SnowflakeでPDFからテキスト抽出してみた

目次
はじめに
データエンジニア部の大住です。
Snowflakeを使い、PDFからテキストを抽出してみました!
準備
このようなディレクトリ構成になっています。
./
├── build.sbt
├── docker-compose.yml
├── project/
│ └── plugins.sbt
├── pdf/
│ └── test.pdf
└── src/
└── main/
├── resources/
│ └── pdfbox-2.0.26.jar
└── scala/
└── pdfocr.scala
必要なライブラリ pdfocr-2.0.26.jar は https://mvnrepository.com/ からダウンロードしました。
それぞれのファイルは以下のようになっています。
build.sbt
ame := "pdfocr" version := "1.0" scalaVersion := "2.12.15" libraryDependencies ++= Seq( "org.apache.pdfbox" % "pdfbox" % "2.0.26", )
docker-compose.yml
ersion: '3'
services:
scala:
image: hseeberger/scala-sbt:11.0.12_1.5.5_2.12.15
tty: true
volumes:
- .:/work
working_dir: /workplugins.sbt
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.7")pdfocr.scala
package pdfocr
import java.io.InputStream
import org.apache.pdfbox.pdmodel.PDDocument
import org.apache.pdfbox.text.PDFTextStripper
object pdfocr {
def ocrFunc(filepath: InputStream): String = {
val pdDocument = PDDocument.load(filepath)
val pdfTextStripper = new PDFTextStripper()
val pdfText = pdfTextStripper.getText(pdDocument)
return pdfText
}
}test.pdfとしてSnowProCoreExamStudyGuideを利用しました。

pdfを配置するためのステージを作成します
create or replace stage pdf_stage
directory = (enable=true auto_refresh=true)
encryption = (type = 'SNOWFLAKE_SSE')
;directory = (enable=true)とすることで非構造化データを扱えるようになります。
pdfをステージにputしておきます。コマンドは普通のputコマンドと変わりません。
$ snowsql -a <account> -u <user> -d <database> -s <schema> -r <role> -q "put file://./pdf/test.pdf @pdf_stage auto_compress=FALSE"
ステージに配置したpdfは
・スコープURL
・ファイルURL
・事前署名済みURL
などのURLからアクセスできます。
PDFからテキストを抽出するjarファイルを作成する
dockerコンテナを起動します。
$ docker-compose up
起動したコンテナに入ります。
$ docker-compose exec scala bash
pdfocr.scala からjarファイルを作成します。
$ sbt “assembly”
これで target/scala-2.12 の下に pdfocr-assembly-1.0.jar が作成されます。
SnowflakeでUDFを作成する
作成したjarファイルを配置するためのステージを作成します。
create or replace stage resources_stage;
作成したjarファイルをputします。
$ snowsql -a <account> -u <user> -d <database> -s <schema> -r <role> -q "put file://./target/scala-2.12/pdfocr-assembly-1.0.jar @resources_stage auto_compress=FALSE"
ステージをrefreshして、jarファイルを使ったudfを作成します。
alter stage resources_stage refresh;
create or replace function ocr_function(filepath string)
returns string
language java
imports = ('@resources_stage/pdfocr-assembly-1.0.jar')
handler = 'pdfocr.pdfocr.ocrFunc'
;PDFからテキストを抽出する
作成したudfを使ってpdf_stage上のpdfからテキストを抽出します。
select
ocr_function(build_stage_file_url('@pdf_stage', relative_path)) as text
from
directory(@pdf_stage)
;結果
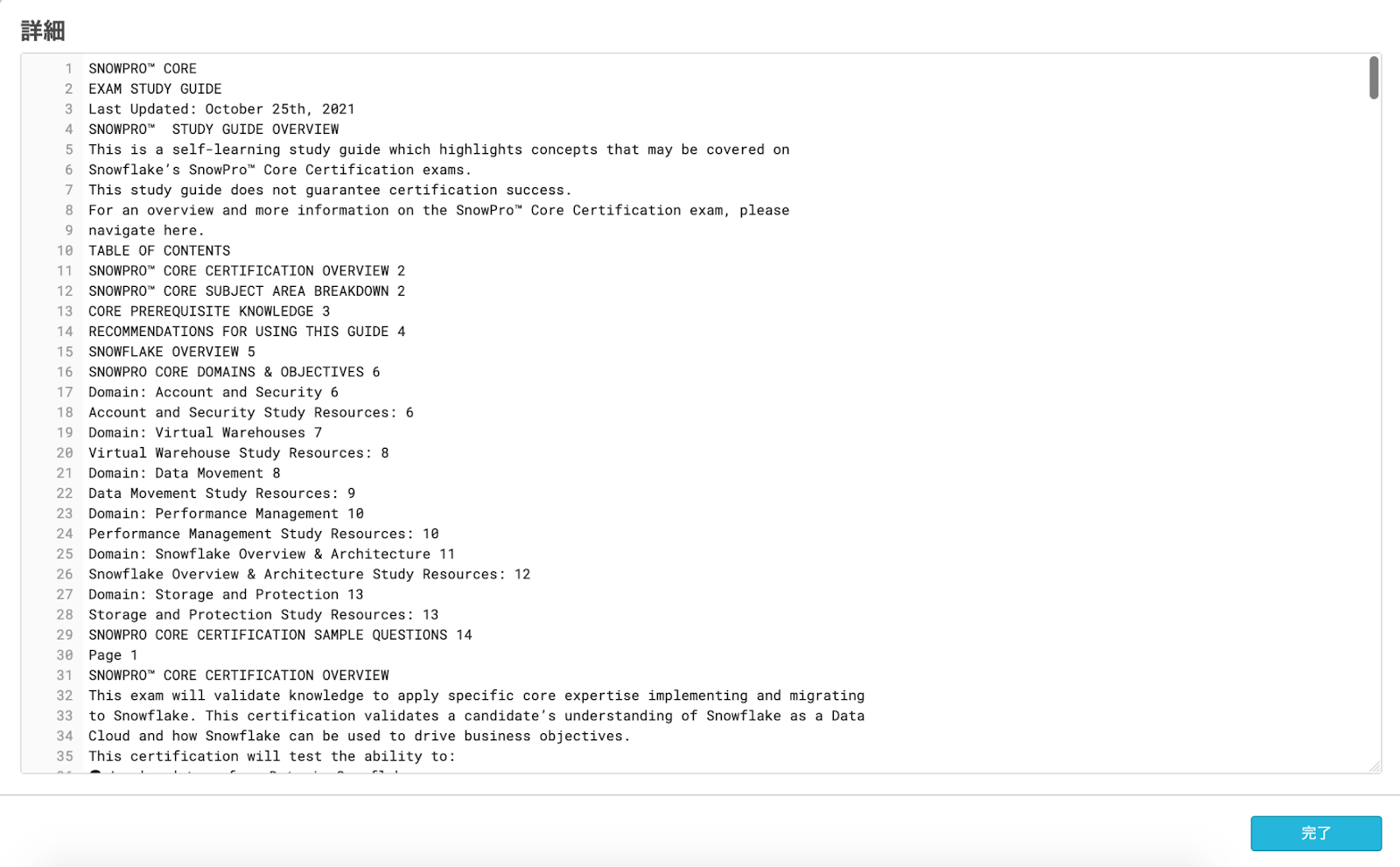
pdfからテキストの抽出ができました!
自動でテキストを抽出する
ステージにファイルが追加されるたびに自動でテキストの抽出を行い、抽出したテキストをテーブルに保存するようにしたいと思います。
まず、ステージの変更を追跡するためのストリームと、抽出したテキストを格納するテーブルを作成します。
create or replace stream pdf_stream on stage pdf_stage; create or replace table text_table(text varchar, filename varchar);
ストリームから追加されたファイルを確認し、テキストを抽出してテーブルに保存するタスクを作成します。
create or replace task ocr_task
warehouse = <warehouse>
schedule = '5 minute'
as
insert into text_table(text, filename)
select
ocr_function('@pdf_stage/' || RELATIVE_PATH)
, RELATIVE_PATH
from
pdf_stream
where
metadata$action = 'INSERT'
;実際にpdfをステージに追加してタスクを実行してみます。
$ snowsql -a <account> -u <user> -d <database> -s <schema> -r <role> -q "put file://./pdf/test2.pdf @pdf_stage auto_compress=FALSE"
test2.pdfとしてSnowflake Key Concepts LEVEL UPを利用しました。

結果を確認します。
execute task ocr_task; select * from text_table;
結果

できました!ちゃんと抽出されたテキストがテーブルに入っています!
おわりに
Snowflakeを使ってpdfからテキスト抽出を行いました。Snowflakeについてお困りごとがあればDATUM STUDIOまでお気軽にお問い合わせください。
このページをシェアする: