連載:Azure HDInsightでR Serverを利用する(パフォーマンス測定編)
はじめに
みなさん、こんにちは! DATUM STUDIOの宇佐見です。
引き続き、Azure HDInsightでR Serverを利用していきます。 前回作成したR Serverのクラスターを利用して、R Serverのパフォーマンスを測定していきます。
前回の記事は以下になります。
連載:Azure HDInsightでR Serverを利用する(環境構築編)
パフォーマンス測定
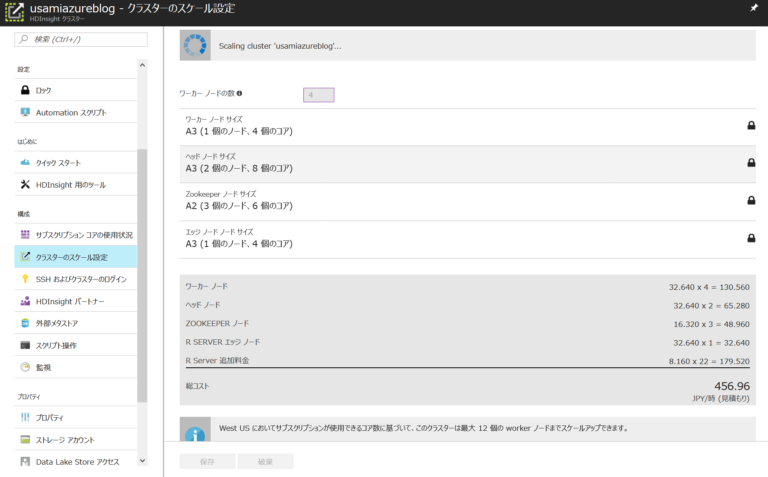
スペック
各ノードのスペックは以下の通りとなります。 パフォーマンステストに応じてワーカーノードの数は1もしくは4に変更しています。
| ノード種別 | スペック | 台数 | 役割 |
|---|---|---|---|
| ワーカーノード | A3 | 1、もしくは4 | 分散処理を担当する |
| ヘッドノード | A3 | 2 | 分散処理の実行指示する |
| ZooKeeperノード | A2 | 3 | 分散処理のコーディネートを行う |
| エッジノード | A3 | 1 | RStudio Serverが起動しており、ヘッドノードに指示する |
データ読み込み
さて早速データの読み込みを行っていきます。 ついでにモデルの定義についても行ってしまいます。
のちのパフォーマンステストでデータ量を変えてテストを行っているため、 下記のコードでは2ヶ月分のみの読み込みとしています。 読み込む月数に応じてコメントを外す処理が必要となります。
# Set the HDFS (WASB) location of example data
bigDataDirRoot <- "/example/data"
# create a local folder for storaging data temporarily
source <- "/tmp/AirOnTimeCSV2012"
dir.create(source)
# Download data to the tmp folder
remoteDir <- "http://packages.revolutionanalytics.com/datasets/AirOnTimeCSV2012"
download.file(file.path(remoteDir, "airOT201201.csv"), file.path(source, "airOT201201.csv"), method = "wget")
download.file(file.path(remoteDir, "airOT201202.csv"), file.path(source, "airOT201202.csv"), method = "wget")
#download.file(file.path(remoteDir, "airOT201203.csv"), file.path(source, "airOT201203.csv"), method = "wget")
#download.file(file.path(remoteDir, "airOT201204.csv"), file.path(source, "airOT201204.csv"), method = "wget")
#download.file(file.path(remoteDir, "airOT201205.csv"), file.path(source, "airOT201205.csv"), method = "wget")
#download.file(file.path(remoteDir, "airOT201206.csv"), file.path(source, "airOT201206.csv"), method = "wget")
#download.file(file.path(remoteDir, "airOT201207.csv"), file.path(source, "airOT201207.csv"), method = "wget")
#download.file(file.path(remoteDir, "airOT201208.csv"), file.path(source, "airOT201208.csv"), method = "wget")
#download.file(file.path(remoteDir, "airOT201209.csv"), file.path(source, "airOT201209.csv"), method = "wget")
#download.file(file.path(remoteDir, "airOT201210.csv"), file.path(source, "airOT201210.csv"), method = "wget")
#download.file(file.path(remoteDir, "airOT201211.csv"), file.path(source, "airOT201211.csv"), method = "wget")
#download.file(file.path(remoteDir, "airOT201212.csv"), file.path(source, "airOT201212.csv"), method = "wget")
# difine formula
logit_formula <- formula("ARR_DEL15 ~ ORIGIN + DAY_OF_WEEK + DEP_TIME + DEST")
# r server pattern
# Set directory in bigDataDirRoot to load the data into
inputDir <- file.path(bigDataDirRoot,"AirOnTimeCSV2012")
# Make the directory
rxHadoopMakeDir(inputDir)
# Copy the data from source to input
rxHadoopCopyFromLocal(source, bigDataDirRoot)
# Define the HDFS (WASB) file system
hdfsFS <- RxHdfsFileSystem()
# Create info list for the airline data
airlineColInfo <- list(
DAY_OF_WEEK = list(type = "factor"),
ORIGIN = list(type = "factor"),
DEST = list(type = "factor"),
DEP_TIME = list(type = "integer"),
ARR_DEL15 = list(type = "logical"))
# get all the column names
varNames <- names(airlineColInfo)
# Define the text data source in hdfs
airOnTimeData <- RxTextData(inputDir, colInfo = airlineColInfo, varsToKeep = varNames, fileSystem = hdfsFS)
# Define the text data source in local system
airOnTimeDataLocal <- RxTextData(source, colInfo = airlineColInfo, varsToKeep = varNames)データ量については1ヶ月で100MB強、50万レコード程度です。 12ヶ月分で1.5GB、600万レコード程度のデータとなります。
従来の手法
ではデータを2ヶ月分に限定して従来のロジスティック回帰を適用してみます。
install.packages("dplyr")
install.packages("data.table")
library(dplyr)
library(data.table)
# logistic reg
base_data <- bind_rows(fread("/tmp/AirOnTimeCSV2012/airOT201201.csv"),
fread("/tmp/AirOnTimeCSV2012/airOT201202.csv"))
system.time(
glm(logit_formula, data = base_data, family = binomial(link = logit))
)Error: cannot allocate vector of size 13.8 Gb
とエラーが出てしまい、関数を実行することができません。 行列演算のメモリ割り当て時にメモリが足りないため、エラーが起きていると推測されます。 ちなみに1ヶ月分だけでもメモリ不足は起きます。
従来の手法ではサーバのスケールアップを考慮に入れるか、 サンプリングをしてデータを少量にするなどで無理矢理処理を通す必要があります。
エッジノード環境での実施
さてR Serverではワーカーノードを利用せず、エッジノードのみで計算させる機能があります。 これを利用してロジスティック回帰のパフォーマンスのテストをしてみます。
# Set a local compute context
rxSetComputeContext("local")
# Run a logistic regression
system.time(
modelLocal <- rxLogit(logit_formula, data = airOnTimeDataLocal)
)
# Display a summary
summary(modelLocal)2ヶ月分のデータをエッジノード環境で実行した結果は以下のようになりました。
Elapsed computation time: 205.959 secs. user system elapsed 0.192 0.116 230.491
このelapsedが実際にかかった時間(秒数)を表しています。 今後はelapsedのみに注目していきます。
従来のRの関数では実行できませんでしたが、R Serverに実装されているRevoScaleRパッケージを用いることでエッジノード環境だけでも4分弱で実行することができました。
ワーカーノードを使ってのHadoop,Spark環境での実行
ここからパフォーマンステストの本番になります。 以下がロジスティック回帰のパフォーマンステストに利用するコードになります。
# try hadoop # Define the Hadoop compute context myHadoopCluster <- RxHadoopMR() # Set the compute context rxSetComputeContext(myHadoopCluster) # Run a logistic regression system.time( modelHadoop <- rxLogit(logit_formula, data = airOnTimeData) ) # Display a summary summary(modelHadoop) # try spark # Define the Spark compute context mySparkCluster <- RxSpark() # Set the compute context rxSetComputeContext(mySparkCluster) # Run a logistic regression system.time( modelSpark <- rxLogit(logit_formula, data = airOnTimeData) ) # Display a summary summary(modelSpark)
以下の条件を変えてみることでパフォーマンスを測りました。
- データ量 : 2ヶ月、6ヶ月、12ヶ月
- ワーカーノード数 : 1、4
- 内部ロジック : Hadoop、Spark
内部ロジックがHadoopの場合
| ワーカーノード数 | 2ヶ月 | 6ヶ月 | 12ヶ月 |
|---|---|---|---|
| 1 | 709.319秒 | 766.429秒 | 1181.775秒 |
| 4 | 668.102秒 | 648.291秒 | 639.739秒 |
内部ロジックがSparkの場合
| ワーカーノード数 | 2ヶ月 | 6ヶ月 | 12ヶ月 |
|---|---|---|---|
| 1 | 193.995秒 | 254.416秒 | 389.697秒 |
| 4 | 194.669秒 | 256.130秒 | 398.753秒 |
非常に興味深い結果となりました。
Sparkの場合はワーカーノード数を変えてもまったく処理にかかった時間は変わりませんでした。 つまり、12ヶ月1.5GB程度のデータ量ではワーカーノードを増やす必要はなさそうです。 Hadoopの場合は12ヶ月のデータ量ではコア数を増やすことによりようやく速度が向上しています。
またデータ量が少ない場合では、エッジノード環境のほうがHadoopの環境よりも速いです。 これはHadoopの実行時にオーバーヘッドがあるためと推測されます。 恐らくもっとデータを増やせばエッジノード環境を上回るでしょう。
特に内部ロジックにこだわりがないならばSparkを使うことが最も効率的であろうと思います。
R Serverへの実装
RevoScaleRパッケージについて
R Serverではマルチプロセスでの実行用パッケージとして、RevoScaleRがはじめからインストールされています。
各分析関数の引数については対応するbase関数や各パッケージの関数とほぼ同じです。
また実行結果として各関数名と同名のクラスが戻り値として帰ってきます。 クラス名は違いますが、対応するbase関数や各パッケージの関数の出力結果と同等になるように作られています。
random forestの例
RevoScaleRにおいてrandom forestは実装されておらず、代わりにdecision forestsが実装されています。 decision forestsはrandom forestをベースに実装されており、こちらを利用すればよいです。 余談ですがAzure Machine Learningもdecision forestsのみが実装されています。
# try spark # Define the Spark compute context mySparkCluster <- RxSpark() # Set the compute context rxSetComputeContext(mySparkCluster) # Run a rxDForest system.time( rfmodelSpark <- rxDForest(logit_formula, data = airOnTimeData) )
ソースコードを流用し、関数名をrxLogitからrxDForestに変更するだけで動作します。 今回はお試しで実行したため、特にパラメータチューニングは行っておりません。 また時間の関係上、データ量12ヶ月、4ワーカーノード、Sparkでの実行結果のみとなります。
> # Run a rxDForest
> system.time(
+ rfmodelSpark <- rxDForest(logit_formula, data = airOnTimeData)
+ )
user system elapsed
40.240 76.952 3710.599
R Serverを利用するに当たってのコツ
前処理を済ませておく
今回は、サンプルデータを利用しましたが実際のビジネスデータでは前処理が必須となります。 しかしR Server上では従来のRとは異なり、メモリ上でデータフレームを扱うのではなく ファイルで扱うため前処理を行うことが非常に難しいです。 難しいというよりも従来のRでの処理のように簡単に確認し難いが正しいかもしれません。
そのため、他のサービスで十分な前処理を行った後、各種統計モデルを適用していくべきかと思われます。
ローカル環境での検証を行う
サンプリングなどでスモールデータの状態とし、ローカル環境で統計モデルのパラメータの当たりをある程度つけたのち、 それをR Serverの環境に移行すべきです。
R Serverは複数のノードで構成されるため利用料金はすぐ高額になってしまいます。 起動時間を最小限とするため、ある程度ローカル環境で当たりをつけておくことは非常に有効かと思われます。
データ量の見極めを行う
今回のパフォーマンステストは12ヶ月分で1.5GB、600万レコード程度のデータを用いました。 この程度のデータであればワーカーノードを複数必要とするR Serverでなくとも、 エッジノード環境でのみ動作するR Openでも十分に動作するデータサイズでした。 そのため、データ量によって適切な環境で実行すべきです。
またAmbariもAzure HDInsight起動時に自動的に実行されるため、 各ワーカーノードに処理が分散されているかなどを確認するとよいです。 ※Ambari…Hadoopのログやアクティビティをモニタリングし、設定を変更することができるウェブツール
今後の要望
R Serverは確かにビッグデータにも対応しており、 ローカル環境では実行できないデータについても様々な統計モデリングを可能としてくれます。 しかしローカル環境では実行できないがワーカーノードを利用するまでもないデータ量の場合は、 HDInsight経由ではなく、データサイエンス仮想マシンからの運用となります。
ローカル環境、データサイエンス仮想マシン環境、Azure HDInsight R Server環境といった3種類の別個の環境を作成するのは非常に手間となってしまいます。
- 1. HDInsightからエッジノードのみの環境を作成する(これまでのデータサイエンス仮想マシン環境相当)
- 2. エッジノードのみでミドルデータでの検証を行う
- 3. Azure Portal上からヘッドノード、ZooKeeperノード、ワーカーノードの起動をする
- 4. ワーカーノードも駆使してビッグデータでの検証を行う
といったシームレスな拡張ができれば更に使いやすくなるのではと思います。
またRevoScaleR packageについては各関数の処理中のRのコンソールにログを表示するなどのオプションがあれば更に分かりやすくなると思いました。 Ambariを見たとしてもどの程度MapReduceの処理が残っているのかわかりづらく、残り時間を推測することは難しいです。
ひょっとしたら実装済みで私が浅学なだけなのかもしれません。 その場合はドキュメントの分かりやすいところに記述があればと思います。
おわりに
さて2回に渡ってR Serverを利用し、紹介させていただきました。 今後、機会があれば実務でも是非R Serverを使ってみたいと思っています。 今まではハードルが高かったR ServerがAzure HDInsightでお手軽に利用できるようになりました。 皆様も今後のビッグデータの統計モデリングの際には選択肢の1つとして考慮してみてはいかがでしょうか?
このページをシェアする: