Snowflake Summit 2026 最速レポート Day2
【セッション解説】Snowflakeにおけるオントロジー、AIエージェントに自社のビジネスを理解させる

こんにちは、DATUM STUDIOの鈴木です。
サンフランシスコで開催のSnowflake Summit 2026に参加しています。本記事は、2日目に聴講したセッションの中から、特に印象に残った「Ontology on Snowflake: From Unified Data to AI-Powered Intelligence」(AI309)について解説します。
目次
- 1 なぜ「オントロジー」なのか、データを“管理”する時代から、現実を“モデリング”する時代へ
- 2 オントロジーとナレッジグラフは別物 -「憲法」と「地図」
- 3 5層からなる「Ontology-First」なインテリジェンス・スタック(AI活用基盤)の全体像
- 4 Layer 1|事実の置き場 – 普遍的な物理モデル
- 5 Layer 2|意味はメタデータで宣言する
- 6 Layer 3|コンパイラが意味をビューに翻訳する
- 7 Layer 4|同じ意味を3つの視点で見る
- 8 Layer 5|Cortex Agent が指揮する – Intelligent Orchestration
- 9 すべてを自動化するOntology-stack-builder(公開 Cortex Code向け Skills)
- 10 AI-Driven Insightsにおけるオントロジーの役割
- 11 まとめ
なぜ「オントロジー」なのか、データを“管理”する時代から、現実を“モデリング”する時代へ
セッションは、多くの現場で抱えているであろう問題提起から始まりました。登壇したSnowflake社のTianxia Jia氏は冒頭で次のように問いかけました。
「自信満々に、しかし間違った答えを返すエージェントを作ったことはないでしょうか?」
その原因として示されていたのは、とてもシンプルな構図です。企業のデータは、テーブル・外部キー・いつの間にか意図せず修正された列名として保存されています。
一方で、現実のビジネスはそのようには動いていません。そこには人・チーム・契約といったオブジェクトがあり、それぞれが特定の関係で結ばれています。「ある人はあるチームに所属し、契約が両者を結ぶ」。これは「スキーマ」ではなく「現実(reality)」だ、という整理でした。
この「事実(Facts)」と「意味(meaning)」の分断こそが、ロジックの重複やハルシネーションを生む。AI時代に企業が競うのは「より多くのデータを貯めているか」ではなく、「自社ビジネスにおける実際の仕組みを、どれだけ理解しているか」であると述べました。この一言は、データ実務に携わる身として、非常に刺さりました。
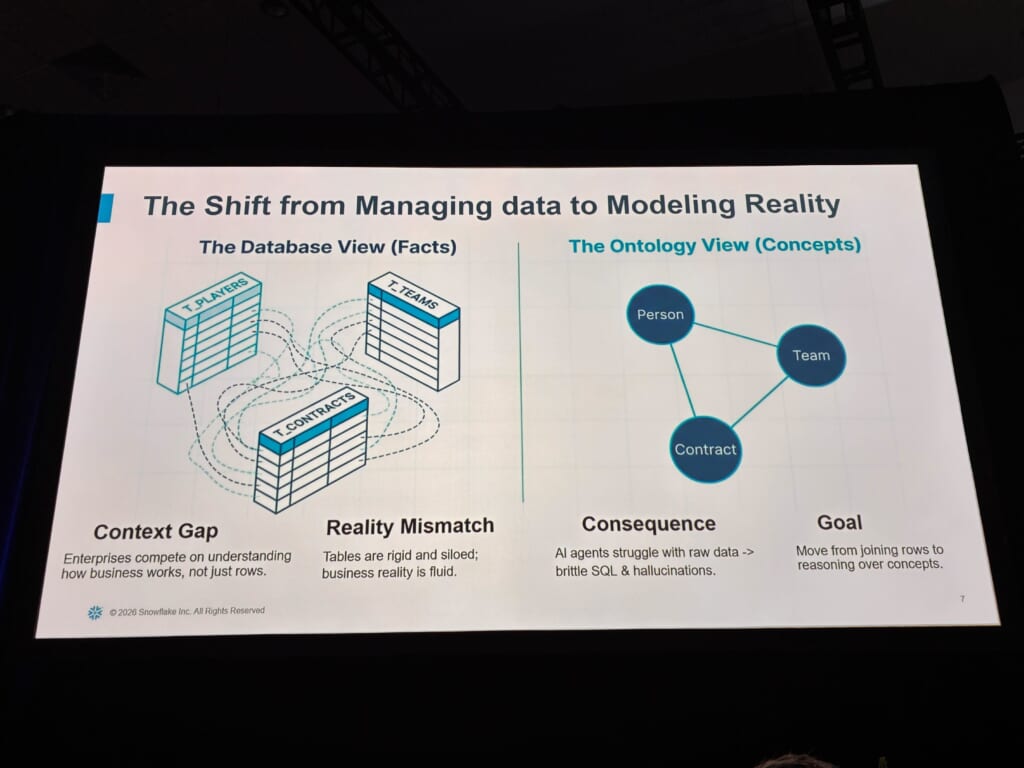
セッションのゴールは、この一文に集約されていました。
「行をJOINする」から「概念(concepts)を推論する」へ。
これが本セッションの全体をまとめるテーマです。
オントロジーとナレッジグラフは別物 -「憲法」と「地図」
本題に入る前に、登壇者がまず解説していたのが、この領域で起こりがちな混同でした。オントロジー(ontology)とナレッジグラフ(knowledge graph)は同じものではない、という主張の説明には、次の2つの比喩が使われていました。
- ・オントロジー = 憲法(The Constitution)
「人は組織に所属しうる」「playerはpersonの一種」「clubはorganizationの一種」といった、何が存在してよく、どう関係しうるか、という抽象的なルール。一度定義すれば滅多に変わることはありません。 - ・ナレッジグラフ = 地図(The Map)
その憲法のもとで、実際に成立している具体的事実。「MbappéがReal Madridでプレーしている」移籍のたびに変わる、といった流動的なインスタンスの集合です。

個人的に印象的だったのは「オントロジーは、“関係が何であり、許されるか”を定義し、ナレッジグラフは、“実際に存在する関係”を実体化(materialize)する」という主張でした。両方必要だが、分離して保つことで、安定性(憲法はゆっくり進化)と柔軟性(地図は頻繁に変わる)を同時に得られる、という考え方でした。この分離が後述する5層アーキテクチャの設計思想そのものになっています。
5層からなる「Ontology-First」なインテリジェンス・スタック(AI活用基盤)の全体像
では、これをどう作るのか。紹介されていたのは、すべてSnowflakeネイティブで完結する5層アーキテクチャでした。下の3層がデータ、上の2層が知性を担う構成です。
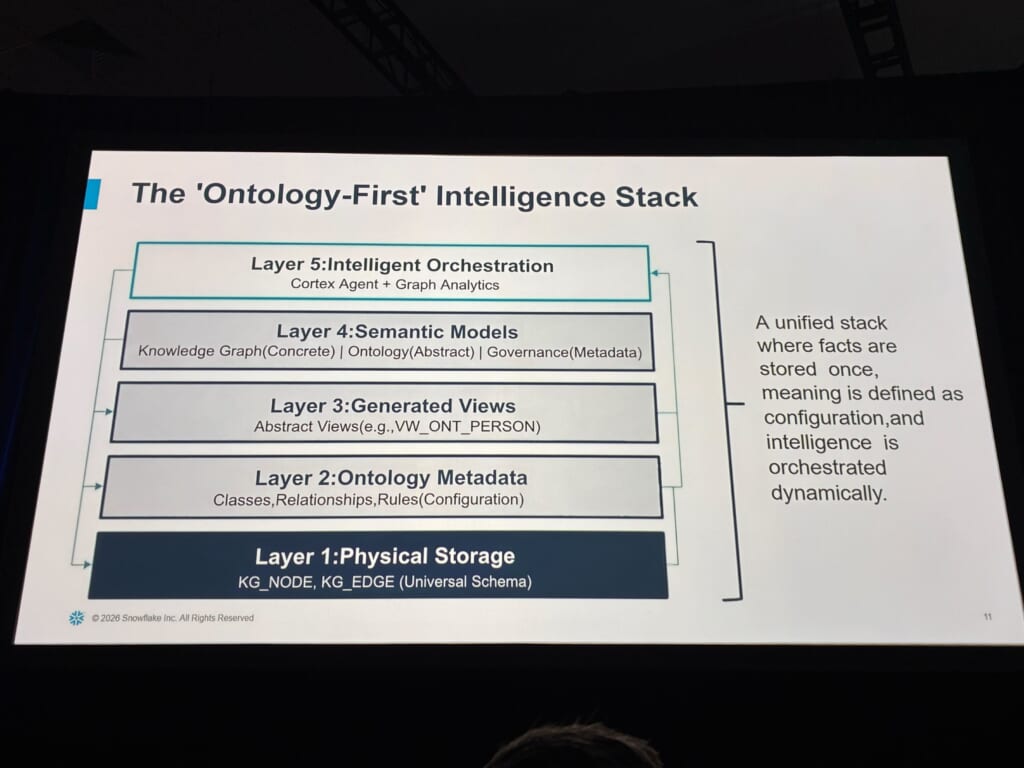
設計の哲学として強調されていたのが「事実は一度だけ保存、意味は設定として宣言、知性は実行時に動的に編成する」という3点でした。
クエリがどう流れるか、の図も示され、このアーキテクチャの賢さを端的に表していました。
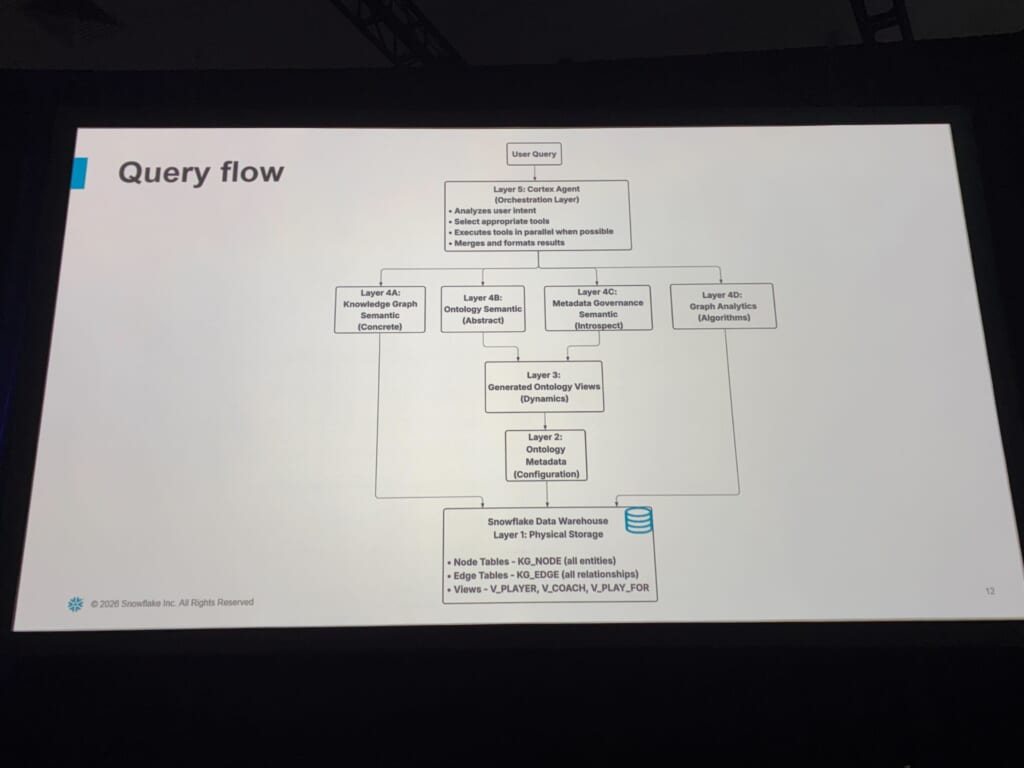
最上位のLayer 5であるCortex Agentは、自分で答えようとはしません。代わりに「これは、どの種類の問いか?」を判定し、最適な層・ツールへルーティングする。ユーザーはルーティングを一切意識せず、ただ問うだけで良い、という裏側の複雑さを隠す発想がオントロジー駆動アーキテクチャの肝だと感じました。
では、続いてこの5層を一段ずつ見ていきたいと思います。
Layer 1|事実の置き場 – 普遍的な物理モデル
最下層は非常にシンプルで、テーブルは2つだけでした。存在するものすべてを格納するKG_NODE(ノード)と、もの同士の接続を格納するKG_EDGE(エッジ)です。プロパティはVARIANT列で持たせます。

設計の肝は、事実(安定したストレージ)と意味(進化するメタデータ)を分離することであると説明されていました。
新しいエンティティ型、たとえばreferee(審判)を追加したくなっても、新テーブルもマイグレーションも不要で、NODE_TYPE = ‘referee’のノードをINSERTするだけ。スキーマが増殖しない、という割り切りは、なるほどと思いました。事実は安定させ、意味はその上で進化させていく、というわけです。
Layer 2|意味はメタデータで宣言する
意味の層は、SQLコードに埋め込むのではなく、メタデータテーブルに宣言的に定義します。ここでは、コードではなく「宣言」を書く、という点が強調されていました。

上図は、オブジェクト指向プログラミングの継承ツリーをデータに対して、構築しているイメージです。Thing → Person → Player という階層を作り「playerだけがclubに対してPlays_Forできる」という制約を宣言する。これが「何が許されるか」を定義する憲法にあたります。
嬉しいのは、ビジネスに新しいロールや関係が生まれても、対応がINSERT文1つで済む点だと紹介されていたことです。スキーマの書き換えやパイプラインの再構築が不要で、メタデータを変えればシステムが適応する、という設計です。
Layer 3|コンパイラが意味をビューに翻訳する
個人的にこのセッションで最も興味深かったのが、Layer 3でした。
Layer 2のメタデータを読み取り、標準的なSnowflakeビューを自動生成するコンパイラが存在していました(実体はストアドプロシージャ)。
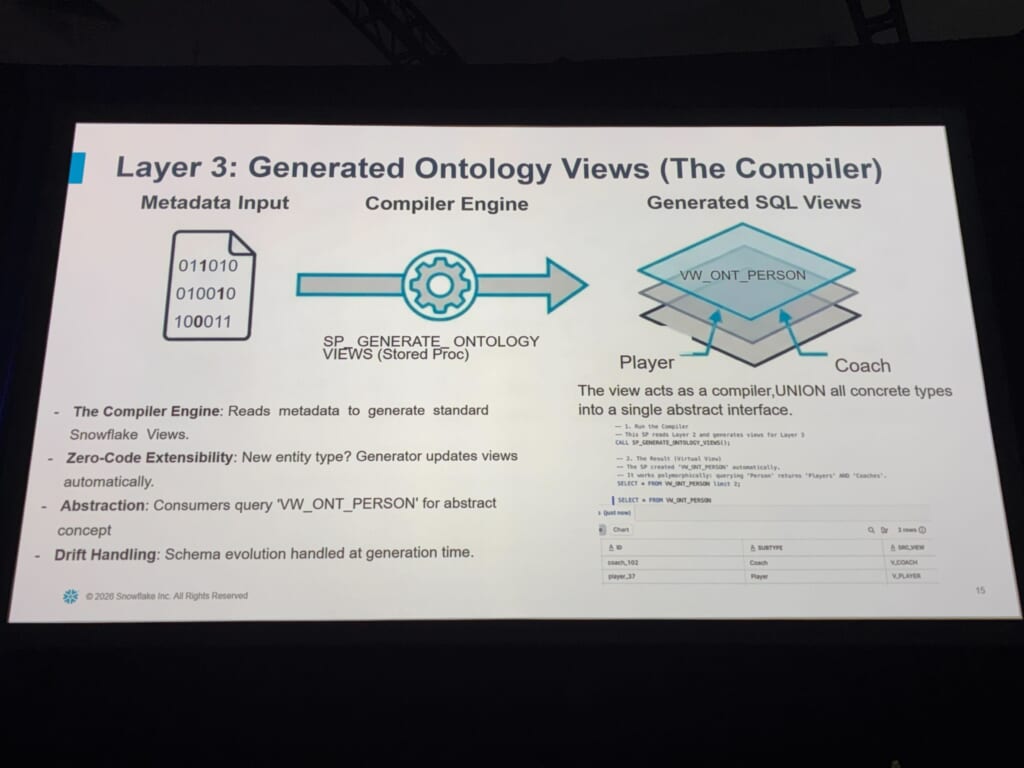
このコンパイラは「personにはplayerとcoachという2つのサブタイプがある」と発見し、それらをUNIONした抽象ビュー VW_ONT_PERSONを自動生成します。
このビュー自体がコンパイラのように振る舞い、すべての具体型を単一の抽象インターフェースに束ねる、という説明でした。
設計図から建物を建てるように、メタデータ(設計図)からビュー(建物)が生成される。来月personに新しいサブタイプが増えても、コンパイラを再実行すればビューが拡張され、VW_ONT_PERSONを使う既存クエリは、ダウンストリーム側のコード変更ゼロでそのまま動く。つまり、スキーマの進化(drift)を生成時に吸収する、というアイデアは、実務においても効果的だと感じました。
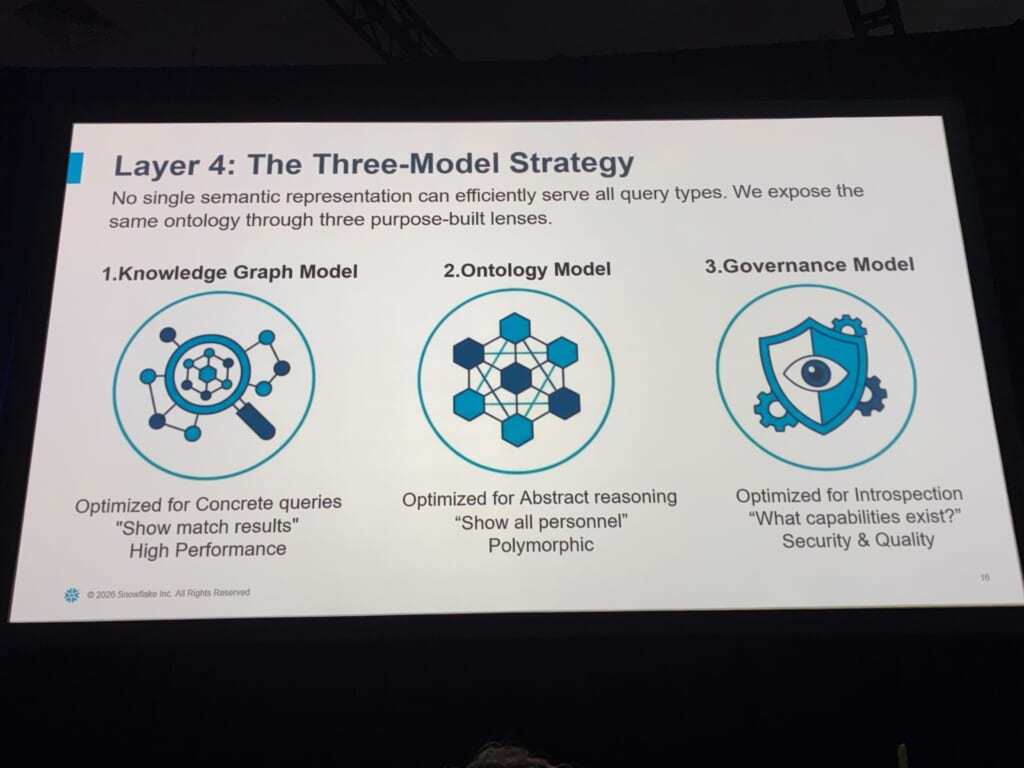
Layer 4|同じ意味を3つの視点で見る
「単一のセマンティック表現で、あらゆる種類のクエリを効率よく賄おうとしたが、うまくいかなかった」登壇者がそう率直に語っていたのが印象的でした。その反省から採られたのが、同じオントロジーを3つの目的特化レンズで露出させる戦略とのことです。
| 1.Knowledge Graph Model (具体) | 速度・具体性・属性の豊富さに最適化。「試合結果を見せて」のような、速く・具体的な問いに向いています。 |
| 2.Ontology Model (抽象) | 多態的(polymorphic)な推論に最適化。「全人員を見せて」のような、抽象的な問いに向いていて、AIの推論が活きる層とされていました。 |
| 3.Governance Model (メタデータ) | 内省(introspection)に最適化。「どんな型・関係が存在し、誰がアクセスできるか」を、システム自身で記述します。 |
この戦略の威力が、サッカーの例示で一気に腑に落ちました。問い方が一語違うだけで、返ってくる答えも変わるのです。
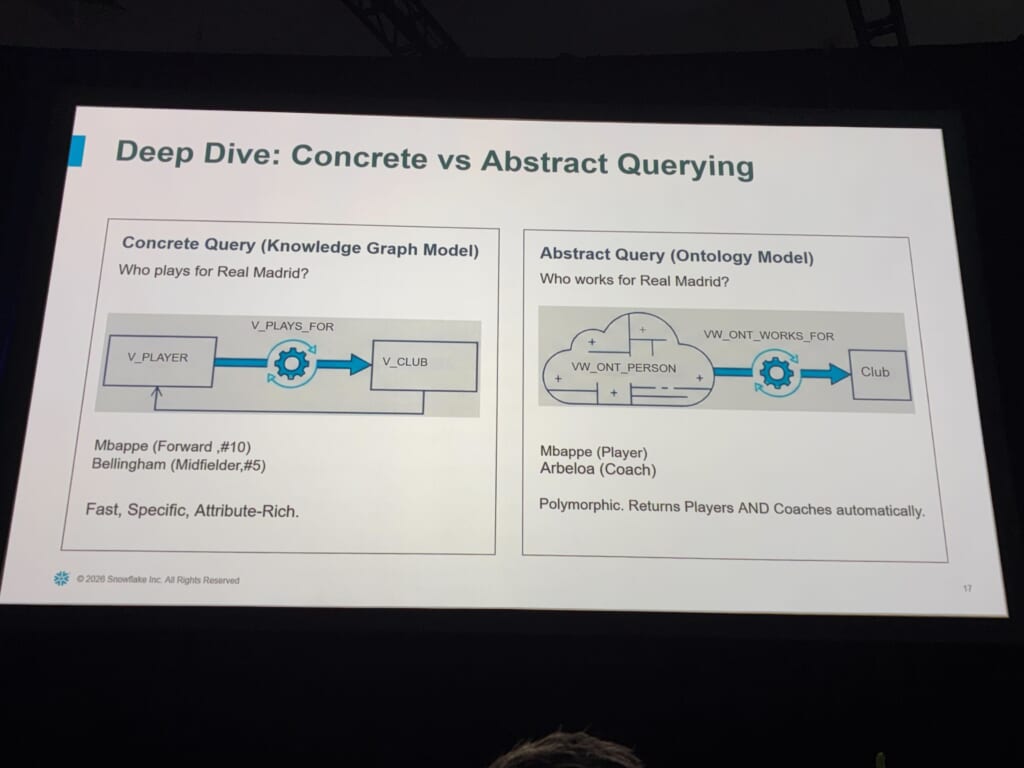
「Real Madridでプレーするのは誰か」は、playerという具体型を高速に返します。一方「Real Madridで働くのは誰か」は、ontologyを経由することで型境界を自動的に越え、playerとcoachの両方を返す。誰も「coachテーブルも見ろ」とは書いていないのに、オントロジーが「playerもcoachもorganizationで働くpersonだ」と知っているから自動でそうなる、この点がこのアーキテクチャの魅力的なポイントだと感じました。
Layer 5|Cortex Agent が指揮する – Intelligent Orchestration
最上層では、Cortex Agentがオーケストレーター(指揮者)として振る舞います。何でも自分でこなすのではなく、専門特化したツール群を「いつ・どれを使うか」のみを判断して呼び出す、という整理でした。
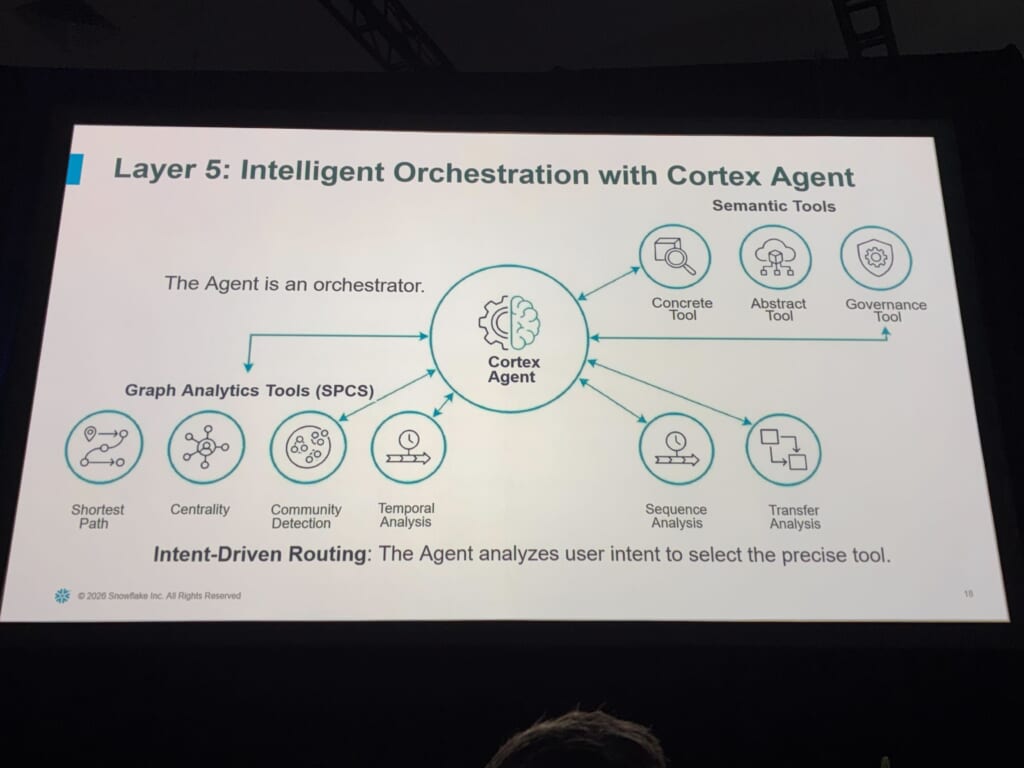
「ここで誰が働くか?」なら抽象モデルを、「2エンティティ間の最短経路は?」ならグラフ解析を、「どんな型が存在するか?」ならガバナンスツールを呼ぶ。時には複数ツールを並列で実行し、結果を1つの一貫した答えに統合する、という流れでした。グラフ解析ツール群がSPCS(Snowpark Container Services)上で動く点も、Snowflake内で完結する設計を象徴していて興味深かったです。
登壇者はこれを「協調による知性(intelligence through coordination)」と表現していました。単一モデルにおいてはすべてはできないが、専門ツールを統べる指揮者ならできる、という発想です。
すべてを自動化するOntology-stack-builder(公開 Cortex Code向け Skills)
上記で5層アーキテクチャを解説しましたが、手作業では重すぎると、登壇者自身も言及しています。
このスタックの構築には、データモデリング / オントロジー設計 / Snowflake SQL / セマンティックモデル作成 / エージェント編成という複数領域の専門性が要る、すべてを一人で担うことができるチームは多くない、と説明していました。
その回答として紹介されたのが、Ontology-stack-builderです。SnowflakeのCortex Code(通称 CoCo)用のSkills(※)で、自分のテーブルとビジネス上の問いを渡すと、対話的・ゲート式のワークフローで5層スタック一式を生成してくれる、というものでした。
※ Skillsとは、CoCoが従う構造化された手順書(SKILL.md)であり、反復可能なパターンをワークフローとして符号化しつつ、要所要所で人間の判断を残す仕組みです。

デモでは、金融ドメインのオントロジー(Market Participant / Financial Instrument / Security / Exchange / Company / Sector / Classificationなど、8クラス・8リレーション)を題材に、12 views・27 tables・1 procedureを生成する様子が示されていました。
従来は、手書きSQLで数週間〜数ヶ月かかっていた作業が、複雑性次第ではありますが1セッション(約1時間)に短縮される、とのことです。
なお、Ontology-stack-builderはSnowflake-Labs配下で公開されている誰でも導入可能なスキルであり、以下のリンクからその詳細を参照することが可能です。
GitHub: https://github.com/Snowflake-Labs/coco-skills/tree/main/skills/ontology-stack-builder
AI-Driven Insightsにおけるオントロジーの役割
技術寄りの話が続いたので、最後にビジネスの言葉での整理も紹介されていました。「Q3の売上をどう改善できるか?」とエージェントに問うとします。オントロジー層がなければ、エージェントは生のテーブルをスキャンして当てずっぽうを返すだけですが、オントロジー層があれば、エージェントはまず意味のグラフをたどり、適切なCustomer Personaを見つけ、関連するMarket Trendを特定し、Product Categoryに接続して、ビジネスの現実に根ざした回答を組み立てる、という対比でした。
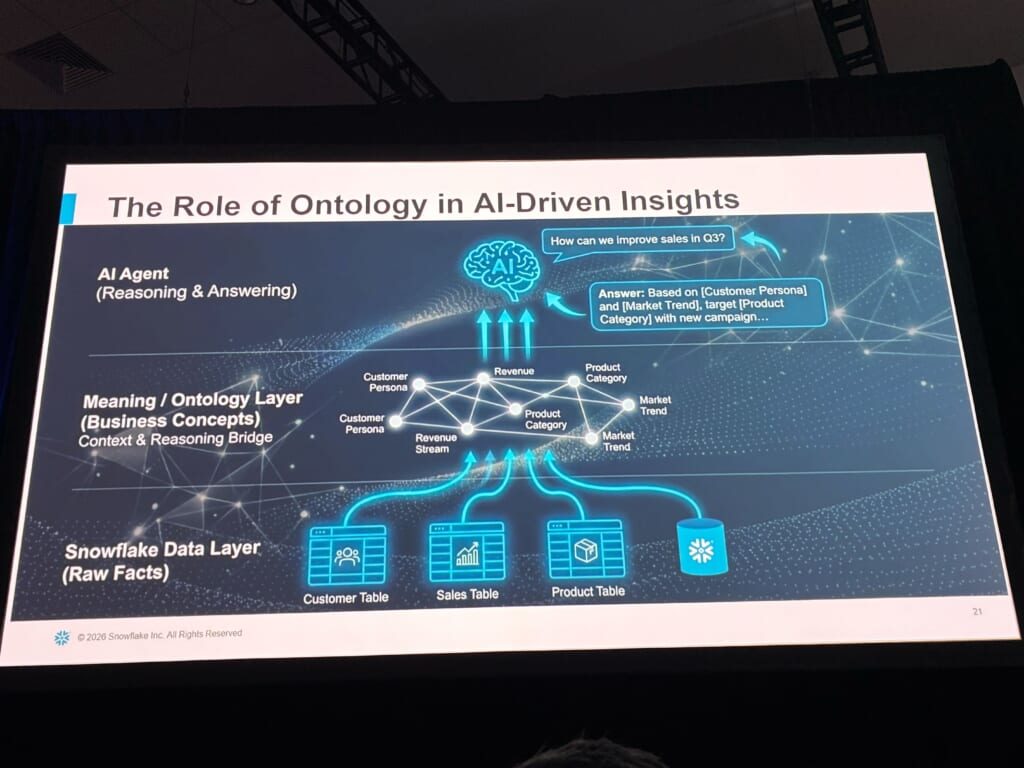
下層のデータが事実(Facts)を、中層のオントロジーが意味(meaning)を、上層のエージェントが知性(intelligence)を与える。生データを「AIが推論できる何か」に変える欠けたレンガ(missing brick)がオントロジーなのだ、という締めくくりは、今回のテーマを一枚で表していて分かりやすかったです。
まとめ
セッションの結びでは、改めて次の3つの重要なポイントが挙げられていました。
- 1.意味を明示する
事実は一度だけ保存し、意味はメタデータとして定義し、残りはシステムに生成させる。 - 2.目的特化の視点を使う
速度のためのknowledge graph、推論のためのontology、信頼のためのgovernanceを、用途で使い分ける。 - 3.エージェントを意図駆動ルーティングで動かす
ハードコードされた経路は持たない。
正直「オントロジー」と聞くと難しそうで身構えていたのですが、「事実(テーブル)」と「意味(概念のつながり)」を分けて持つという発想は、素直で腹落ちしました。Semantic View / Semantic Modelでテーブルの意味をCortex Analystに教えることはありますが、今回のオントロジーは、その一段上に「person → player / coach のような概念の階層や関係」を乗せるイメージで、置き換えではなく“上に積む”ものだと理解しました(セッションでもベースのセマンティックビューの上に、オントロジー層を作る流れでした)。
とはいえ、現場目線では「自分たちのデータで、どこから手をつけるか?」が正直な疑問です。まずは、ごく狭い範囲で概念の階層を足し、Cortex AnalystやCortex Agentsの答えがどう変わるか、を小さく試すくらいの距離感で始めたい、というのが今回の持ち帰りでした。
このページをシェアする: