Beyond the Warehouse:AIエージェント時代を見据えた BigQuery のアーキテクチャ進化

はじめに
今回は、 Google Cloud Next 2026 初日に開催されたセッション「Beyond the warehouse: Architecting BigQuery for the future of analytics」の内容をレポートします。

今年の Google Cloud Next では、「Agentic」をキーワードに掲げられています。AIエージェント時代を前提として語られていることが印象深く、 BigQuery についても単なるデータウェアハウスにとどまらず、AI エージェント時代に適応するために、どのように進化させていくべきかが語られていました。
ここで語られる「AIエージェント時代」とは、人間が1日に数十件程度のSQLクエリを実行する従来の世界観を超えて、AIエージェントが検索・集計・推論・可視化を繰り返し実行し、1分あたり万単位までクエリ実行することを前提としたものです。
このような環境では、データ基盤側にも低レイテンシ、高い同時実行性、運用負荷を抑える自動最適化が求められる時代とされていました。
BigQuery は「ペタバイト級のETL処理」から「コンマ秒レベルの対応時間が求められるダッシュボードからの読み取り処理」までを支える幅広い役割を担っています。ストレージとコンピュートが分離され、予測の難しいマルチモーダルなワークロードに対しても自律的なクエリ最適化を行う点が特徴です。
さらに、Fluid Scalingによるコスト最適化の仕組みや、大規模処理から小規模処理まで対応する自律最適化によるパフォーマンス改善などが語られています。
なぜアーキテクチャか
BigQuery の土台にあるのは、ストレージとコンピュートを分離した設計です。
BigQuery は petabyte-scale の分析を前提に、Borg、Colossus、Jupiter、Dremel といった Google Cloud 独自のインフラ上で構築されています。
従来のBIやバッチ処理だけであれば、この設計は「大規模分析に強い」という説明で十分でした。
しかし、AIエージェントが短いクエリや複雑な探索を高頻度に発行するようになると、重要なのは単なるスケールだけではありません。
負荷の揺らぎに追随できること、短い問い合わせでもオーバーヘッドを抑えられること、そして人手でチューニングしなくても性能が発揮できることが、より重要になります。
特に、「build for tomorrow’s scale, speed, and innovation」と掲げられていることからも、具体的な数字を踏まえて BigQuery の目指す未来が見えて、開発者の覚悟が感じられました。

Fluid Scaling
BigQuery の料金体系には、大きく分けてオンデマンドとスロットベースがあります。オンデマンドは処理したデータ量(TiB)で課金され、スロットベースでは消費スロット時間で課金されます。
ここでいうスロットは、BigQuery がクエリ実行に使用する仮想的な計算資源です。
これに対して Fluid scaling がGA機能として紹介されました。Fluid Scaling は、既存のスロットベースの延長線上にあり、より変動の大きいワークロードに向けて設計されています。課金粒度が従来の分単位から秒単位まで細分化されることで実際の利用がない余分な課金を抑制できる点に加え、最大34%のコスト削減が実現できるとされています。
AIエージェントを前提とした運用の中でも、細かな処理の実行回数が増加するケースも多いと考えられるため、非常に効果的なアップデートになると期待しています。
役割の異なる4 つの「自律的最適化」
今回のセッションで登場した Enhanced Vectorization、Short Query Optimizations、History-Based Optimizations、CMETA は、いずれも単純に「何倍速くなる」という類のものではなく、それぞれ効果を発揮する場面が異なります。
・Enhanced Vectorization
主に、大規模スキャンやフィルタ、集計のような列指向処理に効果を発揮します。Capacitor の特殊エンコーディングを活用した encoded data 上での filter evaluation、エンコーディングの query plan への伝播、さらに deterministic function や constant expression に対する expression folding のように、SIMD を利用するだけではなく BigQuery のストレージ形式と実行計画の双方にまたがって、できる限り「エンコードされたまま」処理を進める点がポイントです。
・Short Query Optimizations
BIツールやアプリケーションから発行される、比較的小規模で短いクエリに効果があります。 BigQuery は通常、複数ステージとシャッフルを伴う分散計画で実行されますが、Short Query Optimizations は条件を満たすクエリを single stage に寄せ、シャッフル層をスキップすることでレイテンシと slot consumption を下げます。 Google Cloud の公開ブログでは、内部テストで2倍〜8倍の高速化、平均9倍の slot-seconds 削減が報告されています。あえて stageを絞ることでパフォーマンスを高める点がポイントです。
・History-Based Optimizations(HBO)
類似クエリの過去の実行結果を参照し、追加の最適化を適用する仕組みです。繰り返し実行されるクエリに対して効果を発揮します。過去実績に基づいてオプティマイザの判断を補強し、効果が十分でない最適化はrevoke(無効化)され、将来の実行では使用されません。効果が見込める場合にのみ適用される仕組みとなっています。
・CMETA(Column Metadata Index)
超大規模テーブルや低レイテンシBIに効くメタデータ側の最適化です。ドキュメントによると、 BigQuery が1GiBを超えるテーブルに対して各種メタデータを自動的にインデックスして、クエリ最適化に利用します。CMETA は、 BigQuery 自身が列メタデータを継続的に把握してスキャン判断を高度化する技術であると言えます。
このように役割分担は明確であり、 BigQuery が広範囲の利用ケースに対応するデータウェアハウスであることをあらためて実感させられます。
全体での性能改善について
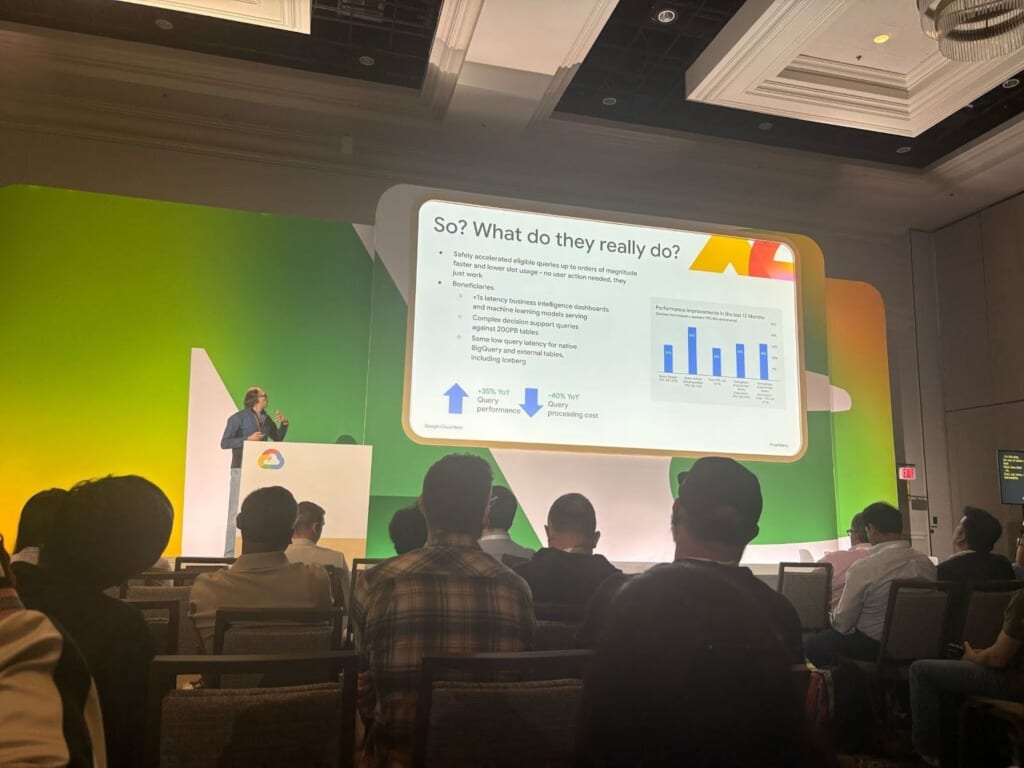
BigQuery 全体として、YoY(Year-over-Year)でクエリパフォーマンスは35%の上昇、クエリ処理コストは-40%とされており、我々ユーザーとしても、瞬時に描画されるBIの裏側から大規模なパイプライン処理まで、幅広い領域でその効果が期待できます。
まとめ
今回のセッションの主軸は、BigQuery が単に高速な大規模データウェアハウスを目指しているのではなく、AIエージェントに耐えうる分析基盤を目指していると感じました。
その中核にあるアーキテクチャの改善は、結果としてAIエージェントだけでなく、日々の業務や人による分析・集計利用にも好影響をもたらし、AI エージェントの活用促進にもつながると考えられます。
データウェアハウスを運用する中で、過去のパフォーマンスやコストのモニタリングを見直すことで、皆さんの環境においても本セッションで語られたような BigQuery の進化による恩恵を実感できる場面があるかもしれません。
また、今後クエリ作成やAIエージェントを導入する際の設計においても、コストとパフォーマンスを最適化するためのヒントを得られる内容であったと言えます。今後の BigQuery の活用の一助となれば幸いです。
※Google Cloud および Google Cloud 製品・サービス名称は Google LLC の商標です。
(本記事の内容は、2026年4月時点の情報に基づいています)
このページをシェアする: