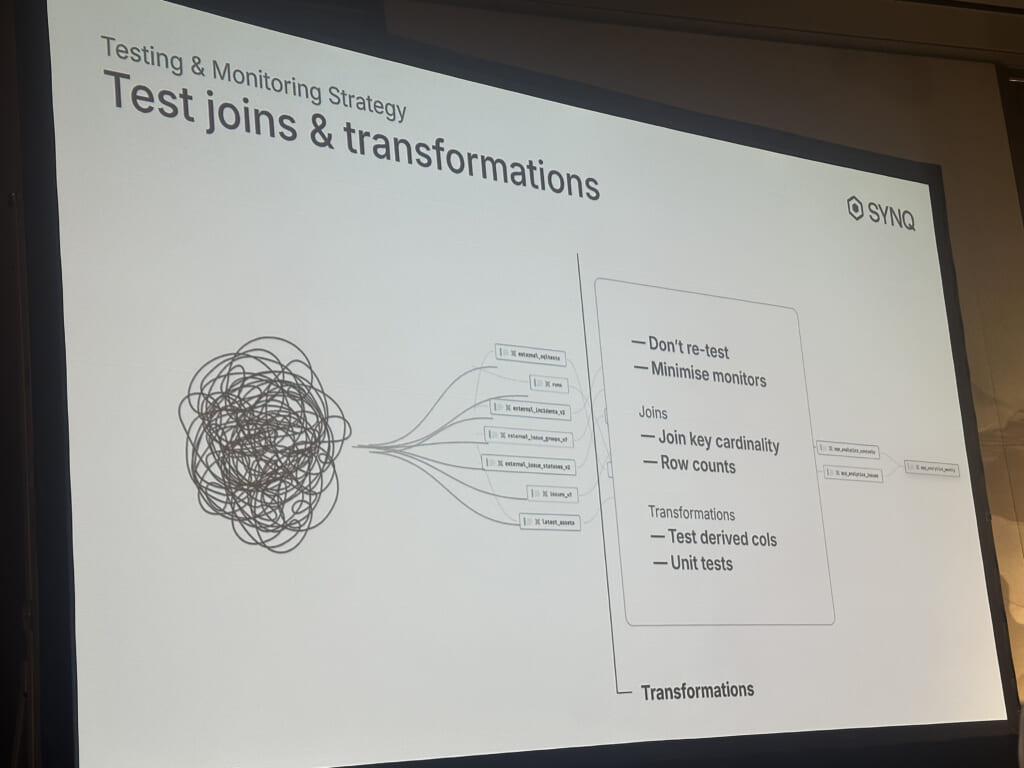
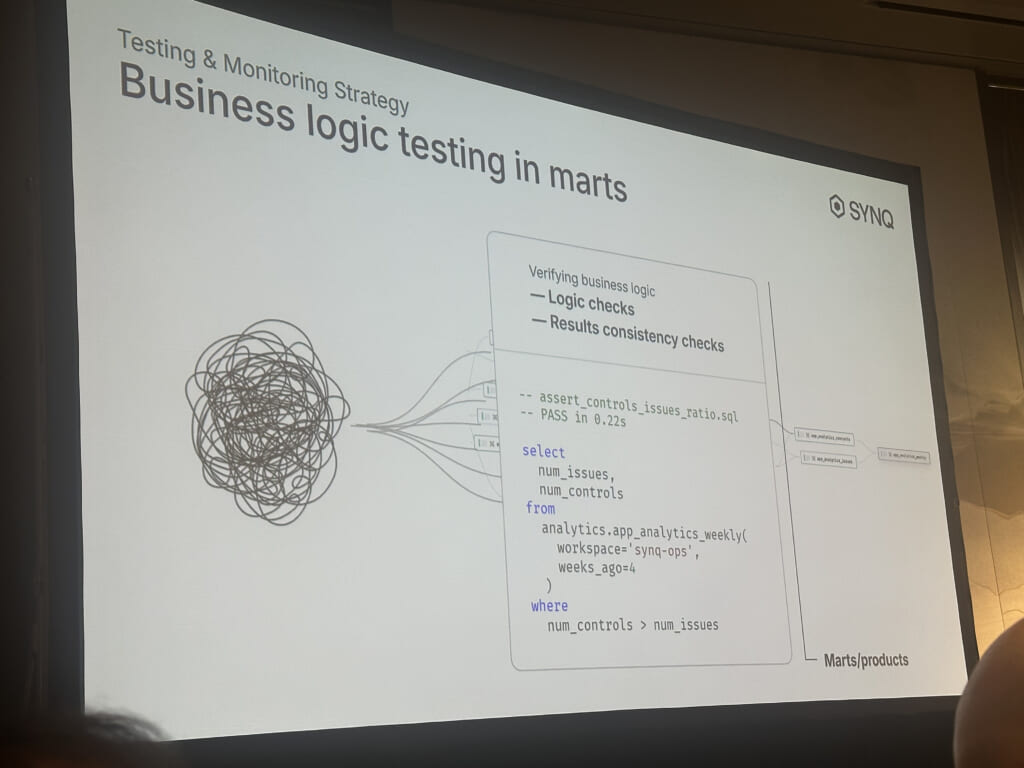
データ取り込み・中間・マートの3層に分けてテストの考え方を分離しており、実務上行うテスト項目と近しく納得感のあるものでした。機会があればこのプロダクトも利用してみたいですね。
Optimise your dbt pipelines in Snowflake instantly: How to boost efficiency and data quality with powerful dbt macros
こちらのセッションではSnowflakeを運用する際の便利な自作macroの紹介をしていました。
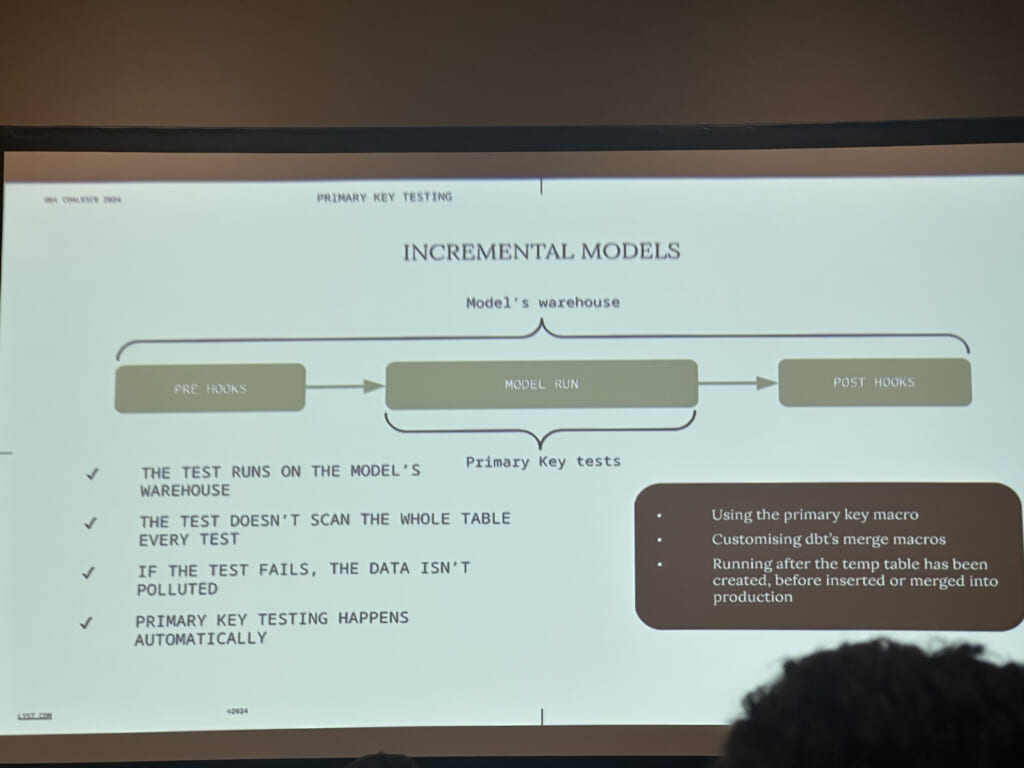
一つ目はテストのmacroでincremental時の部分的なtestを行うものです。これを使うことで全体のスキャンを避けて、コスト削減につながったそうです。

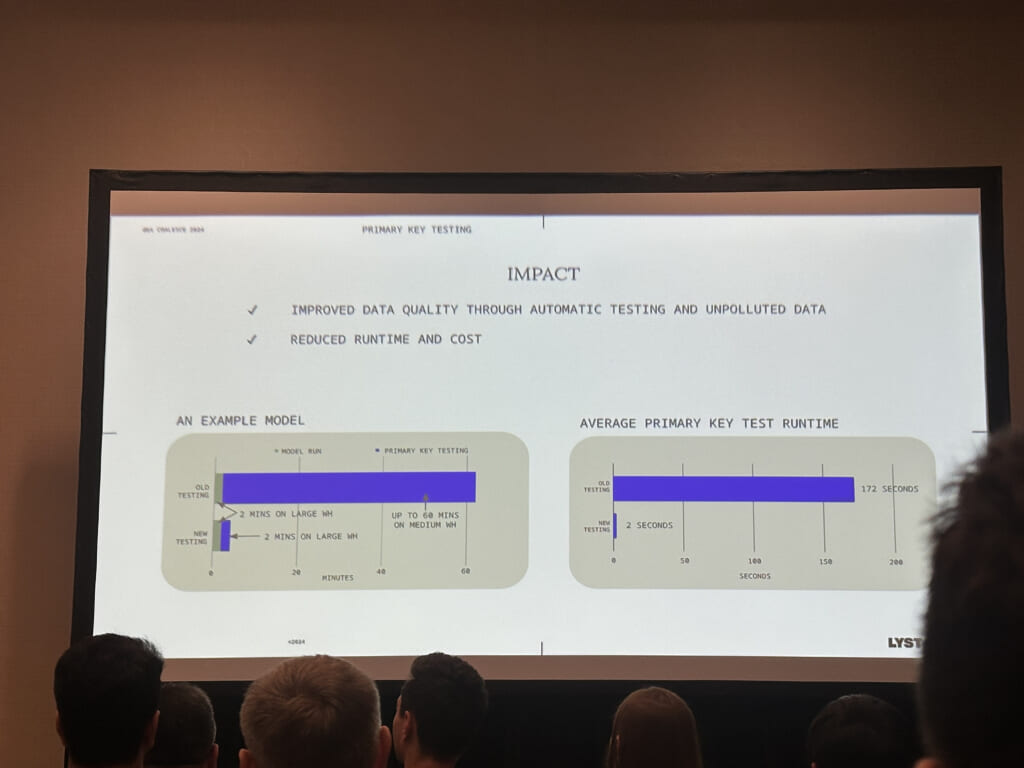
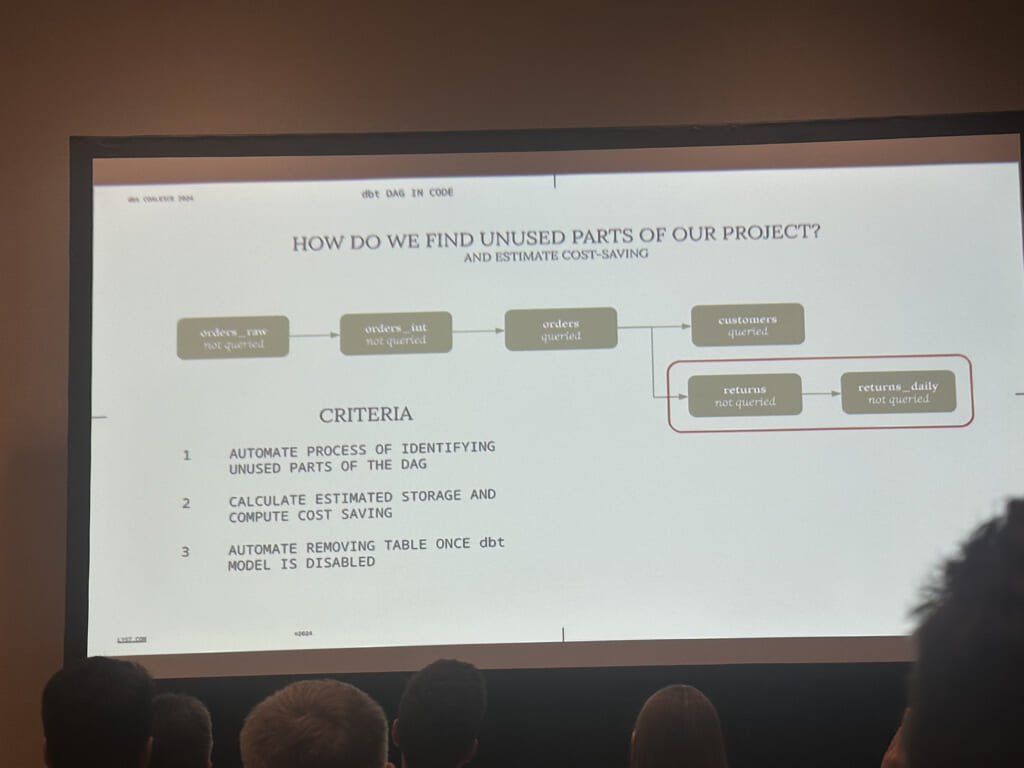
二つ目は不要なテーブルの削除です。GithubのPull requestに連動して利用されていないテーブルを削除することで、不要なストレージコストを削減することができます。
How to leverage dbt for embedded domain knowledge across product engineering teams
こちらのセッションは、ドメイン知識をプロダクトチームと共有する方法を3ステップに分けて紹介されていました。



日本の企業でもドメイン知識の偏在に悩まされている企業は多いと思いますが、最も初めに統一された指標、用語の定義が不可欠であると感じました。
また、データ基盤の成熟度の目安としてrawデータのクエリ数や、アドホッククエリの数が減ったことを挙げられていたことも印象的でした。

おわりに
様々なセッションがあったdbt coalesceですが、いよいよ明日が最終日となります。明日のレポートもお楽しみに!
このページをシェアする: